-
常用算法
- 快慢指针
- dfs bfs
- 二分,注意边界
- dp
- 位运算,异或为主
-
最大公约数
#辗转相除法 int gcd(int a, int b) { return b == 0 ? a : gcd(b, a % b); }
-
three sum
class Solution { public: vector<vector<int>> threeSum(vector<int>& nums) { int target; vector<vector<int>> res; sort(nums.begin(), nums.end()); for (int i = 0; i < nums.size(); i++) { if (i > 0 && nums[i] == nums[i - 1]) { continue; } if ((target = nums[i]) > 0) { break; } int l = i + 1; int r = nums.size() - 1; while (l < r) { if (nums[l] + nums[r] + target > 0) { r--; } else if (nums[l] + nums[r] + target < 0) { l++; } else { target.push_back({target, nums[l], nums[r]}); l++, r--; while (nums[l] == nums[l - 1]) { l++; } while (nums[r] == nums[r + 1]) { r--; } } } } return res; } };
-
链表有环,求入口点
-
原地翻转数组
-
反转链表
-
随机散列
-
堆排,桶排,快排,归并
-
快排
class Solution { private int partition(int[] nums, int left, int right) { int key = nums[right]; while (left < right) { while (left < right && nums[left] <= key) { left++; } nums[right] = nums[left]; while (left < right && nums[right] >= key) { right--; } nums[left] = nums[right]; } nums[right] = key; return right; } private void quickSort(int[] nums, int left, int right) { if (left >= right) { return; } int pos = partition(nums, left, right); quickSort(nums, left, pos - 1); quickSort(nums, pos, right); } public int[] sortArray(int[] nums) { quickSort(nums, 0, nums.length - 1); return nums; }
-
堆排
class Solution { public: void adjust(vector<int>& nums, int parent, int size) { while (2 * parent + 1 < size) { int l = parent * 2 + 1; int r = parent * 2 + 2; int child = (r < size && nums[r] > nums[l]) ? r : l; if (nums[parent] > nums[child]) { return; } else { swap(nums[parent], nums[child]); parent = child; } } } vector<int> sortArray(vector<int>& nums) { for (int i = nums.size() / 2; i >= 0; i--) { adjust(nums, i, nums.size()); } for (int i = nums.size() - 1; i >= 0; i--) { swap(nums[0], nums[i]); adjust(nums, 0, i); } return nums; } };
-
归并排序
class Solution { public: void merge(vector<int>& nums, int left, int right) { if (left >= right) { return; } int mid = left + (right - left) / 2; merge(nums, left, mid); merge(nums, mid + 1, right); vector<int> tmp; int l = left, r = mid + 1; while (l <= mid && r <= right) { if (nums[l] < nums[r]) { tmp.push_back(nums[l++]); } else { tmp.push_back(nums[r++]); } } while (l <= mid) { tmp.push_back(nums[l++]); } while (r <= right) { tmp.push_back(nums[r++]); } for (int i = 0; i < right - left + 1; i++) { nums[left + i] = tmp[i]; } } vector<int> sortArray(vector<int>& nums) { merge(nums, 0, nums.size() - 1); return nums; } };
-
不借助临时变量交换a, b
b = a - b; a = a - b; b = a + b
a = a ^ b; b = a ^ b; a = a ^ b; #利用 a ^ b ^ b = a; #注意 a != b
-
逆序对个数 归并排序
-
数据流中的中位数 一个大根堆一个小根堆
-
BST倒数第k小节点 leetcode230
-
海量数据处理,大数据日志找最多 https://blog.csdn.net/weixin_34161029/article/details/92441368
-
查找二叉树两个节点的公共父节点
-
两个链表的第一个公共节点
-
括号匹配
-
top k partition 或者大根堆小根堆
-
非递归前中后
-
判断两个链表是否相交
-
最长上升子序列
-
随机洗牌算法
-
树的水平遍历用递归
#include <cstdlib> #include <iostream> using namespace std; //取start到end之间的随机值 int rand(int range_start, int range_end) { srand((unsigned int)time(NULL)); return rand()%(range_end - range_start) + range_start; } void swap(int* a, int* b) { int* temp; *temp = *a; *a = *b; *b = *temp; } void shuffle(int a[], int len) { int shuffle_key; for(int i = 0; i< len; i++) { shuffle_key = rand(0, len); swap(a[i], a[shuffle_key]); } } int main(int argc, char *argv[]) { int a[8]={3, 5, 7, 2, 12, 1, 5, 6}; shuffle(a, 8); for(int i = 0; i < 8; i++) { printf("%d", a[i]); } system("PAUSE"); return EXIT_SUCCESS; }
-
进程线程区别,进程间通信,各自特点
-
分页
- elf文件需要装载到内存中执行,进程的地址空间被划分成若干固定大小的页,内存空间分成若干大小的块,页和块的大小相等,实现了离散分配,虚拟内存使程序认为他有连续的地址.
-
分段
- 分成代码段,数据段,堆栈段,每个内存段都有一个权限界别,内核最高,用户最低,虚拟地址偏移量加上段基地址可以定位某个字节的位置,如果用户想要访问一个
-
共享内存实现原理
-
在Linux中,每个进程都有属于自己的进程控制块(PCB)和地址空间(Addr Space),并且都有一个与之对应的页表,负责将进程的虚拟地址与物理地址进行映射,通过内存管理单元(MMU)进行管理。两个不同的虚拟地址通过页表映射到物理空间的同一区域,它们所指向的这块区域即共享内存。
-
共享内存的通信原理示意图:
-
对于上图我的理解是:当两个进程通过页表将虚拟地址映射到物理地址时,在物理地址中有一块共同的内存区,即共享内存,这块内存可以被两个进程同时看到。这样当一个进程进行写操作,另一个进程读操作就可以实现进程间通信。但是,我们要确保一个进程在写的时候不能被读,因此我们使用信号量来实现同步与互斥。
-
对于一个共享内存,实现采用的是引用计数的原理,当进程脱离共享存储区后,计数器减一,挂架成功时,计数器加一,只有当计数器变为零时,才能被删除。当进程终止时,它所附加的共享存储区都会自动脱离。
-
-
管道实现原理n
-
用户态 内核态
-
linux调试多线程,多进程
-
TLB是一种页表cache,是特殊的寄存器,减少一次访问内存
-
高并发,epoll工作模式,epoll和select比较,epoll遇到的问题
-
select, poll返回整个用户注册的事件集合,而且把句柄和事件注册到一起,所以每次索引文件就绪的时间复杂度是O(n),而epoll把句柄和事件分开,注册到内核红黑树上,时间复杂读O(lgN),将就绪事件放在链表上,通过回调唤醒,回调在epoll_ctl注册到句柄,用户太只需要拷贝就绪链表就可以,复杂度为O(1)
-
epoll适合注册很多句柄但是发生事件不多,如果注册句柄很少还频繁发生,会反复触发回调函数,回调的开销可能大于遍历的开销
-
水平工作机制(LT)
- 对于读,只要缓冲区不为空,返回就绪
- 对于写,只要缓冲区不满,返回就绪
-
边沿工作机制(ET)
- 有不可读变为可读,缓冲区由空变为不空,缓冲区有新数据到达
- 由不可写变为可写
-
-
epoll的问题
- ET应该是非阻塞的,如果是阻塞的读或写会因为没有后续事件而阻塞
- EPOLLONESHOT,只触发一次,一个线程读取完Socket数据之后开始处理数据,这时候这个socket又来了数据,会唤醒另一个线程,epolloneshot保证唤醒一次
- LT可以不立即处理,ET必须立即处理事件
-
自旋锁和读写锁,互斥锁,信号量,大内核索,屏障,cas
-
fork vfork fork父子进程执行顺序不一定,vfork先执行子进程,子进程在父进程的地址空间运行,不可以写,父子进程一样的虚拟内存和物理内存不需要拷贝页表,父进程阻塞等待子进程执行结束之后再执行.fork之后父子进程在没有写之前,共用一样的物理内存,但是不一样的虚拟内存,fork会复制父进程的页表.
-
threadlocal, __thread
-
零拷贝 cpu不执行拷贝数据从一块到另一块的操作.
