VoVNet-v2 backbone networks in Detectron2
Efficient Backbone Network for Object Detection and Segmentation
[CenterMask(code)][CenterMask2(code)] [VoVNet-v1(arxiv)] [VoVNet-v2(arxiv)] [BibTeX]
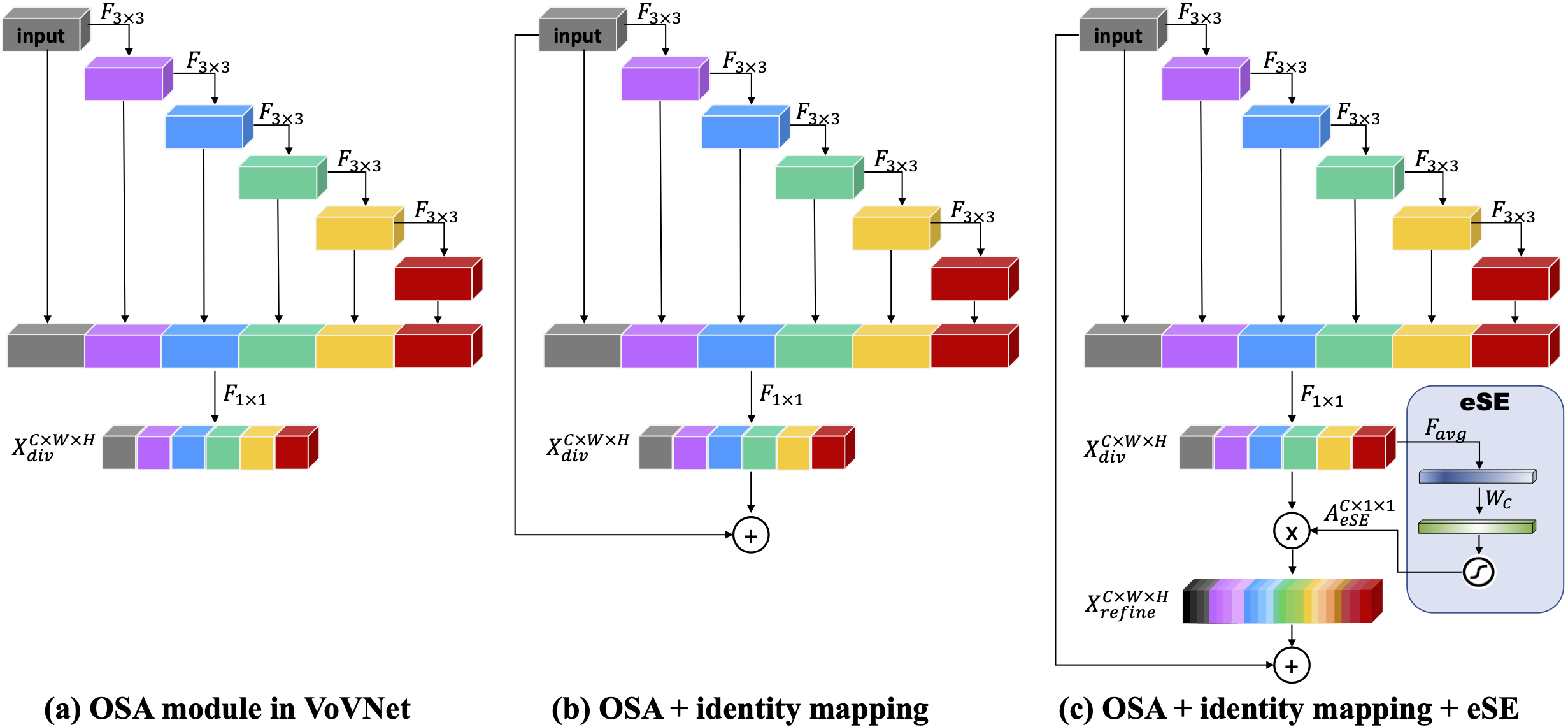
In this project, we release code for VoVNet-v2 backbone network (introduced by CenterMask) in detectron2 as a extention form. VoVNet can extract diverse feature representation efficiently by using One-Shot Aggregation (OSA) module that concatenates subsequent layers at once. Since the OSA module can capture multi-scale receptive fields, the diversifed feature maps allow object detection and segmentation to address multi-scale objects and pixels well, especially robust on small objects. VoVNet-v2 improves VoVNet-v1 by adding identity mapping that eases the optimization problem and effective SE (Squeeze-and-Excitation) that enhances the diversified feature representation.
Compared to ResNe(X)t backbone
- Efficient : Faster speed
- Accurate : Better performance, especially small object.
- Lightweight-VoVNet-19 has been released. (19/02/2020)
- VoVNetV2-19-FPNLite has been released. (22/01/2020)
- centermask2 has been released. (20/02/2020)
We measure the inference time of all models with batch size 1 on the same V100 GPU machine.
We train all models using V100 8GPUs.
