Linked List
- 배열의 크기가 고정되어 있다.
- 그렇다고 엄청 큰 배열을 선언할 수도 없다.
- 만약, 그 크기보다 더 큰 공간을 요구한다면?
- 메모리의 낭비가 될 수도 있다.
- 데이터 집합을 보관하는 기능을 가지면서, 유연하게 크기를 바꿀 수 있는 자료구조
리스트를 구현하는 여러 가지 기법 중에서도 가장 간단한 방법
- 리스트 내의 각 요소는 노드(Node)라고 부른다.
- 링크드 리스트의 이름은 '노드를 연결(Link)해서 만드는 리스트'라서 붙여진 이름
- 링크드 리스트의 노드는 데이터를 보관하는 필드와, 다음 노드와의 연결고리 역할을 하는 포인터로 이루어진다.
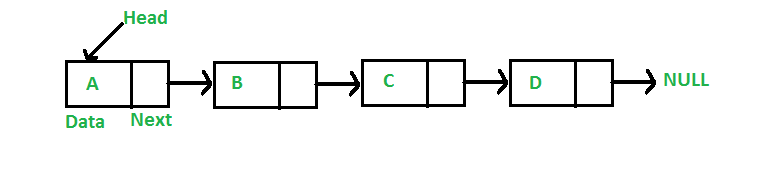
- 리스트의 맨 처음 노드를 Head 노드라고하고, 맨 마지막 노드를 Tail 노드라고 한다.
- 데이터가 늘어날 때 마다 노드를 만들어서 Tail에 붙이면 된다.
- 중간에 데이터를 끼워넣거나, 중간에 있는 데이터를 제거하는 경우에도 단순히 노드를 가리키는 포인터만 바꾸어주면 되기 때문에 삽입, 삭제가 배열에 비해 쉽다.
public class Node {
private int data;
private Node nextNode;
}- 노드 생성/소멸(GC가 알아서 해줌)
- 노드 추가
- 노드 탐색
- 노드 삭제
- 노드 삽입
노드의 생성/소멸, 추가, 삭제, 삽입은 링크드 리스트 자료구조를 구축하기 위한 연산
리스트 탐색은 구축되어 있는 링크드 리스트의 데이터를 활용하기 위한 연산
탐색연산은 리스트가 갖고 있는 약점 중의 하나임!
- 다음 노드를 가리키려는 포인터 때문에 각 노드마다 메모리가 추가로 필요하게 됨.
- 특정 위치에 있는 노드를 얻는데 드는 비용이 크며, 속도도 느림.
- 배열은 상수시간
- 링크드 리스트는 최악의 경우 O(n)임.
- 새로운 노드의 추가/삽입/삭제가 쉽고 빠름.
- 현재 노드의 다음 노드를 얻어오는 연산에 대해서 비용이 발생하지 않음.
레코드의 추가/삽입/삭제가 잦고, 조회는 드문 곳
링크드 리스트의 탐색 기능을 개선한 자료구조
Sinlgy Linked List와는 다르게 양방향으로 탐색이 가능하다.
- 연결 리스트(Linked List)
-
Basic concepts and nomenclature (기본 개념과 명명법)
- Each record of a linked list is often called an 'element' or 'node' 연결 리스트의 각 레코드를 흔히 '요소(엘리먼트)' 또는 '노드'라 부른다
- The field of each node that contains the address of the next node is usually called the 'next link' or 'next pointer'. 다음 노드의 주소를 포함하는 각 노드의 필드를 보통 '다음 링크(넥스트 링크)' 또는 '다음 포인터(넥스트 포인터)'라고 부른다.
- The remaining fields are known as the 'data', 'information', 'value', 'cargo', or 'payload' fields. 나머지 필드는 'data', 'infomation', 'value', 'cargo(배의 화물)' 또는 'payload(유료 하중 또는 전송되는 데이터)' 필드로 알려져 있다
- The 'head' of a list is its first node. The 'tail' of a list may refer either to the rest of the list after the head, or to the last node in the list. 리스트의 첫 번째 노드는 'head(헤드)'다. 리스트의 'tail(꼬리)'는 헤드 뒤에 있는 리스트의 나머지 부분 또는 목록의 마지막 노드를 나타낼 수 있다.