- 一次网络io数据:
- 用户调用read,系统调用陷入到内核态(一次上下文切换)
- 向磁盘请求数据
- 通过DMA将磁盘数据读取到内核缓冲区
- read系统调用返回到用户态,数据从内核缓冲区拷贝到用户缓冲区(二次上下文切换)
- write系统调用,将数据写入到内核socket缓冲区(三次上下文切换)
- write系统调用返回(四次上下文切换)
- DMA将内核socket缓冲区拷贝到协议栈(四次数据拷贝)
- 零拷贝过程:
- 第二次和第三次上下文切换和数据拷贝是多余的
- 用sendfile进行优化
- sendfile系统调用,进入内核态(一次上下文切换)
- 通过DMA将数据从磁盘读到内核缓冲区(1)
- 从内核缓冲区拷贝到socket缓冲区(2)
- sendfile返回,从内核态进入用户态(二次上下文切换)
- DMA将socket缓冲区数据拷贝到网络协议栈(3次数据拷贝)
- 还可以用mmap省去用户和内核的拷贝,用户和内核共用设备内存
- 一次网络io数据:
-
虚拟内存能否重叠:可以重叠,虚拟内存重叠,物理内存不一定重叠,虚拟内存在磁盘,页表在内存,TLB快表是寄存器,MMU是硬件,页表把虚拟内存转换为物理地址,当物理地址不在内存发生缺页
-
unordered map map
-
copy on write写时拷贝,当fork之后,exec之前父子进程不同的进程地址空间但是共用一样的物理空间,exec之后代码段不一样,如果写但是不exec则数据段堆栈再分配空间并拷贝父进程
-
判断内存泄漏,避免内存泄漏 重载operator new计数
-
为什么要有字节对齐
- CPU访问数据效率问题.还可以有效节省内存空间.假设处理器总是从内存中获取8个字节,地址必须是8的倍数。如果我们可以保证任何double将被对齐,使其地址是8的倍数,那么可以用一个内存操作读取或写入该值。否则,我们可能需要执行两次内存访问,因为对象可能被分成两个8字节的内存块。
- 另一方面,用于实现多媒体操作的一些SSE指令对于未对齐的数据将不能正确工作。
-
怎么控制字节对齐
- #pragma pack(n)
- 不能用memcmp比较,因为对齐填充的是随机值
-
时间轮,小根堆计时器
-
虚拟内存和物理内存都是以页为单位,4k字节
-
malloc, new,operator new, placement new brk sbrk mmap
-
ldd 查看程序运行所需的共享库
-
cut分割字符, grep, sed, awk
-
如何避免内存泄漏 RAII等,如何检测内存泄漏 重载operator new
-
git
git add . git commit -m " " git checkout 更换分支 git status -s状态 git merge 合并分支 git fetch 拉远程主机最新分支 git pull = git fetch + git merge -
程序计数器:
-
程序计数器是用于存放下一条指令所在单元的地址的地方。
当执行一条指令时,首先需要根据PC中存放的指令地址,将指令由内存取到指令寄存器中,此过程称为“取指令”。与此同时,PC中的地址或自动加1或由转移指针给出下一条指令的地址。此后经过分析指令,执行指令。完成第一条指令的执行,而后根据PC取出第二条指令的地址,如此循环,执行每一条指令。
-
-
线程共有和私有数据
- 公有数据
- 堆,进程地址空间,代码段,进程文件描述符,全局变量,静态变量
- 私有数据
- 线程栈.线程私有数据,寄存器,程序计数器,线程, __thread(thread_local c++11关键字)线程局部存储每个线程有一份独立实体相互不干扰
- 公有数据
-
fork后子进程和父进程共享的资源包括:
-
子进程对变量所做的改变并不影响父进程中该变量的值。
-
父进程和子进程并不共享这些存储空间部分。父进程和子进程共享正文段。
- 打开的文件
- 实际用户ID、实际组ID、有效用户ID、有效组ID
- 添加组ID
- 进程组ID
- 会话期ID
- 控制终端
- 设置-用户-ID标志和设置-组-ID标志
- 当前工作目录
- 根目录
- 文件方式创建屏蔽字
- 信号屏蔽和排列
- 对任一打开文件描述符的在执行时关闭标志
- 环境
- 连接的共享存储段(共享内存)
- 资源限制
父子进程之间的区别是:
- fork的返回值
- 进程ID
- 不同的父进程ID
- 子进程的tms_utime,tms_stime,tms-cutime以及tms_ustime设置为0
- 父进程设置的锁,子进程不继承
- 子进程的未决告警被清除
- 子进程的未决信号集设置为空集
-
文件系统
- 虚拟文件系统,作为中间层,用户和虚拟文件系统打交到,统一的ioapi
- 超级块 一个超级块对应一个文件系统,保存文件系统的大小类型状态
- 索引节点inode,保存了文件的元信息,存有指向文件的指针,一个文件只有一个Inode,inode号是唯一的
- block:文件实际保存在block中
- 目录项:存在于内存的,描述文件逻辑属性,为了提高查找性能,文件和文件夹都属于目录项,目录也是文件也有Inode,目录项组成目录树
- 文件对象 进程已经打开的文件
-
查看进程
- ps -ef
-
shell
awk -F ':' '{print $3}' demo.log | uniq -c | sort -r sort -nr -k2 #sort -n按出现次数排序,-r倒序排序,-k2按第2列排序 NR显示行号 FNR多个文件行号从1开始
-
死锁
https://blog.csdn.net/guaiguaihenguai/article/details/80303835#commentBox
-
网络字节序 网络上传输的数据都是字节流,对于一个多字节数值,在进行网络传输的时候,先传递哪个字节?也就是说,当接收端收到第一个字节的时候,它将这个字节作为高位字节还是低位字节处理,是一个比较有意义的问题; UDP/TCP/IP协议规定:把接收到的第一个字节当作高位字节看待,这就要求发送端发送的第一个字节是高位字节;而在发送端发送数据时,发送的第一个字节是该数值在内存中的起始地址处对应的那个字节,也就是说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节(即:高位字节存放在低地址处);由此可见,多字节数值在发送之前,在内存中因该是以大端法存放的; 所以说,网络字节序是大端字节序;比如,我们经过网络发送整型数值0x12345678时,在80X86平台中,它是以小端发存放的,在发送之前需要使用系统提供的字节序转换函数htonl()将其转换成大端法存放的数值;
常见CPU的字节序 Big Endian : PowerPC、IBM、Sun Little Endian : x86、DEC ARM既可以工作在大端模式,也可以工作在小端模式。
-
TCP四次挥手,为什么四次挥手
-
time_wait
-
SO_LINGER
-
TCP发大包出现情况,UDP会么 缓冲区小于包大小,粘包, UDP不会粘包会丢失数据
-
TCP协议如何保证可靠传输\1. 应用数据被分割成
TCP认为最适合发送的数据块。 \2.TCP给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。 \3. 校验和:TCP将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP将丢弃这个报文段和不确认收到此报文段。 \4.TCP的接收端会丢弃重复的数据。 \5. 流量控制:TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP使用的流量控制协议是可变大小的滑动窗口协议。 (TCP利用滑动窗口实现流量控制) \6. 拥塞控制: 当网络拥塞时,减少数据的发送。 \7. ARQ协议: 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。 \8. 超时重传: 当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。 -
ARQ协议
自动重传请求(Automatic Repeat-reQuest,ARQ)是OSI模型中数据链路层和传输层的错误纠正协议之一。它通过使用确认和超时这两个机制,在不可靠服务的基础上实现可靠的信息传输。如果发送方在发送后一段时间之内没有收到确认帧,它通常会重新发送。ARQ包括停止等待ARQ协议和连续ARQ协议。
-
停止等待ARQ协议
- 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认(回复ACK)。如果过了一段时间(超时时间后),还是没有收到 ACK 确认,说明没有发送成功,需要重新发送,直到收到确认后再发下一个分组;
- 在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认;
优点: 简单
缺点: 信道利用率低,等待时间长
连续ARQ协议
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
优点: 信道利用率高,容易实现,即使确认丢失,也不必重传。
缺点: 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5条 消息,中间第三条丢失(3号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
-
拥塞窗口:发送窗口取拥塞窗口和接受窗口的最小值
-
拥塞避免:
-
一般原理:发生拥塞控制的原因:资源(带宽、交换节点的缓存、处理机)的需求>可用资源。
作用:拥塞控制就是为了防止过多的数据注入到网络中,这样可以使网络中的路由器或者链路不至于过载。拥塞控制要做的都有一个前提:就是网络能够承受现有的网络负荷。
对比流量控制:拥塞控制是一个全局的过程,涉及到所有的主机、路由器、以及降低网络相关的所有因素。流量控制往往指点对点通信量的控制。是端对端的问题。
发送方为一个动态变化的窗口叫做拥塞窗口,拥塞窗口的大小取决于网络的拥塞程度。发送方让自己的发送窗口=拥塞窗口,但是发送窗口不是一直等于拥塞窗口的,在网络情况好的时候,拥塞窗口不断的增加,发送方的窗口自然也随着增加,但是接受方的接受能力有限,在发送方的窗口达到某个大小时就不在发生变化了。
发送方如果知道网络拥塞了呢?发送方发送一些报文段时,如果发送方没有在时间间隔内收到接收方的确认报文段,则就可以人为网络出现了拥塞。
主机开发发送数据报时,如果立即将大量的数据注入到网络中,可能会出现网络的拥塞。慢启动算法就是在主机刚开始发送数据报的时候先探测一下网络的状况,如果网络状况良好,发送方每发送一次文段都能正确的接受确认报文段。那么就从小到大的增加拥塞窗口的大小,即增加发送窗口的大小。
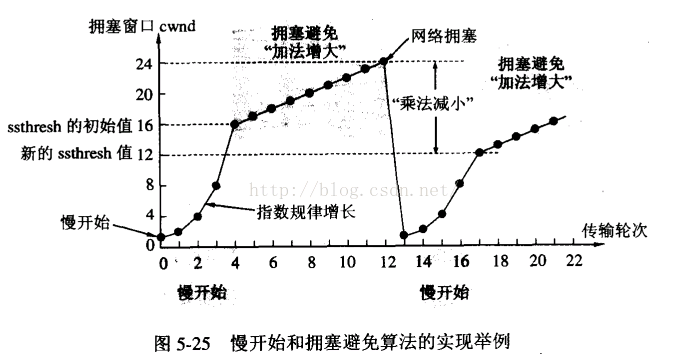
例子:开始发送方先设置cwnd(拥塞窗口)=1,发送第一个报文段M1,接收方接收到M1后,发送方接收到接收方的确认后,把cwnd增加到2,接着发送方发送M2、M3,发送方接收到接收方发送的确认后cwnd增加到4,慢启动算法每经过一个传输轮次(认为发送方都成功接收接收方的确认),拥塞窗口cwnd就加倍。