- pytorch1.3.1
- CUDA 10.1
- cuDNN 7.3
| Backbone | Param. | lr sched | inference time | AP | APs | APm | APl | download |
|---|---|---|---|---|---|---|---|---|
| MobileNetV2 | 3.5M | 3x | 0.022 | 33.0 | 19.0 | 35.0 | 43.4 | model | metrics |
| V2-19 | 11.2M | 3x | 0.034 | 38.9 | 24.8 | 41.7 | 49.3 | model | metrics |
| V2-19-DW | 6.5M | 3x | 0.027 | 36.7 | 22.7 | 40.0 | 46.0 | model | metrics |
| V2-19-Slim | 3.1M | 3x | 0.023 | 35.2 | 21.7 | 37.3 | 44.4 | model | metrics |
| V2-19-Slim-DW | 1.8M | 3x | 0.022 | 32.4 | 19.1 | 34.6 | 41.8 | model | metrics |
- DW and Slim denote depthwise separable convolution and a thiner model with half the channel size, respectively.
| Backbone | Param. | lr sched | inference time | AP | APs | APm | APl | download |
|---|---|---|---|---|---|---|---|---|
| V2-19-FPN | 37.6M | 3x | 0.040 | 38.9 | 24.9 | 41.5 | 48.8 | model | metrics |
| R-50-FPN | 51.2M | 3x | 0.047 | 40.2 | 24.2 | 43.5 | 52.0 | model | metrics |
| V2-39-FPN | 52.6M | 3x | 0.047 | 42.7 | 27.1 | 45.6 | 54.0 | model | metrics |
| R-101-FPN | 70.1M | 3x | 0.063 | 42.0 | 25.2 | 45.6 | 54.6 | model | metrics |
| V2-57-FPN | 68.9M | 3x | 0.054 | 43.3 | 27.5 | 46.7 | 55.3 | model | metrics |
| X-101-FPN | 114.3M | 3x | 0.120 | 43.0 | 27.2 | 46.1 | 54.9 | model | metrics |
| V2-99-FPN | 96.9M | 3x | 0.073 | 44.1 | 28.1 | 47.0 | 56.4 | model | metrics |
| Backbone | lr sched | inference time | box AP | box APs | box APm | box APl | mask AP | mask APs | mask APm | mask APl | download |
|---|---|---|---|---|---|---|---|---|---|---|---|
| V2-19-FPNLite | 3x | 0.036 | 39.7 | 25.1 | 42.6 | 50.8 | 36.4 | 19.9 | 38.8 | 50.8 | model | metrics |
| V2-19-FPN | 3x | 0.044 | 40.1 | 25.4 | 43.0 | 51.0 | 36.6 | 19.7 | 38.7 | 51.2 | model | metrics |
| R-50-FPN | 3x | 0.055 | 41.0 | 24.9 | 43.9 | 53.3 | 37.2 | 18.6 | 39.5 | 53.3 | model | metrics |
| V2-39-FPN | 3x | 0.052 | 43.8 | 27.6 | 47.2 | 55.3 | 39.3 | 21.4 | 41.8 | 54.6 | model | metrics |
| R-101-FPN | 3x | 0.070 | 42.9 | 26.4 | 46.6 | 56.1 | 38.6 | 19.5 | 41.3 | 55.3 | model | metrics |
| V2-57-FPN | 3x | 0.058 | 44.2 | 28.2 | 47.2 | 56.8 | 39.7 | 21.6 | 42.2 | 55.6 | model | metrics |
| X-101-FPN | 3x | 0.129 | 44.3 | 27.5 | 47.6 | 56.7 | 39.5 | 20.7 | 42.0 | 56.5 | model | metrics |
| V2-99-FPN | 3x | 0.076 | 44.9 | 28.5 | 48.1 | 57.7 | 40.3 | 21.7 | 42.8 | 56.6 | model | metrics |
| Name | lr sched |
inference time (s/im) |
box AP |
mask AP |
PQ | download |
|---|---|---|---|---|---|---|
| R-50-FPN | 3x | 0.063 | 40.0 | 36.5 | 41.5 | model | metrics |
| V2-39-FPN | 3x | 0.063 | 42.8 | 38.5 | 43.4 | model | metrics |
| R-101-FPN | 3x | 0.078 | 42.4 | 38.5 | 43.0 | model | metrics |
| V2-57-FPN | 3x | 0.070 | 43.4 | 39.2 | 44.3 | model | metrics |
Using this command with --num-gpus 1
python /path/to/vovnet-detectron2/train_net.py --config-file /path/to/vovnet-detectron2/configs/<config.yaml> --eval-only --num-gpus 1 MODEL.WEIGHTS <model.pth>As this vovnet-detectron2 is implemented as a extension form (detectron2/projects) upon detectron2, you just install detectron2 following INSTALL.md.
Prepare for coco dataset following this instruction.
We provide backbone weights pretrained on ImageNet-1k dataset.
To train a model, run
python /path/to/vovnet-detectron2/train_net.py --config-file /path/to/vovnet-detectron2/configs/<config.yaml>For example, to launch end-to-end Faster R-CNN training with VoVNetV2-39 backbone on 8 GPUs, one should execute:
python /path/to/vovnet-detectron2/train_net.py --config-file /path/to/vovnet-detectron2/configs/faster_rcnn_V_39_FPN_3x.yaml --num-gpus 8Model evaluation can be done similarly:
python /path/to/vovnet-detectron2/train_net.py --config-file /path/to/vovnet-detectron2/configs/faster_rcnn_V_39_FPN_3x.yaml --eval-only MODEL.WEIGHTS <model.pth>- Adding Lightweight models
- Applying VoVNet for other meta-architectures
If you use VoVNet, please use the following BibTeX entry.
@inproceedings{lee2019energy,
title = {An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection},
author = {Lee, Youngwan and Hwang, Joong-won and Lee, Sangrok and Bae, Yuseok and Park, Jongyoul},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops},
year = {2019}
}
@article{lee2019centermask,
title={CenterMask: Real-Time Anchor-Free Instance Segmentation},
author={Lee, Youngwan and Park, Jongyoul},
booktitle={CVPR},
year={2020}
}