-
종류
-
Singly linked list
- Singly linked lists contain nodes which have a data field as well as 'next' field, which points to the next node in line of nodes. 단일 연결 리스트는 데이터 필드뿐만 아니라 (노드 라인의) 다음 노드를 가리키는 'next' 필드가 있는 노드가 포함되어 있다.
- Operations that can be performed on singly linked lists include insertion, deletion and traversal. 단일 연결 리스트에서 수행할 수 있는 작업에는 삽입, 삭제 및 횡단이 포함됩니다.
A singly linked list whose nodes contain two fields: an integer value and a link to the next node 정수 값과 다음 노드에 대한 링크 2개의 필드를 포함하는 단일 연결 리스트
-
Doubly linked list
- In a 'doubly linked list', each node contains, besides the next-node link, a second link field pointing to the 'previous' node in the sequence. 이중 연결 리스트에서 각 노드는 다음 노드 링크 외에 순서에서 '이전' 노드를 가리키는 2 번째 링크 필드를 포함한다.
- The two links may be called 'forward('s') and 'backwards', or 'next' and 'prev'('previous') 이 두 링크는 'forward(전방)'과 'backwards(후방)' 또는 'next(다음)'과 'prev(previous 이전)'으로 불릴 수 있다
A doubly linked list whose nodes contain three fields: an integer value, the link forward to the next node, and the link backward to the previous node 정수 값, 다음 노드로 향하는 링크, 이전 노드로 가는 링크 3 개의 필드가 포함된 이중 연결 리스트
- Many modern operating systems use doubly linked lists to maintain references to active processes, threads, and other dynamic objects. 많은 현대 운영 체제는 active processes, 스레드 및 기타 동적 객체에 대한 참조를 유지하기 위해 이중 연결 리스트를 사용합니다.
-
Multiply linked list
-
Circular linked list
-
Sentinel nodes
-
Empty lists
-
Hash linking
-
List handles
-
Combining alternatives
-
-
Tradeoffs
- As with most choices in computer programming and design, no method is well suited to all circumstances. 컴퓨터 프로그래밍과 디자인에서 대부분의 선택이 그렇듯이 어떤 방법도 모든 상황에 잘 맞지 않는다.
- A linked list data structure might work well in one case, but cause problems in another. 연결 리스트 데이터 구조는 한 경우에는 잘 작동하지만 다른 경우에는 문제를 일으킬 수 있다
- This is a list of some of the common tradeoffs involving linked list structures. 이것은 연결 리스트 구조와 관련된 일반적인 트레이트 오프의 목록입니다.
- Linked lists vs. dynamic arrays
- Singly linked linear lists vs. other lists
- Doubly linked vs. singly linked
- Double-linked lists require more space per node (unless one uses XOR-linking), and their elementary operations are more expensive; but they are often easier to manipulate because they allow fast and easy sequential access to the list in both directions 이중 연결 리스트는 노드 당 더 많은 공간을 필요로 하며 (XOR 링크를 사용하지 않는 한), 기본 작업은 더 비싸지만, 양방향으로 리스트에 빠르고 쉽게 순차적으로 접근할 수 있기 때문에 조작하기가 더 쉬운 경우가 많다.
- In a doubly linked list, one can insert or delete a node in a constant number of operations given only that node's address. 이중 연결 리스트에서는 해당 노드의 주소만 주어진 일정한 작업 수에 노드를 삽입하거나 삭제할 수 있다.
- To do the same in a singly linked list, one must have the address of the pointer to that node, which is either the handle for the whole list (in case of the first node) or the link field in the previous node. 단일 연결 리스트에서 동일한 작업을 수행하려면 해당 노드에 대한 포인터의 주소를 가지고 있어야 하며, 이 주소는 전체 리스트의 핸들(첫 번째 노드의 경우) 또는 이전 노드의 링크 필드 중 하나여야 한다.
- Some algorithms require access in both directions. On the other hand, doubly linked lists do not allow tail-sharing and cannot be used as persistent data structure. 일부 알고리즘은 양방향으로 접근해야 한다. 반면에 이중 연결 리스트는 tail-sharing을 허용하지 않으며 영구적인 데이터 구조로 사용할 수 없다.
- Circularly linked vs. linearly linked
- Using sentinel nodes
-
사용하는 이유
- Array(배열)에 비해 데이터의 추가/삽입 및 삭제가 용이하나 순차적으로 탐색하지 않으면 특정 위치의 요소에 접근할 수 없어 일반적으로 탐색 속도가 떨어진다.