为了防止cwnd增加过快而导致网络拥塞,所以需要设置一个慢开始门限ssthresh状态变量它的用法:
- 当cwnd < ssthresh,使用慢启动算法,
- 当cwnd > ssthresh,使用拥塞控制算法,停用慢启动算法。
- 当cwnd = ssthresh,这两个算法都可以。
拥塞避免的思路:是让cwnd缓慢的增加而不是加倍的增长,每经历过一次往返时间就使cwnd增加1,而不是加倍,这样使cwnd缓慢的增长,比慢启动要慢的多。
无论是慢启动算法还是拥塞避免算法,只要判断网络出现拥塞,就要把慢启动开始门限(ssthresh)设置为设置为发送窗口的一半(>=2),cwnd(拥塞窗口)设置为1,然后在使用慢启动算法,这样做的目的能迅速的减少主机向网络中传输数据,使发生拥塞的路由器能够把队列中堆积的分组处理完毕。拥塞窗口是按照线性的规律增长,比慢启动算法拥塞窗口增长块的多。
实例: 1.TCP连接进行初始化的时候,cwnd=1,ssthresh=16。 2.在慢启动算法开始时,cwnd的初始值是1,每次发送方收到一个ACK拥塞窗口就增加1,当ssthresh =cwnd时,就启动拥塞控制算法,拥塞窗口按照规律增长, 3.当cwnd=24时,网络出现超时,发送方收不到确认ACK,此时设置ssthresh=12,(二分之一cwnd),设置cwnd=1,然后开始慢启动算法,当cwnd=ssthresh=12,慢启动算法变为拥塞控制算法,cwnd按照线性的速度进行增长。
- 乘法减小:无论在慢启动阶段还是在拥塞控制阶段,只要网络出现超时,就是将cwnd置为1,ssthresh置为cwnd的一半,然后开始执行慢启动算法(cwnd<ssthresh)。
- 加法增大:当网络频发出现超时情况时,ssthresh就下降的很快,为了减少注入到网络中的分组数,而加法增大是指执行拥塞避免算法后,是拥塞窗口缓慢的增大,以防止网络过早出现拥塞。 这两个结合起来就是AIMD算法,是使用最广泛的算法。拥塞避免算法不能够完全的避免网络拥塞,通过控制拥塞窗口的大小只能使网络不易出现拥塞。
快重传算法要求首先接收方收到一个失序的报文段后就立刻发出重复确认,而不要等待自己发送数据时才进行捎带确认。接收方成功的接受了发送方发送来的M1、M2并且分别给发送了ACK,现在接收方没有收到M3,而接收到了M4,显然接收方不能确认M4,因为M4是失序的报文段。如果没有快重传,发送方需要等待超时计时器超时,但是按照快速重传算法,在收到M4、M5等报文段的时候,不断重复的向发送方发送M2的ACK,如果发送方一连收到三个重复的ACK,那么发送方不必等待重传计时器到期,由于发送方尽早重传未被确认的报文段。
- 当发送发连续接收到三个确认时,就执行乘法减小算法,把慢启动开始门限(ssthresh)减半,但是接下来并不执行慢开始算法。
- 此时不执行慢启动算法,而是把cwnd设置为ssthresh, 然后执行拥塞避免算法,使拥塞窗口缓慢增大。
-
udp还是tcp选择:
- tcp
- 数据要求完整不能丢包,不许发生错误
- 有限连接
- udp
- 大量连接,tcp会性能下降
- 实时性,允许丢包, 游戏 直播
- tcp
-
网络编程字节序问题出现的原因
-
web安全攻击
-
tcp ack的意义:
- 发送方在一定时间内没有收到服务端的ACK确认包后,就会重新发送TCP数据包。发送方收到了ACK,表明接收方已经接收到数据,保证了数据的可靠达到。
- 接收方在接收到数据后,不是立即会给发送方发送ACK的。这可能由以下原因导致: 1、收到数据包的序号前面还有需要接收的数据包。因为发送方发送数据时,并不是需要等上次发送数据被Ack就可以继续发送TCP包,而这些TCP数据包达到的顺序是不保证的,这样接收方可能先接收到后发送的TCP包(注意提交给应用层时是保证顺序的)。 2、为了降低网络流量,ACK有延迟确认机制。 3、ACK的值到达最大值后,又会从0开始。
- ACK延迟确认机制 接收方在收到数据后,并不会立即回复ACK,而是延迟一定时间。一般ACK延迟发送的时间为200ms,但这个200ms并非收到数据后需要延迟的时间。系统有一个固定的定时器每隔200ms会来检查是否需要发送ACK包。这样做有两个目的。 1、这样做的目的是ACK是可以合并的,也就是指如果连续收到两个TCP包,并不一定需要ACK两次,只要回复最终的ACK就可以了,可以降低网络流量。 2、如果接收方有数据要发送,那么就会在发送数据的TCP数据包里,带上ACK信息。这样做,可以避免大量的ACK以一个单独的TCP包发送,减少了网络流量。
-
tcp半打开连接
tcp连接一端在进行完三次握手以后进入ESTABLISHED状态,如果连接的对端在某一时刻在网络中消失,而本端没有感知到,还是处于ESTABLISHED状态,那么本端的连接就被称为半打开连接(Half Open)。
-
半连接队列
server端的tcp连接在三次握手阶段会经历SYN_RECV状态到ESTABLISHED状态的变迁,其中SYN_RECV状态到连接存放于listen socket积压队列的半连接队列中,当连接由SYN_RECV状态变为ESTABLISHED状态,连接会被从半连接队列中移到已连接队列中
-
http请求头
-
协议头 说明 示例 状态 Accept 可接受的响应内容类型(Content-Types)。 Accept: text/plain 固定 Accept-Charset 可接受的字符集 Accept-Charset: utf-8 固定 Accept-Encoding 可接受的响应内容的编码方式。 Accept-Encoding: gzip, deflate 固定 Accept-Language 可接受的响应内容语言列表。 Accept-Language: en-US 固定 Accept-Datetime 可接受的按照时间来表示的响应内容版本 Accept-Datetime: Sat, 26 Dec 2015 17:30:00 GMT 临时 Authorization 用于表示HTTP协议中需要认证资源的认证信息 Authorization: Basic OSdjJGRpbjpvcGVuIANlc2SdDE== 固定 Cache-Control 用来指定当前的请求/回复中的,是否使用缓存机制。 Cache-Control: no-cache 固定 Connection 客户端(浏览器)想要优先使用的连接类型 Connection: keep-alive Connection: Upgrade 固定 Cookie 由之前服务器通过Set-Cookie(见下文)设置的一个HTTP协议Cookie Cookie: $Version=1; Skin=new; 固定:标准 Content-Length 以8进制表示的请求体的长度 Content-Length: 348 固定 Content-MD5 请求体的内容的二进制 MD5 散列值(数字签名),以 Base64 编码的结果 Content-MD5: oD8dH2sgSW50ZWdyaIEd9D== 废弃 Content-Type 请求体的MIME类型 (用于POST和PUT请求中) Content-Type: application/x-www-form-urlencoded 固定 Date 发送该消息的日期和时间(以RFC 7231中定义的"HTTP日期"格式来发送) Date: Dec, 26 Dec 2015 17:30:00 GMT 固定 Expect 表示客户端要求服务器做出特定的行为 Expect: 100-continue 固定 From 发起此请求的用户的邮件地址 From: [email protected] 固定 Host 表示服务器的域名以及服务器所监听的端口号。如果所请求的端口是对应的服务的标准端口(80),则端口号可以省略。 Host: www.itbilu.com:80 Host: www.itbilu.com 固定 If-Match 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要用于像 PUT 这样的方法中,仅当从用户上次更新某个资源后,该资源未被修改的情况下,才更新该资源。 If-Match: "9jd00cdj34pss9ejqiw39d82f20d0ikd" 固定 If-Modified-Since 允许在对应的资源未被修改的情况下返回304未修改 If-Modified-Since: Dec, 26 Dec 2015 17:30:00 GMT 固定 If-None-Match 允许在对应的内容未被修改的情况下返回304未修改( 304 Not Modified ),参考 超文本传输协议 的实体标记 If-None-Match: "9jd00cdj34pss9ejqiw39d82f20d0ikd" 固定 If-Range 如果该实体未被修改过,则向返回所缺少的那一个或多个部分。否则,返回整个新的实体 If-Range: "9jd00cdj34pss9ejqiw39d82f20d0ikd" 固定 If-Unmodified-Since 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 If-Unmodified-Since: Dec, 26 Dec 2015 17:30:00 GMT 固定 Max-Forwards 限制该消息可被代理及网关转发的次数。 Max-Forwards: 10 固定 Origin 发起一个针对跨域资源共享的请求(该请求要求服务器在响应中加入一个Access-Control-Allow-Origin的消息头,表示访问控制所允许的来源)。 Origin: http://www.itbilu.com 固定: 标准 Pragma 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生。 Pragma: no-cache 固定 Proxy-Authorization 用于向代理进行认证的认证信息。 Proxy-Authorization: Basic IOoDZRgDOi0vcGVuIHNlNidJi2== 固定 Range 表示请求某个实体的一部分,字节偏移以0开始。 Range: bytes=500-999 固定 Referer 表示浏览器所访问的前一个页面,可以认为是之前访问页面的链接将浏览器带到了当前页面。Referer其实是Referrer这个单词,但RFC制作标准时给拼错了,后来也就将错就错使用Referer了。 Referer: http://itbilu.com/nodejs 固定 TE 浏览器预期接受的传输时的编码方式:可使用回应协议头Transfer-Encoding中的值(还可以使用"trailers"表示数据传输时的分块方式)用来表示浏览器希望在最后一个大小为0的块之后还接收到一些额外的字段。 TE: trailers,deflate 固定 User-Agent 浏览器的身份标识字符串 User-Agent: Mozilla/…… 固定 Upgrade 要求服务器升级到一个高版本协议。 Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 固定 Via 告诉服务器,这个请求是由哪些代理发出的。 Via: 1.0 fred, 1.1 itbilu.com.com (Apache/1.1) 固定 Warning 一个一般性的警告,表示在实体内容体中可能存在错误。 Warning: 199 Miscellaneous warning 固定 -
