User Manual
We provide a step-by-step user manual here. The user needs to install python3.6 or greater.
Open cli folder and use extract_tiles_from_wsi_openslide.py to divide WSI into smaller tiles. Here is a basic usage tutorial.
E:\Study\Research\QA\GithubQA\QuickAnnotator\cli>python extract_tiles_from_wsi_openslide.py --help
usage: extract_tiles_from_wsi_openslide.py [-h] [-p PATCHSIZE]
[-l OPENSLIDELEVEL] [-o OUTDIR]
[-b]
[input_pattern [input_pattern ...]]
Convert image and mask into non-overlapping patches
positional arguments:
input_pattern Input filename pattern (try: *.png), or txt file
containing list of files
optional arguments:
-h, --help show this help message and exit
-p PATCHSIZE, --patchsize PATCHSIZE
Patchsize, default 256
-l OPENSLIDELEVEL, --openslidelevel OPENSLIDELEVEL
openslide level to use
-o OUTDIR, --outdir OUTDIR
Target output directory
-b, --bgremoved Don't save patches which are considered background,
useful for TMAs
Note: We provide a small divided colon tubules dataset, which could be downloaded by Tubule Samples.
cd quick_annotator
python QA.py
http://localhost:5555
The user could change the port number in the config.ini file.
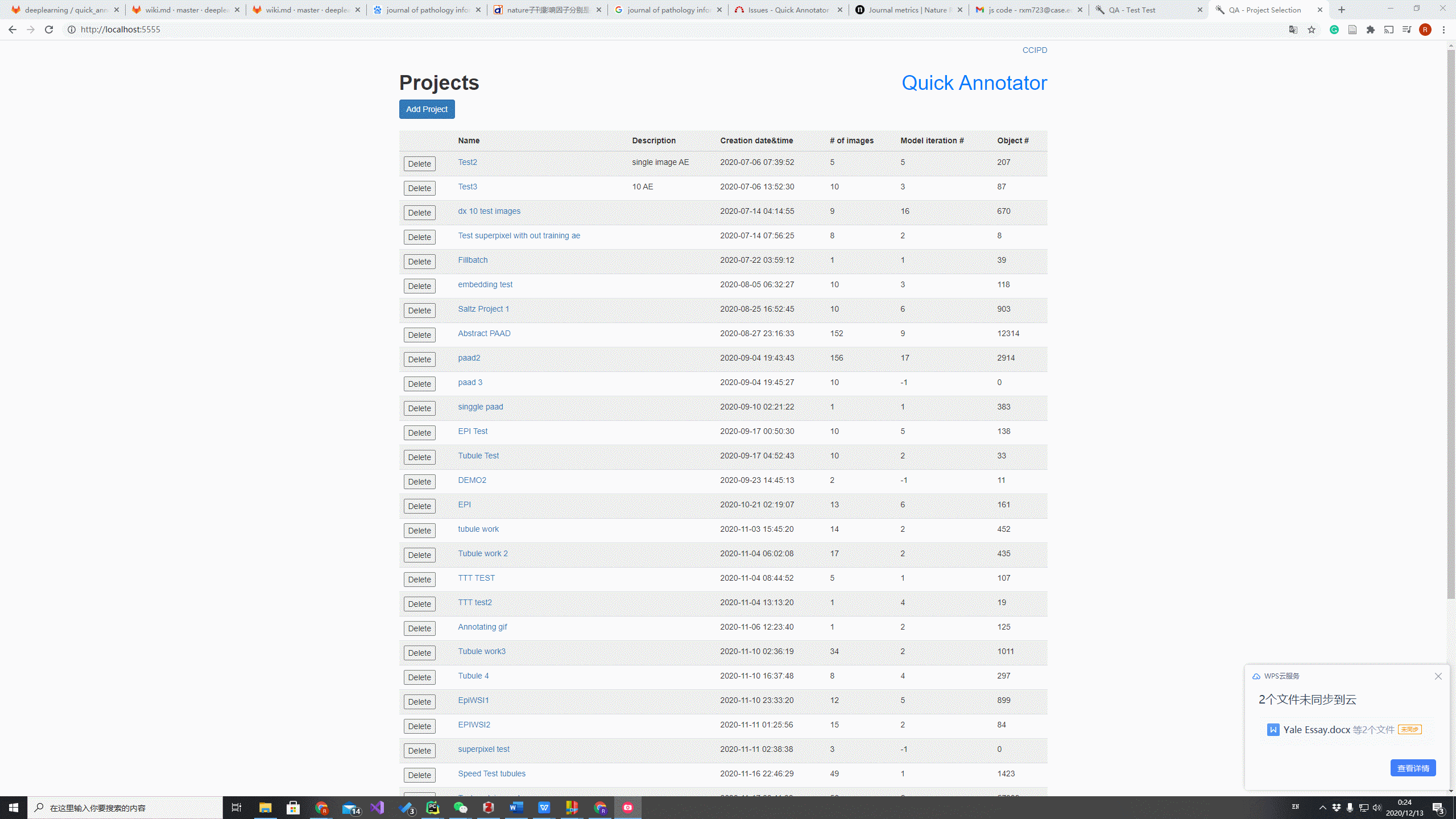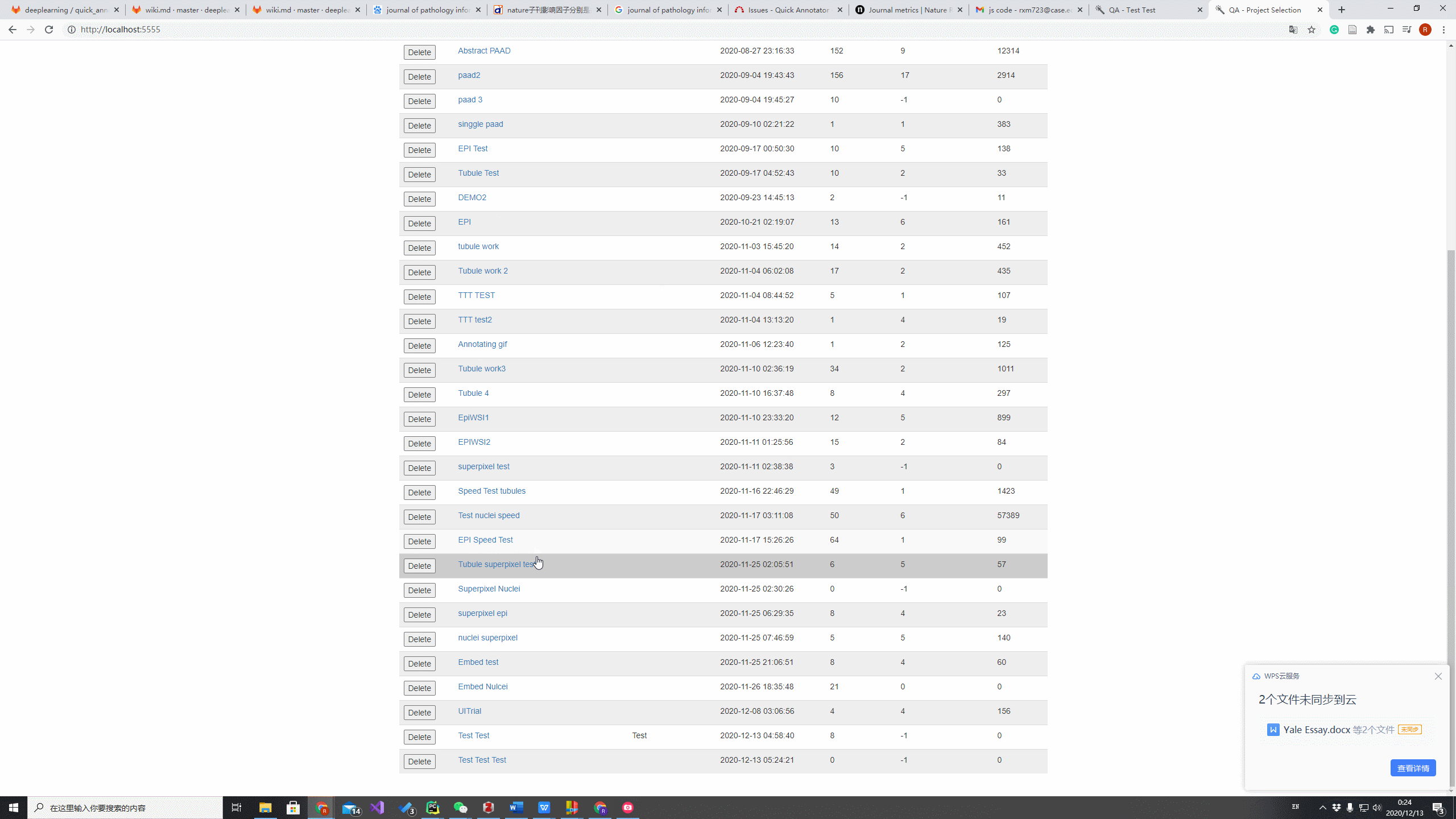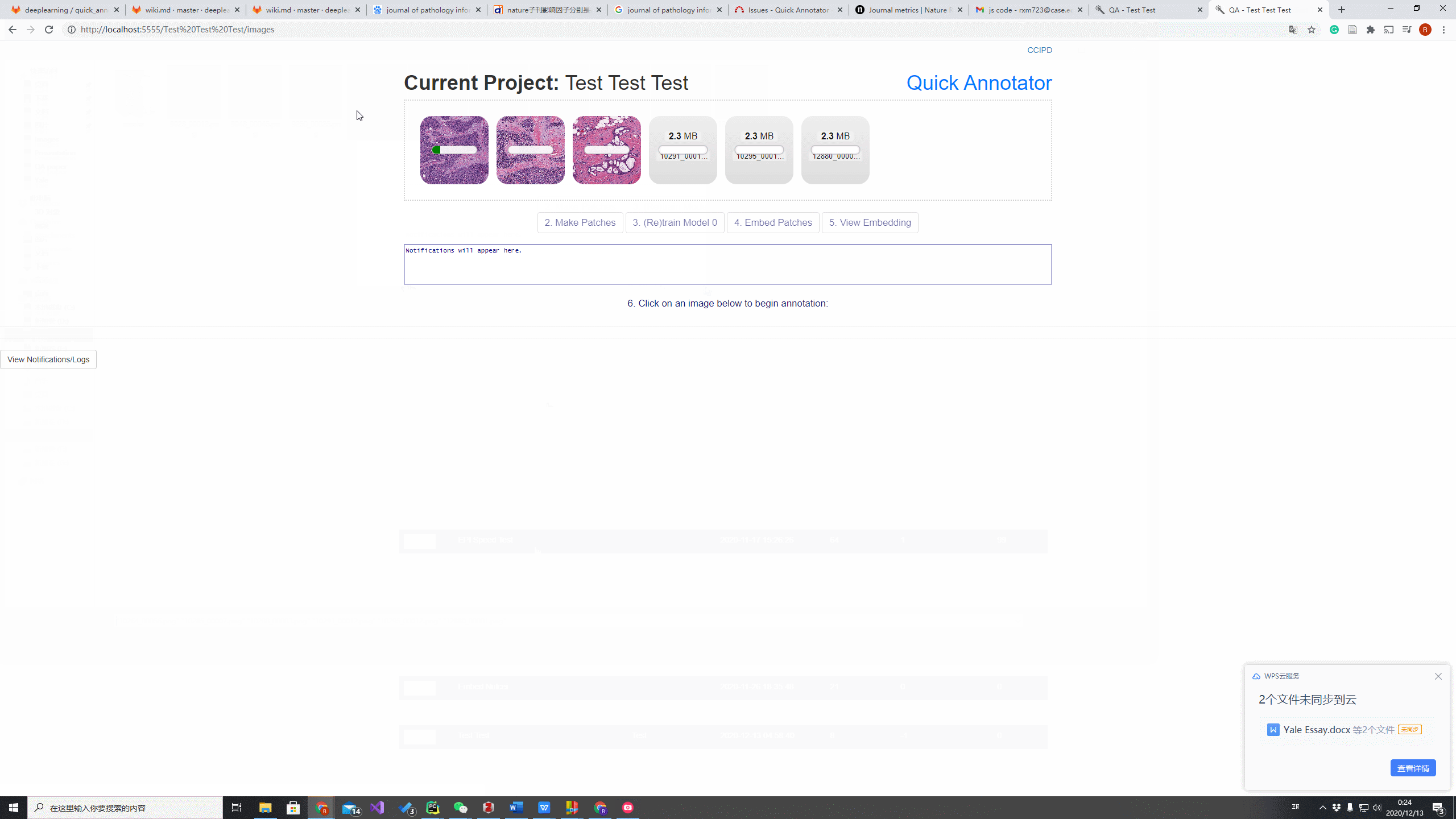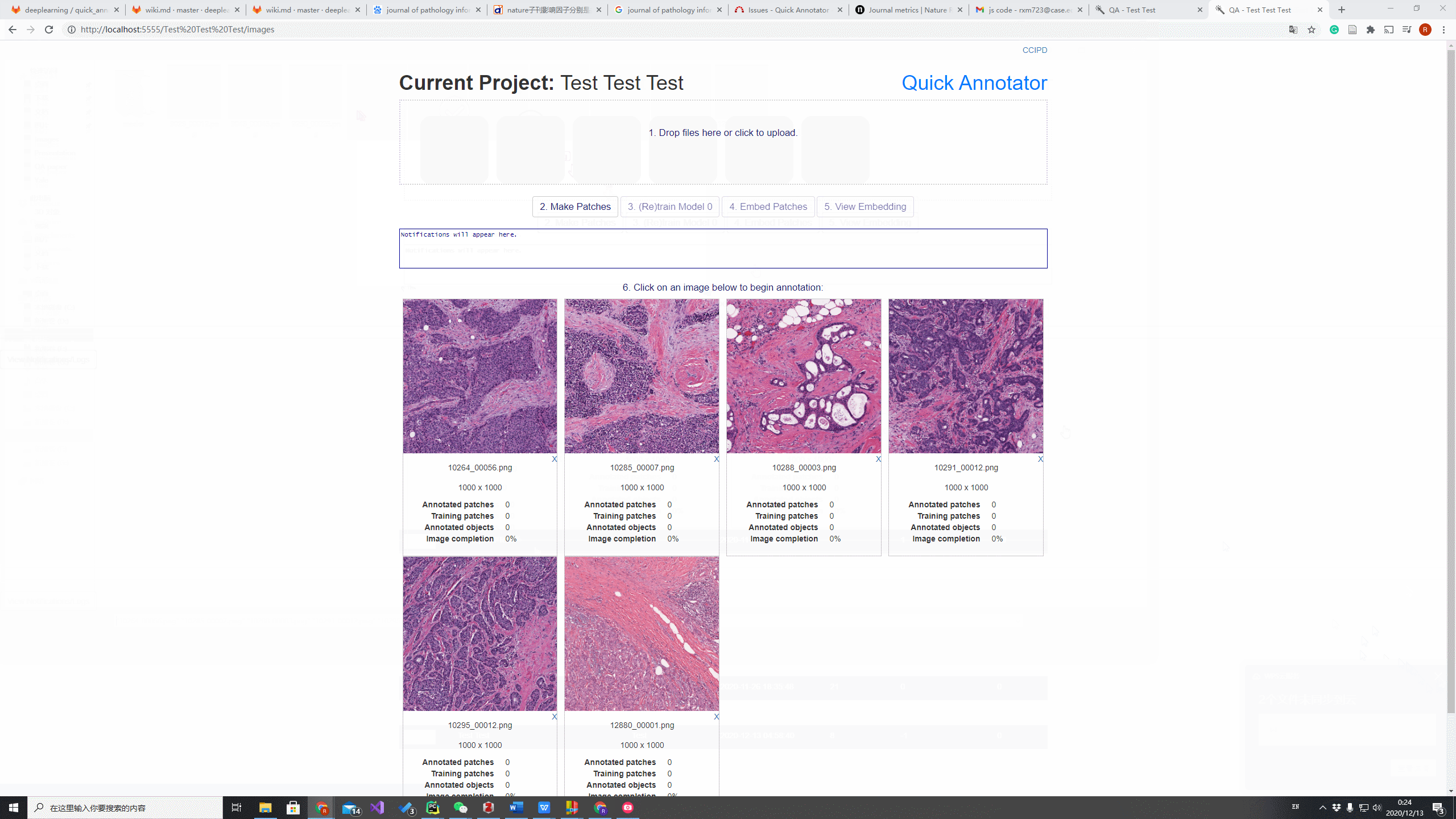
The image below shows, make patches successfully completed, and the next step is (Re)train Model which trains for AutoEncoder. When the AutoEncoder is ready, the user will Embed Patches and View Embedding, which directs the user to Embedding Page.

Users can also decide where to annotate by moving the selection square on the Annotation Page.

<em> Demo for step 6 and step 7</em>
Like the red arrow shows, the user clicks on Retrain Dl From base to train a new model.
As the blue arrow points, the prediction result is red, indicating that the prediction layer is not available since there is no model available.
see Navigation Bar
See more details here.