- 즉 탐색 또는 정렬을 자주하면 배열을, 추가/삭제가 많으면 연결 리스트를 사용하는 것이 유리하다.
-
어디에 사용하는지
-
알고리즘 문제 : 요세푸스 문제
1번부터 N번까지 N 명의 사람이 원을 이루면서 앉아있고, 양의 정수 K(≤ N)가 주어진다. 이제 순서대로 K 번째 사람을 제거한다. 한 사람이 제거되면 남은 사람들로 이루어진 원을 따라 이 과정을 계속해 나간다. 이 과정은 N 명의 사람이 모두 제거될 떄까지 계속된다. 원에서 사람들이 제거되는 순서를 (N,K) - 요세푸스 순열이라고 한다. 예를 들어 (7,3) - 요세푸스 순열은 <3,6,2,7,5,1,4>이다. N과 K가 주어지면 (N,K)-요세푸스 순열을 구하는 프로그램을 작성하시오
-
-
시간복잡도와 공간복잡도
- Singly-Linked List, Doubly-Linked List
- 시간 복잡도
- Acess : O(n)
- Search : O(n)
- Insertion : O(1)
- Deletion : O(1)
- 공간 복잡도
- O(n)
- 시간 복잡도
- Singly-Linked List, Doubly-Linked List
-



리스트는 연결 리스트를 의미할까?
- 리스트 ≠ 연결 리스트
- 리스트의 종류
- 순차 리스트 : 배열을 기반으로 구현된 리스트
- 연결 리스트 : 메모리의 동적 할당을 기반으로 구현된 리스트
리스트 자료구조는 데이터를 나란히 저장한다. 그리고 중복된 데이터의 저장을 막지 않는다.
- 배열 기반 리스트의 단점
- 배열의 길이가 초기에 결정되어야 한다. 변경이 불가능하다.
- 삭제의 과정에서 데이터의 이동(복사)가 매우 빈번히 일어난다.
- 배열 기반 리스트의 장점
- 데이터의 참조가 쉽다. 인덱스 값을 기준으로 어디든 한 번에 참조가 가능하다.
-
배열의 단점
- 크기가 정해져 있다. (처음에 크기를 초기화해야함) - 뇌피셜
- 초기화 된 크기만큼 쓰지 않으면 남는 공간이 생긴다 - 뇌피셜
- 처음에 설정된 크기 이상의 값을 넣을 수 없다
메모리의 특성이 정적이어서(길이의 변경이 불가능해서) 메모리의 길이를 변경하는 것이 불가능하다.
이런 배열의 단점을 보완하기 위해 등장한 것이 '동적인 메모리의 구성'이다.
-
연결 리스트의 기본 원리
필요할 때마다 바구니의 역할을 하는 구조체 변수를 하나씩 동적 할당해서 이들을 연결한다.
→ 필요할 때마다 바구니를 하나씩 마련해서 그곳에 데이터를 저장하고 이들을 배열처럼 서로 연결한다.
그래서 연결 리스트의 형태는 아래와 같다고 할 수 있다.
- Node
데이터를 담는 바구니보다는 연결이 가능한 개체라는 사실에 중점을 두어 지은 이름
'데이터를 저장할 장소'와 '다른 변수를 가리키기 위한 장소' 구분되어 있음
- Node
데이터를 담는 바구니보다는 연결이 가능한 개체라는 사실에 중점을 두어 지은 이름
'데이터를 저장할 장소'와 '다른 변수를 가리키기 위한 장소' 구분되어 있음


야크쉐이빙을 안했더니 조금 빨리할 수 있어서 좋았다.
구현하면서 계속 시간복잡도와 공간복잡도를 생각하니까 쉽게 잊혀지지 않을 것 같다.
야크쉐이빙을 열심히했더니, 구현을 하지 못했고, 개념도 어중간하게 익힌 것 같다.
그래도 오늘 놀뻔했는데, 스터디를 해서 억지로 공부를 했다.
어제 과음을 했더니... 배가 아팠어요. 같이해서 좀 더 공부에 집중할 수 있었고, 서로 공부한 내용을 나누는 과정을 통해서 그냥 넘어갔던 부분을 다시 생각할 수 있었어요.