对于http的请求返回结果要进行内容的长度校验主要有两种方式,二者互斥使用
1.客户端在http头(head)加Connection:keep-alive时,服务器的response是Transfer-Encoding:chunked的形式,通知页面数据是否接收完毕,例如长连接或者程序运行中可以动态的输出内容,例如一些运算比较复杂且需要用户及时的得到最新结果,那就采用chunked编码将内容分块输出。
2.除了如1所述之外的情况一般都是可以获取到Content-Length的。
-
-
http响应码
-
100 Continue: 服务器通知浏览器之前一切正常,请客户端继续请求,如果请求结束,可忽略;
101 Switching Protocal: 针对请求头的Upgrade返回的信息。表明服务器正在切换到指定的协议。
Upgrade是HTTP1.1提出的升级机制,可以升级到其他协议。
如果使用,客户端需要设置如下:
Connection: Upgrade Upgrade: protocol-name[/protocol-version]服务器如果不同意直接忽略;如果同意,响应如下:
HTTP/1.1 101 Switching Protocols Connection: upgrade Upgrade: protocol-name[/protocol-version]例如:1)升级WebSocket
客户端请求如下:
GET ws://example.com/ HTTP/1.1 Connection: Upgrade Upgrade: websocket Origin: http://example.com Sec-WebSocket-Version: 13 Sec-WebSocket-Key: d4egt7snxxxxxx2WcaMQlA== Sec-WebSocket-Extensions: permessage-deflate; client_max_window_bits服务器如果同意,响应如下:
HTTP/1.1 101 Switching Protocols Connection: Upgrade Upgrade: websocket Sec-WebSocket-Accept: gczJQPmQ4Ixxxxxx6pZO8U7UbZs=2)升级到http2
客户端请求如下:
GET / HTTP/1.1 Host: example.com Connection: Upgrade, HTTP2-Settings Upgrade: h2c // h2c是http2的名称 HTTP2-Settings: <base64url encoding of HTTP/2 SETTINGS payload>服务端如果同意,响应如下:
HTTP/1.1 101 Switching Protocols``Connection: Upgrade``Upgrade: h2c103 Early Hints: 此状态代码主要用于与
Link链接头一起使用,以允许用户代理在服务器仍在准备响应时开始预加载资源 -
200 OK: 请求成功
201 Created: 常用于POST,PUT 请求,表明请求已经成功,并新建了一个资源。并在响应体中返回路径。
202 Accepted: 请求已经接收到,但没有响应,稍后也不会返回一个异步请求结果。 该状态码适用于等待其他进程处理或者批处理的场景。
203 No-Authoritative Information: 表明响应返回的元信息(meta-infomation)和最初的服务器不同,而是从本地或者第三方获取的。
主要用于其他资源的镜像和备份。除了前面的情况,首选还是200。
204 No Content: 请求没有数据返回,但是头信息有用。用户代理(浏览器)会更新缓存的头信息。
205 Reset Content: 告诉用户代理(浏览器)重置发送该请求的文档。
206 Partical Content: 当客户端使用Range请求头时,返回该状态码。
-
300重定向
-
301表示搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。
-
301 Moved Permanently(永久移动)
被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。新的永久性的URI应当在响应的Location域中返回。除非这是一个HEAD请求,否则响应的实体中应当包含指向新的URI的超链接及简短说明。如果这不是一个GET或者HEAD请求,因此浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。注意:对于某些使用HTTP/1.0协议的浏览器,当它们发送的POST请求得到了一个301响应的话,接下来的重定向请求将会变成GET方式。
-
302 Found: 请求资源的URL被暂时修改到Location提供的URL。未来可能还会有新的修改。
浏览器会根据新的URL重新请求资源。有些客户端会把方法method改为GET,建议在GET和HEAD方法中使用。
搜索引擎不会更改URL到资源的。
303 See Other: 服务通过返回的响应数据指导客户端通过GET方法去另一个URL获取资源。
通常用于POST或者PUT的请求返回结果,重定向到信息提示页面或者进度展示页面。
重定向页面的方法是GET方法。
307 Temporary Redirect: 临时重定向。基本和302相同。
唯一的区别是这个状态码严格禁止浏览器到新URL请求资源时修改原来的请求方式和请求体。
就是说原来使用POST,这次还是要使用POST。
如果想要用PUT方法去修改一个服务器上没有的资源,可以用303状态码
如果想要把一个POST方法改为GET,请使用303。
308 Permanent Redirect: 永久重定向。基本和301相同。但是严格禁止修改请求方式和请求体。
-
400 Bad Request: 请求语法有问题,服务器无法识别。
没有host请求头字段,或者设置了超过一个的host请求头字段。
401 UnAuthorized: 客户端未授权该请求。缺乏有效的身份认证凭证,一般可能是未登陆。登陆后一般都解决问题。
403 Forbidden: 服务器拒绝响应。权限不足。
404 Not Found: URL无效或者URL有效但是没有资源。
405 Method Not Allowed: 请求方式Method不允许。但是GET和HEAD属于强制方式,不能返回这个状态码。
406 Not Acceptable: 资源类型不符合服务器要求。
407 Proxy Authorization Required: 需要代理授权。
408 Request Timeout:服务器将不再使用的连接关闭。响应头会有Connection: close。
426 Upgrade Required: 告诉客户端需要升级通信协议。
-
500 Internal Server Error: 服务器内部错误,未捕获。
502 Bad Gateway: 服务器作为网关使用时,收到上游服务器返回的无效响应。
503 Service Unavailable: 无法服务。一般发生在因维护而停机或者服务过载。
一般还会伴随着返回一个响应头Retry-After: 说明恢复服务的估计时间。
504 Gateway Timeout: 网关超时。服务器作为网关或者代理,不能及时从上游服务器获取响应返回给客户端。
505 Http Version Not Supported: 发出的请求http版本服务器不支持。如果请求通过http2发送,服务器不支持http2.0,就会返回该状态码。
-
-
http 1.0 1.1
-
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
-
dns劫持:
域名劫持是互联网攻击的一种方式,通过攻击域名解析服务器(DNS),或伪造域名解析服务器(DNS)的方法,把目标网站域名解析到错误的IP地址从而实现用户无法访问目标网站的目的或者蓄意或恶意要求用户访问指定IP地址(网站)的目的。
-
http1.1 http2.0
-
新的二进制:http1.1基于解析文本,文本表现形式多样,健壮性受影响,http2.0传输2进制
-
header压缩
前面提到过http1.x的header由于cookie和user agent很容易膨胀,而且每次都要重复发送。http2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。高效的压缩算法可以很大的压缩header,减少发送包的数量从而降低延迟。
这里普及一个小知识点。现在大家都知道tcp有slow start的特性,三次握手之后开始发送tcp segment,第一次能发送的没有被ack的segment数量是由initial tcp window大小决定的。这个initial tcp window根据平台的实现会有差异,但一般是2个segment或者是4k的大小(一个segment大概是1500个字节),也就是说当你发送的包大小超过这个值的时候,要等前面的包被ack之后才能发送后续的包,显然这种情况下延迟更高。intial window也并不是越大越好,太大会导致网络节点的阻塞,丢包率就会增加,具体细节可以参考IETF这篇文章。http的header现在膨胀到有可能会超过这个intial window的值了,所以更显得压缩header的重要性。
-
多路复用:连接共享,每一个request对应一个id,http1.1中,一个请求对应一个连接,请求结束,链接断开,利用给request标记id,可以做到多个请求共用一个连接
- http1.x中的长链接:若干请求排队串行处理,后面的请求需要等待前面的返回
-
HTTP2.0多路复用有多好? HTTP 性能优化的关键并不在于高带宽,而是低延迟。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。 HTTP/2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。
-
-
post,get区别
POST和GET都是向服务bai器提交数据,并且都会du从服务器获取数据。
区别:
1、传送方式:get通过地址栏传输,post通过报文传输。
2、传送长度:get参数有长度限制(受限于url长度),而post无限制
3、GET和POST还有一个重大区别,简单的说:
GET产生一个TCP数据包;POST产生两个TCP数据包
长的说:
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
也就是说,GET只需要汽车跑一趟就把货送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼“嗨,我等下要送一批货来,你们打开门迎接我”,然后再回头把货送过去。
因为POST需要两步,时间上消耗的要多一点,看起来GET比POST更有效。因此Yahoo团队有推荐用GET替换POST来优化网站性能。但这是一个坑!跳入需谨慎。为什么?
-
GET与POST都有自己的语义,不能随便混用。
-
据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
-
并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
建议:
1、get方式的安全性较Post方式要差些,包含机密信息的话,建议用Post数据提交方式;
2、在做数据查询时,建议用Get方式;而在做数据添加、修改或删除时,建议用Post方式;
案例:一般情况下,登录的时候都是用的POST传输,涉及到密码传输,而页面查询的时候,如文章id查询文章,用get 地址栏的链接为:article.php?id=11,用post查询地址栏链接为:article.php, 不会将传输的数据展现出来。
拓展资料:
GET在浏览器回退时是无害的,而POST会再次提交请求。
GET产生的URL地址可以被Bookmark,而POST不可以。
GET请求会被浏览器主动cache,而POST不会,除非手动设置。
GET请求只能进行url编码,而POST支持多种编码方式。
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
GET请求在URL中传送的参数是有长度限制的,而POST么有。
对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
GET参数通过URL传递,POST放在Request body中。
-
-
-
TLS 在建立连接时是需要
- 客户端发送 ClientHello(包含支持的协议版本、加密算法和 随机数A (Client random))到服务端
- 服务端返回 ServerHello、公钥、证书、随机数B (Server random) 到客户端
- 客户端使用CA证书验证返回证书无误后。生成 随机数C (Premaster secret),用公钥对其加密,发送到服务端
- 服务端用 私钥 解密得到 随机数C (Premaster secret),随后根据已经得到的 随机数ABC生成对称密钥(hello的时候确定的加密算法),并对需要发送的数据进行对称加密发送
- 客户端使用对称密钥(客户端也用随机数ABC生成对称密钥)对数据进行解密。
- 双方手持对称密钥 使用对称加密算法通讯
而这一流程 服务端的证书 是是至关重要的。
-
证书用来证明公钥拥有者身份的凭证
首先我们需要知道 证书是怎么来的。
数字证书一般由数字证书认证机构签发,需要
- 申请者通过非对称加密算法(RSA) 生成一对公钥和密钥,然后把需要的申请信息(国家,域名等)连同公钥发送给 证书认证机构(CA)
- CA构确认无误后通过消息摘要算法(MD5,SHA) 生成整个申请信息的摘要签名M, 然后 把 签名M和使用的摘要算法 用 CA自己的私钥 进行加密
证书包含了
- 公钥
- 证书拥有者身份信息
- 数字证书认证机构(发行者)信息
- 发行者对这份文件的数字签名及使用的算法
- 有效期
-
1.服务器 用RSA生成公钥和私钥(RSA--非对称加密) 2.把公钥放在证书里发送给客户端,私钥自己保存 3.客户端首先向一个权威的服务器检查证书的合法性,如果证书合法,客户端产生一段随机数,这个随机数就作为通信的密钥,我们称之为对称密钥,用公钥加密这段随机数,然后发送到服务器 4.服务器用密钥解密获取对称密钥,然后,双方就已对称密钥进行加密解密通信了(最后通信用对称密钥进行加密通信) PS:非对称的RSA加密性能是非常低的,原因在于寻找大素数、大数计算、数据分割需要耗费很多的CPU周期,所以一般的HTTPS连接只在第一次握手时使用非对称加密,通过握手交换对称加密密钥,在之后的通信走对称加密。
-
1.浏览器将自己支持的一套加密规则发送给网站。 2.网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。 3.浏览器获得网站证书之后浏览器要做以下工作: a) 验证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等),如果证书受信任,则浏览器栏里面会显示一个小锁头,否则会给出证书不受信的提示。 b) 如果证书受信任,或者是用户接受了不受信的证书,浏览器会生成一串随机数的密码,并用证书中提供的公钥加密。 c) 使用约定好的HASH算法计算握手消息,并使用生成的随机数对消息进行加密,最后将之前生成的所有信息发送给网站。 4.网站接收浏览器发来的数据之后要做以下的操作: a) 使用自己的私钥将信息解密取出密码,使用密码解密浏览器发来的握手消息,并验证HASH是否与浏览器发来的一致。 b) 使用密码加密一段握手消息,发送给浏览器。 5.浏览器解密并计算握手消息的HASH,如果与服务端发来的HASH一致,此时握手过程结束,之后所有的通信数据将由之前浏览器生成的随机密码并利用对称加密算法进行加密。
-
1、证书是否是信任的有效证书。所谓信任:浏览器内置了信任的根证书,就是看看web服务器的证书是不是这些信任根发的或者信任根的二级证书机构颁发的。所谓有效,就是看看web服务器证书是否在有效期,是否被吊销了。 2、对方是不是上述证书的合法持有者。简单来说证明对方是否持有证书的对应私钥。验证方法两种,一种是对方签个名,我用证书验证签名;另外一种是用证书做个信封,看对方是否能解开。
以上的所有验证,除了验证证书是否吊销需要和CA关联,其他都可以自己完成。验证正式是否吊销可以采用黑名单方式或者OCSP方式。黑名单就是定期从CA下载一个名单列表,里面有吊销的证书序列号,自己在本地比对一下就行。优点是效率高。缺点是不实时。OCSP是实时连接CA去验证,优点是实时,缺点是效率不高。
-
-
HTTP和HTTPS不同 HTTP + SSL
-
HTTP请求是明文传输,HTTPS传输的是密文
-
对称加密 非对称加密
- 非对称加密是加密和解密不用一把密钥
-
HTTPS过程
-
客户端向服务端发送HTTPS请求,连接到443端口
-
服务端保留两把密钥,公钥可以发送,自己保留私钥
-
服务端将公钥发给客户端
-
客户端收到公钥进行检查
- 验证服务端发送的数字证书的合法性
-
客户端发起HTTPS第二个HTTP请求,将加密之后的客户端密钥发送给服务端
-
服务端用私钥进行解密,获取客户端密钥,用客户端密钥对数据进行加密
-
加密后的密文发送给客户端
-
客户端用密钥解密,得到数据
-
-
-
HTTP
- 请求行,请求头,请求体
- 请求行 请求方法 url http协议/版本
- 响应行,响应头,响应体
- 响应行 http协议/版本 响应码 描述
- 请求行,请求头,请求体
-
http长连接:
- keep-alive,1.1默认,之前是短连接,发起请求之后收到应答就断开,长连接不会断开,会等待同域名复用
-
http pipeline:
- 上一个请求不需要收到响应,就可以发出下一个请求
-
arp协议, icmp协议
-
客户端发fin一直失败怎么办
-
发fin失败会重发,如果一直失败会断开连接,如果服务端还向客户端写数据,会发RST报文,服务端出发sigpipe信号,需要处理,不然服务端会挂掉
-
大量TIME_WAIT原因,后果,解决
- TIME_WAIT作用:
- 保证tcp可靠关闭,如果客户端最后的ack报文没有服务端收到,服务端需要重传FIN,如果客户端已经关闭了就接受不到
- 上一次网络传输的数据不会被带到下一次
- 原因:
- 服务端主动关闭,比如关机
- 后果:
- 高并发短链接,导致文件描述符被占用过多,端口被占用
- 高并发让服务器短时间内占用大量端口
- 短链接代表业务处理和io时间短于2msl
- 解决:
- SO_REUSEADDR,通知内核,可重用端口
- 避免服务端主动关闭连接,因为timewait产生在主动关闭端
- ulimit -n 查看最大文件描述符, 改/etc/security/limits.conf配置文件
- SO_LINGER,优雅关闭,正常close如果send缓冲区还有数据,则会由内核接管然后保证数据发送到对端,SO_LINGER如果设置超时时间为0,则立即放弃缓冲区的数据,直接发送RST报文
- TIME_WAIT作用:
-
tcp四种定时器
-
超时重传定时器(丢失的报文)
-
坚持定时器(针对零窗口)
- 零窗口:发送方的发送速度大于接收方的接收速度,接收方缓冲塞满,告诉发送方不要再发送,窗口大小设为0
-
保活定时器(keepalive)
-
时间等待计时器(timewait)
-
-
TCP为什么是三次握手不是两次或者四次
-
我将一次握手理解为序列号的从一端到一端的发送,server在收到client 的seq号后,既需要发送对client序列号的ack即(seq+1),还需要发送自己的seq
-
为什么不是两次:
-


socket是双向管道,因此两次握手只能保证client端正确获取server的序列号即建立从client到server的单向可靠通信,当client发送消息在网络中丢弃或者重传,server会再建立连接
-
为什么不是四次:
四次即server发送ack和seq拆成两次发送,这样会造成效率的浪费
-
TCP序号的作用:
- 保证数据传输的顺序,接收方能按顺序接收到数据包
-
怎么检测客户端关闭:
- read到0
- epoll会出发epollin事件,read返回0说明客户端关闭
- epollerr说明服务端出现问题,才会被触发
-
路由器结构:
-
路由选择,分组转发
-
分组转发结构:交换结构,一组输入,一组输出
-
可以把路由选择协议划分为两大类:
- 自治系统内部的路由选择:RIP 和 OSPF
- 自治系统间的路由选择:BGP
-
路由器分组转发流程
- 从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
- 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
- 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
- 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
- 报告转发分组出错。
-
-
mysql事务 begin commit rollback
-
数据库意向锁
-
1、在MyISAM 引擎中只有表锁,
LOCK TABLE my_tabl_name READ; 用读锁锁表,会阻塞其他事务修改表数据。
LOCK TABLE my_table_name WRITe; 用写锁锁表,会阻塞其他事务读和写。
默认情况下读请求会加读锁,写请求写锁,并且是锁定整个表,因此大量读的业务这种引擎效率很高。
-
-
2.2、在Innodb引擎又支持行锁,行锁分为共享锁,一个事务对一行的共享只读锁。排它锁,一个事务对一行的排他读写锁。
3、这两中锁定类型的锁共存的问题
考虑这个例子:
事务A锁住了表中的一行,让这一行只能读,不能写。
之后,事务B申请整个表的写锁。
如果事务B申请成功,那么理论上它就能修改表中的任意一行,这与A持有的行锁是冲突的。
数据库需要避免这种冲突,就是说要让B的申请被阻塞,直到A释放了行锁。
数据库要怎么判断这个冲突呢?
step1:判断表是否已被其他事务用表锁锁表
step2:判断表中的每一行是否已被行锁锁住。
注意step2中通过遍历查询,这样的判断方法效率实在不高,因为需要遍历整个表。
于是就有了意向锁。
在意向锁存在的情况下,事务A必须先申请表的意向共享锁,成功后再申请一行的行锁。
在意向锁存在的情况下,上面的判断可以改成
step1:不变
step2:发现表上有意向共享锁,说明表中有些行被共享行锁锁住了,因此,事务B申请表的写锁会被阻塞。
最终结论:
(1)申请意向锁的动作是数据库完成的,就是说,事务A申请一行的行锁的时候,数据库会自动先开始申请表的意向锁,不需要我们程序员使用代码来申请。
(2)IX,IS是表级锁,不会和行级的X,S锁发生冲突。只会和表级的X,S发生冲突
行级别的X和S按照普通的共享、排他规则即可。所以之前的示例中第2步不会冲突,只要写操作不是同一行,就不会发生冲突。
备注: IX 意向排它锁,IS 意向读锁,X 排它锁,S 共享锁
-
数据死锁
-
数据库中常见的死锁原因与解决方案有:
\1. 事务之间对资源访问顺序的交替
出现原因: 一个用户A 访问表A(锁住了表A),然后又访问表B;另一个用户B 访问表B(锁住了表B),然后企图访问表A;这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B才能继续,同样用户B要等用户A释放表A才能继续,这就死锁就产生了。
解决方法: 这种死锁比较常见,是由于程序的BUG产生的,除了调整的程序的逻辑没有其它的办法。仔细分析程序的逻辑,对于数据库的多表操作时,尽量按照相同的顺序进行处理,尽量避免同时锁定两个资源,如操作A和B两张表时,总是按先A后B的顺序处理, 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源
\2. 并发修改同一记录
出现原因:主要是由于没有一次性申请够权限的锁导致的。参考:记录一次死锁排查过程
用户A查询一条纪录,然后修改该条纪录;这时用户B修改该条纪录,这时用户A的事务里锁的性质由查询的共享锁企图上升到独占锁,而用户B里的独占锁由于A有共享锁存在所以必须等A释放掉共享锁,而A由于B的独占锁而无法上升的独占锁也就不可能释放共享锁,于是出现了死锁。这种死锁比较隐蔽,但在稍大点的项目中经常发生。
解决方法:
a. 乐观锁,实现写-写并发
b. 悲观锁:使用悲观锁进行控制。悲观锁大多数情况下依靠数据库的锁机制实现,如Oracle的Select … for update语句,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。
\3. 索引不当导致的死锁
出现原因: 如果在事务中执行了一条不满足条件的语句,执行全表扫描,把行级锁上升为表级锁,多个这样的事务执行后,就很容易产生死锁和阻塞。类似的情况还有当表中的数据量非常庞大而索引建的过少或不合适的时候,使得经常发生全表扫描,最终应用系统会越来越慢,最终发生阻塞或死锁。
另外一种情况是由于二级索引的存在,上锁的顺序不同导致的,这部分在讨论索引时会提到。参考:https://www.cnblogs.com/LBSer/p/5183300.html
解决方法:
SQL语句中不要使用太复杂的关联多表的查询;使用“执行计划”对SQL语句进行分析,对于有全表扫描的SQL语句,建立相应的索引进行优化。
那么,如何尽可能的避免死锁呢?
1)以固定的顺序访问表和行。即按顺序申请锁,这样就不会造成互相等待的场面。
2)大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
3)在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率。
4)降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁。
5)为表添加合理的索引。如果不走索引将会为表的每一行记录添加上锁,死锁的概率大大增大。
-
-
数据库查询优化方法
-
用explain 分析
-
加索引
-
大表拆分
- 水平--根据规则去相应表取数据
- 垂直--把活跃数据和非活跃数据拆出来
-
数据避免请求过量,比如select *优化成有用的列
-
大查询切换成小查询
-
分解联合查询
-
用分解关联查询的方式重构查询具有如下优势:
-
(高并发、高性能的应用中,一般建议使用单表查询)
\1. 让缓存的效率更高。
许多应用程序可以方便地缓存单表查询对应的结果对象。另外对于MySQL的查询缓存来说,如果关联中的某个表发生了变化,那么就无法使用查询缓存了,而拆分后,如果某个表很少改变,那么基于该表的查询就可以重复利用查询缓存结果了。
\2. 将查询分解后,执行单个查询可以减少锁的竞争。
\3. 在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
\4. 查询本身效率也可能会有所提升。
\5. 可以减少冗余记录的查询。
\6. 更进一步,这样做相当于在应用中实现了哈希关联,而不是使用MySQL的嵌套环关联,某些场景哈希关联的效率更高很多。
\7. 单表查询有利于后期数据量大了分库分表,如果联合查询的话,一旦分库,原来的sql都需要改动。
\8. 上次看到某个CTO技术分享,公司规定底层禁止用join联合查询。数据大的时候确实慢。
\9. 联合查询或许确实快,但是mysql的资源通常比程序代码的资源紧张的多。
-
-
-
MyIsam和InnoDB区别
- https://blog.csdn.net/qq_35642036/article/details/82820178
- InnoDB支持事务,MyIsam不支持事务
- InnoDB是主键索引是聚簇索引,数据文件和主键索引绑到一起,主键索引可以直接找到数据文件,辅助索引需要查两次表,先查到主键再通过主键查到数据,因此主键不应该过大.主键索引叶子节点保存的是数据文件,辅助索引叶子节点保存的是主键的值
- MyIsam是非聚集索引,索引和数据文件是分离的,叶子节点保存的是数据文件的指针.
- MyIsam全文索引效率更高
- InnoDB支持表,行级锁,默认是行级锁,MyIsam只支持表级锁,InnoDB的行锁是实现在索引上的,而不是锁在物理行上的,如果没有命中索引,无法使用行锁,会退化成表锁.
- InnoDB表必须有主键,没有指定的话会自己找或生产一个主键,MyIsam可以没有主键
-
选择引擎
- 支持事务选InnoDB
- 大多数是读查询选MyIsam,有读有写选InnoDB
- MyIsam难以恢复
-
InnoDB推荐使用自增id作为主键
- 自增id保证每次插入时B+索引是从右边扩展的,避免b+树的频繁合并和分裂,如果使用字符串主键和随机逐渐,使得数据随机插入,效率差
-
INNODB四大特性
- 插入缓冲,二次写,自适应哈希索引,预读
-
binlog redolog
- binlog用于归档,在Server层,存的是sql(不一定是sql),容量无限,追加写入
- redolog用于崩溃恢复,在引擎层,是物理日志,容量有限,循环写入
- 当数据库对数据做修改的时候,需要把数据页从磁盘读到buffer pool中,然后在buffer pool中进行修改,那么这个时候buffer pool中的数据页就与磁盘上的数据页内容不一致,称buffer pool的数据页为dirty page 脏数据,如果这个时候发生非正常的DB服务重启,那么这些数据还没在内存,并没有同步到磁盘文件中(注意,同步到磁盘文件是个随机IO),也就是会发生数据丢失,如果这个时候,能够在有一个文件,当buffer pool 中的data page变更结束后,把相应修改记录记录到这个文件(注意,记录日志是顺序IO),那么当DB服务发生crash的情况,恢复DB的时候,也可以根据这个文件的记录内容,重新应用到磁盘文件,数据保持一致。
- undo 用于回滚,存放修改的值,mvcc快照读
-
随机io
- 顺序IO是指读取和写入操作基于逻辑块逐个连续访问来自相邻地址的数据.在顺序IO访问中,HDD所需的磁道搜索时间显着减少,因为读/写磁头可以以最小的移动访问下一个块。数据备份和日志记录等业务是顺序IO业务。
- 随机IO是指读写操作时间连续,但访问地址不连续,随机分布在磁盘LUN的地址空间中。产生随机IO的业务有OLTP服务,SQL,即时消息服务等。
-
码,主键,候选键,关键字,主属性
主码=主键=主关键字,关键字=候选码 候选关键字=候选码中除去主码的其他候选码 码:唯一标识实体的属性或属性组合称为码 候选码(关键字):某一属性组的值能唯一标识一个元组而其子集不能(去掉任意一个属性都不能标识该元组),则称该属性组为候选码(补充元组:表中的一行即为一个元组) 主属性:候选码包含的属性(一个或多个属性) 主码(主键、主关键字):若一个关系有多个候选码,选择其中一个为主码 -
索引的实现
-
数据库范式
1NF:字段不可分;
2NF:有主键,非主键字段依赖主键;
3NF:非主键字段不能相互依赖;
解释:
1NF:原子性 字段不可再分,否则就不是关系数据库;
2NF:唯一性 一个表只说明一个事物; 3NF:每列都与主键有直接关系,不存在传递依赖;2NF:非主键列是否完全依赖于bai主键,还是依赖于主键的一部分;3NF:非主键列是直接依赖于主键,还是直接依赖于非主键列。
第二范式(2NF):首先是 1NF,另外包含两部分内容,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。考虑一个订单明细表OrderDetail其属性如下: (OrderID,ProductID,UnitPrice,Discount,Quantity,ProductName)。 因为我们知道在一个订单中可以订购多种产品,所以单单一个OrderID 是不足以成为主键的,主键应该是(OrderID,ProductID)。显而易见 Discount(折扣),Quantity(数量)完全依赖(取决)于主键(OderID,ProductID),而 UnitPrice,ProductName 只依赖于 ProductID。所以 OrderDetail 表不符合 2NF。不符合 2NF的设计容易产生冗余数据。
可以把OrderDetail表拆分为:
OrderDetail(OrderID,ProductID,Discount,Quantity) Product (ProductID,UnitPrice,ProductName)来消除原订单表中UnitPrice,ProductName多次重复的情况。 第三范式(3NF):首先是 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。考虑一个订单表Order: (OrderID,OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity)主键是(OrderID)。 其中OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity 等非主键列都完全依赖于主键(OrderID),所以符合 2NF。
不过问题是CustomerName,CustomerAddr,CustomerCity 直接依赖的是 CustomerID(非主键列),而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合 3NF。
-
linux指令
-
1.简单说下什么是最左匹配原则 顾名思义:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。 例如:b = 2 如果建立(a,b)顺序的索引,是匹配不到(a,b)索引的;但是如果查询条件是a = 1 and b = 2或者a=1(又或者是b = 2 and b = 1)就可以,因为优化器会自动调整a,b的顺序。再比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。
2.最左匹配原则的原理 最左匹配原则都是针对联合索引来说的,所以我们有必要了解一下联合索引的原理。了解了联合索引,那么为什么会有最左匹配原则这种说法也就理解了。
我们都知道索引的底层是一颗B+树,那么联合索引当然还是一颗B+树,只不过联合索引的健值数量不是一个,而是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。 例子:假如创建一个(a,b)的联合索引,那么它的索引树是这样的
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
-
聚簇索引,非聚簇索引
- 聚簇索引,索引的顺序就是数据存放的顺序(物理顺序),只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。一张数据表只能有一个聚簇索引。(一个数据页中数据物理存储是有序的)
-
非聚簇索引通过叶子节点指针找到数据页中的数据,所以非聚簇索引是逻辑顺序。
-
主键索引,唯一索引,组合索引
- 主键索引一定唯一,一定不为null,只能有一个主键索引
- 唯一索引,索引值是唯一的,可以为NULL,可以有多个唯一索引
- 组合索引,一个索引包含多个列,最左匹配原则,比如索引是a,b,c则实际是索引组合a, ab, abc
-
哪些字段加索引:
-
主键,外键,where,group by, order by
-
主键和外键建立索引是因为相对的这两个值比较能确定一些数据,所以比较适合建立索引;
where条件中的字段适合建立索引是因为要在查询过程中减少数据检索,需要使用索引;
-
不能盲目加索引,因为建立索引有开销,维护索引有开销
-
链接:https://www.nowcoder.com/questionTerminal/91e1c256e2764c5a8217533b584bead5?from=14pdf
-
1、表的主键、外键必须有索引; 2、数据量超过300的表应该有索引; 3、经常与其他表进行连接的表,在连接字段上应该建立索引; 4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引; 5、索引应该建在选择性高的字段上; 6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引; 7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替
-
索引优劣:
1、表的主键、外键必须有索引; 2、数据量超过300的表应该有索引; 3、经常与其他表进行连接的表,在连接字段上应该建立索引; 4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引; 5、索引应该建在选择性高的字段上; 6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引; 7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替
-
索引优劣:
- 优点 - 加快检索速度 - 唯一索引可以保证数据库中每一行数据的唯一性 - 加速表与表之间的连接
-
缺点
- 索引占物理空间
- 当数据库增删改,索引也要动态维护,降低维护效率
- 创建索引,维护索引需要花费时间
-
怎么添加索引 主键索引索引着数据,然后普通索引索引着主键ID值(这是在innodb中,但是如果是myisam中,主键索引和普通索引是没有区别的都是直接索引着数据)
alter table `student` add primary key(`id`) #增加主键索引 ALTER TABLE `table_name` ADD UNIQUE (`id`)#增加唯一索引 ALTER TABLE `table_name` ADD INDEX index_name ( `id` )#增加普通索引 ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )#增加多列索引
-
mysql半同步
- mysql主从同步本身是一个异步的过程,主节点发送完binlog后立刻返回,有可能从服务器没有收到主服务器发来的binlog,从而导致主从数据库不一致
-
对于异步复制,主库将事务Binlog事件写入到Binlog文件中,此时主库只会通知一下Dump线程发送这些新的Binlog,然后主库就会继续处理提交操作,而此时不会保证这些Binlog传到任何一个从库节点上。
-
对于全同步复制,当主库提交事务之后,所有的从库节点必须收到,APPLY并且提交这些事务,然后主库线程才能继续做后续操作。这里面有一个很明显的缺点就是,主库完成一个事务的时间被拉长,性能降低。
-
对于半同步复制,是介于全同步复制和异步复制之间的一种,主库只需要等待至少一个从库节点收到并且Flush Binlog到Relay Log文件即可,主库不需要等待所有从库给主库反馈。同时,这里只是一个收到的反馈,而不是已经完全执行并且提交的反馈,这样就节省了很多时间。
-
mysql半同步在主库执行完binlog后,收到一个从库的ack才返回给客户端,确保事务提交后的binlog至少传输到一个从库
- 网络异常或从库宕机,卡主库,直到超时或从库恢复
-
mysql主从同步
- 前提:主数据库开启二进制日志
- 主服务器上的任何修改通过自己的io线程保存到二进制日志里
- 从服务器也启动一个io线程,连接到主服务器请求读取二进制文件,写道本地的中继日志(realy log)里
- 从服务器开启一个sql线程定时检查中继日志,如果有更改在本服务器执行
- 每个从服务器会记录二进制日志坐标
- 文件名
- 文件中已经从主服务器读取的位置
- 如果一主多从,可以主的日志写给一个从,这个从再写到别的从服务器
- 复制原理:
- 三个线程,第一个线程,binlog转储线程,把主机Binlog转发给从服务器
- 从属io线程 该线程连接到主服务器并请求把binlog的更新发送给从服务器,并复制到本地的中继日志
- 从属sql线程 读取中继日志,并执行
- 当从属服务器追上主服务器,从服务器睡眠
-
mysql查找慢的原因,怎么优化
-
乐观锁,悲观锁
- 乐观锁总是认为不会产生并发问题,每次去取数据不会认为有其他线程对数据进行修改,因此不会上锁,但是在更新时会判断其他线程在这之前有没有对数据进行修改,使用版本号或者CAS操作
- 悲观锁,每次拿数据都认为别人会修改,所以每次拿数据都会上锁
-
脏读,不可重复读,幻读
- 脏读:一个事务对数据库进行了修改,还未提交时,另一个事务对数据库读
- 不可重复读:在一个事务内对一个数据多次读.在这个事务还未结束时,另一个事务对数据库进行了修改,两次读的数据可能是不一样的
- 幻读:第一个事物对数据库表进行了处理,这时候第二个事务向数据库插入数据,第一个事务发现还有未修改的数据
-
隔离级别:
- 读未提交:事务中的修改即使未提交,对其他事务也是可见的
- 读已提交:一个事务只能读取已经提交的修改
- 可重复读:保证在同一个事务中多次读取的数据是一样的
- 可串行化:强制事务串行执行,不会出现一致性问题,需要加锁实现
-
当前读 像select lock in share mode(共享锁), select for update ; update, insert ,delete(排他锁)这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。
快照读 像不加锁的select操作就是快照读,即不加锁的非阻塞读;快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读;之所以出现快照读的情况,是基于提高并发性能的考虑,快照读的实现是基于多版本并发控制,即MVCC,可以认为MVCC是行锁的一个变种,但它在很多情况下,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本
快照读是针对上文的当前读而言,指的是在RR隔离级别下,在不加锁的情况下MySQL会根据回滚指针选择从undo log记录中获取快照数据,而不总是获取最新的数据,这也就是为什么另一个事务提交了数据,在当前事务中看到的依然是另一个事务提交之前的数据。
-
mvcc
- 用于实现可提交读和可重复读
- 解决幻读可以用mvcc加上间隙锁,由于幻读是插入数据行,所以需要用间隙锁
- 读读不互斥,读写再互斥
- mvcc规定只能读取已经提交的快照
- 系统版本号是一个递增的数字,每开始一个新的事务,系统版本号就会递增
- 事物版本号,事务开始时的系统版本号(删除标记,版本号,当delete时,删除标记设为1,设置回滚指针,回滚指针指向Undo log)
- select
- 当查询的事务版本号大于行的版本号,可以查询
- 当查询的事务版本号小于行的版本号,说明查询的时候已经有别的事务提交过这行数据,那么不查此时的行的数据,需要读快照,读老数据
- 当查询的版本号小于删除版本号或者没有删除版本号,可以查询
- 当查询的版本号大于删除版本号,说明此行数据已经被别的事务删除了,那么需要去读快照读老数据
- insert
- 为插入的每一行数据吧保存当前的系统版本号作为行版本号
- delete
- 删除的每一行保存当前的系统版本号作为行的删除标志
- update
- 插入一行新数据,保存当前系统版本号作为新插入行的版本号
- select
-
为什么用自增id作为主键
对InnoDB来说 1: 主键索引既存储索引值,又在叶子节点中存储行的数据,也就是说数据文件本身就是按照b+树方式存放数据的。 2: 如果没有定义主键,则会使用非空的UNIQUE键做主键 ; 如果没有非空的UNIQUE键,则系统生成一个6字节的rowid做主键; 聚簇索引中,N行形成一个页(一页通常大小为16K)。如果碰到不规则数据插入时,为了保持B+树的平衡,会造成频繁的页分裂和页旋转,插入速度比较慢。所以聚簇索引的主键值应尽量是连续增长的值,而不是随机值(不要用随机字符串或UUID)。 故对于InnoDB的主键,尽量用整型,而且是递增的整型。这样在存储/查询上都是非常高效的。
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。 总的来说就是可以提高查询和插入的性能。
-
页分裂:
- 如果主键不是增加的,那么插入会造成页分裂,因为B+树要保证有序
-
页合并:
- 删除数据,会造成页合并
-
用b+树不用哈希:
- 哈希做不了范围查询,比如 where id < 5,只能做等值查询
- 联合索引只有都覆盖才行比如(a, b),只有查询a, b 才可以,查询a不能走索引
- 哈希是散列的不是排序的,所以不能排序,不能范围查询
-
自适应哈希索引:
- 如果某一个索引值使用频繁,额外创建一个哈希索引
-
这里我们就需要了解页(page)的概念,在计算机里,无论是内存还是磁盘,操作系统都是按页的大小进行读取的(页大小通常为 4 kb),磁盘每次读取都会预读,会提前将连续的数据读入内存中,这样就避免了多次 IO,这就是计算机中有名的局部性原理,即我用到一块数据,很大可能这块数据附近的数据也会被用到,干脆一起加载,省得多次 IO 拖慢速度, 这个连续数据有多大呢,必须是操作系统页大小的整数倍,这个连续数据就是 MySQL 的页,默认值为 16 KB,也就是说对于 B+ 树的节点,最好设置成页的大小(16 KB),这样一个 B+ 树上的节点就只会有一次 IO 读。
-
全文索引:
- 倒排索引
-
m阶B+树定义
B+树是B树的一种变形形式,m阶B+树满足以下条件:
(1) 每个结点至多有m个孩子。
(2) 除根节点和叶结点外,每个结点至少有(m+1)/2个孩子。
(3) 如果根节点不为空,根结点至少有两个孩子。
(4) 所有叶子结点增加一个链指针,所有关键字都在叶子结点出现。
(5) 除了叶节点,结点的孩子数目等于关键字数目。 注意,B+树中非叶子结点存储的不是关键字数据的地址,而是指向叶子结点中关键字的索引。(所以任何关键字的查找必须走一条从根结点到叶子结点的路)
b树的非叶子节点存数据
-
优点
- B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
- B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
- B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
- B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
- 支持范围查询
-
哈希冲突
-
跳表
-
为什么redis用跳表不用红黑树
- 范围查询跳表要好于红黑树
- 插入删除相对简单
-
布隆过滤器:
- k个哈希函数,得到k个值,去位图找,如果不都是1则一定不存在,如果是1不一定存在
-
b+树,b+和b树和红黑树 重点看
-
红黑树
- 每个节点红色或者黑色
- 根节点是黑色
- 红色节点的儿子是黑色
- 从任意节点到叶子节点的路径包含相同的黑色节点
- 从根节点到叶子节点的最远路径最长不会超过最近路径的二倍,高度差不会是二倍
-
b+树
- 为什么索引用b树不用平衡二叉树或者红黑树
- 索引在文件上,是在磁盘上的,索引通常很大,无法一次将全部索引加载到内存中,每次从磁盘读取一个页到内存中,磁盘读取的速度较内存的读取速度差了很多
- 逻辑结构相近的节点在物理结构上可能差很远,因此需要做多次的磁盘读取
- io操作次数更多
- 利用磁盘预读
- 磁盘会预读,顺序向后多读取一定的长度放入内存,磁盘顺序读取效率较高,不需要寻道
- 找盘面,找扇区,机械过程慢与电子信号
- b+树叶子节点为双向链表
- b+树索引不能找到键对应的具体值,只能找到数据行对应的页,然后把页读入到内存
- 聚集索引叶节点,按表中主键的顺序构建b+树,保存的是整条行记录,将数据与索引存储到一块,找到索引也就找到了数据页
- 非聚簇索引,叶节点不保存行记录的数据,仅包含索引中的所有键和查找行记录的主键,索引叶节点指向了数据的对应行
- 回表:检索非聚簇索引获得主键,用主键在主索引中获得记录
- 聚簇索引,表中存储的数据按照索引的顺序存储,对数据新增修改删除的影响比较大,非聚簇索引,检索效率低,对数据新增,删除修改的影响小
- b+树比b树的优点,只有叶子节点存有信息,盘块能容纳的关键字更多,磁盘io次数更少,遍历叶子节点就可以遍历数据
- 为什么索引用b树不用平衡二叉树或者红黑树
-
虚函数表,虚继承
-
inline:
- 解决频繁调用的函数消耗内存栈空间,函数调用栈帧
- 只是提示编译器
- 将代码替换省去了函数调用开销,函数代码放入符号表
- 以代码膨胀复制为代价
- 不能virtual,不能for, 不能递归
-
指针,引用
-
main函数执行之前:全局,静态变量完成初始化,arg argv参数传完毕,堆内存栈内存完成初始化,io初始化
代码列子
class Demo { public: Demo() { cout << "demo" << endl; } }; int foo() { cout << "s" << endl; return 0; } int x = foo(); Demo d; int main() { return 0; }
- 如何防止内存泄漏
- 静态库动态库,静态库 动态库的区别
- ```makefile
all:sum print lib main clean
main:./main.cc ./lib/libxxx.a
g++ main.cc -I include -L lib -lxxx -o main.prog
sum:./src/sum.cc ./include/sum.h
g++ -I include ./src/sum.cc -c -o sum
print:./src/print.cc ./include/print.h
g++ -I include ./src/print.cc -c -o print
lib:./sum.o ./print.o
ar rcs ./lib/libxxx.a ./sum.o ./print.o
clean:
rm -f ./*.o
-
静态库是链接到可执行文件,程序运行时不需要静态库,但是源文件需要重新编译,做成静态库可执行文件体积大,不需要依赖静态库
- 动态库在目标文件编译之后不需要链接,而是程序运行时动态链接,程序运行时需要动态库存在,因此源文件不需要重新编译,做成动态库可执行文件体积小,但是依赖动态库.在调用函数时,根据函数映射表找到函数
-
vector内存分配,分配一个2倍大小数组,把原数组元素copy过去,所以元素引用不可以,因为内存可能发生变化 1.引用不满足值语义。值语义(value sematics)指的是对象的拷贝与原对象无关,就像拷贝 int 一样。 2.就算可以你如何初始化,你不可能里面存放引用为空的引用。
-
两个.h同时定义一个static变量会怎样 如果有一个源文件引用两个头文件编译失败,如果是两个源文件分别引用一个,然后编译生产一个elf文件,则没有问题,如果不定义为Static则链接会出错报重定义
-
static函数,static函数不能在本代码文件以外的代码文件使用,普通函数默认是extern的可以被别的代码文件使用,其他文件可以定义相同名字的函数 https://www.cnblogs.com/nzbbody/p/3413169.html
-
虚表,虚继承,虚指针,虚基类表指针,虚基类表
-
虚表 每个类有一个虚表,每个对象有一个虚指针,虚表在数据段,虚函数在代码段https://blog.csdn.net/primeprime/article/details/80776625
-
虚继承,虚基类类表,指针 虚基类表存的是虚基类相对子类的偏移,虚函数表存的是虚函数指针,虚继承维持一份拷贝,虚继承只有虚基类指针没有虚表指针,通过虚基类表找到基类虚表https://blog.csdn.net/qq_36359022/article/details/81870219
-
重载重写多太 重载函数签名不同 多太:运行期,预编译期模板,函数重载
-
手写string类
class String { private: char* data; int length; public: String(const char* src) { if (src == nullptr) { length = 0; data = new char[1]; *data = '\0'; } else { length = strlen(src); data = new char[length + 1]; strcpy(data, src); } } const char* c_str() { return data; } int size() { return length; } String(const String& src) { char* d = src.c_str(); length = src.size(); data = new char[length + 1]; strcpy(data, d); } String& operator= (const String& src) { if (this == &str) { return *this; } delete[] data; char* d = src.c_str(); length = src.size(); data = new char[length + 1]; strcpy(data, d); return *this; } char& operator[](int n) const { if (n >= length) { return data[length - 1]; } else { return data[n] } } String operator+(const String& str) const { String newString; newString.size() = length + str.size(); newString.c_str() = new char[newString.size() + 1]; strcpy(newString.c_str(), data); strcat(newString.c_str(), str.c_str()); return newString; } bool operator=(const String& str) { if (str.size() != length) { return false; } return strcmp(data, str.c_str()) ? false : true; } };
-
单例双检查
class Singlenton { private: Singlenton() { } Singlenton(const Singlenton&) { } Singlenton& operator=(const Singlenton&) { } mutex m; public: static Singlenton* single; Singlenton* getSingenton() { if (single != nullptr) { m.lock(); if (single != nullptr) { single = new Singlenton; } m.unlock(); } return single; } }; Singlenton* Singlenton::single;
-
深拷贝 浅拷贝
-
memcpy, memmove,strcpy,strcat 手写
- strcpy以'\0'结尾,memcpy memmove以num结尾
- memmove可以解决内存覆盖,memcpy不可以
char* strcpy(char* dest, const char* src) { if (dest == NULL || src == NULL) { return NULL; } char* tmp = dest; while ((*dest++ = *src++) != '\0'); return dest; }
char* strcat(char* dest, const char* src) { if (dest == nullptr || src == nullptr) { throw "error"; } char* tmp = dest; while (*tmp != '\0') { tmp++; } while ((*tmp++ = *src++) != '\0'); return dest; }
void* memcpy(void* dest, const void* src, int len) { if (dest == nullptr || src == nullptr || len <= 0) { return nullptr; } char* d = (char*)dest; const char* s = (char*)src; if (d > s && d < s + len) { d = (char*)(dest + len - 1); s = (char*)(src + len - 1); while (count--) { *d-- = *s--; } } else { while (count--) { *d++ = *s++; } } return dest; }
-
析构函数不要抛出异常
- 如果析构函数抛出异常,则异常点之后的程序不会执行,如果析构函数在异常点之后执行了某些必要的动作比如释放某些资源,则这些动作不会执行,会造成诸如资源泄漏的问题。
- 通常如果发生异常会调用析构函数来释放资源,如果此时析构函数本身抛出异常,则前一个异常没有处理又来了新的异常
-
函数调用过程
-
将参数从右向左入栈
-
返回地址入栈,将当前代码区调用指令的下一条指令地址压入栈中,供函数返回时继续执行
-
代码区跳转,执行调用函数
-
栈帧调整
-
EBP(基址指针寄存器,内存里面存放一个指针)系统栈最上面的栈帧的底部,ESP栈顶寄存器内存里面存指针,指向系统栈最上面的栈帧的顶部
-
保存当前栈帧状态值,以备后面恢复本栈帧使用(EBP入栈)
-
将当前栈帧切换到新栈帧(将ESP装入EBP,更新栈帧底部)
-
给新栈帧分配空间(把EBP减去所需空间大小,抬高栈顶)
-
-
-
c++11特性
-
四种cast
- const_cast 消除常量性
- static_cast
- 没有运行时类型检查 无法保证安全性
- 基本数据类型,或者non const -> const(const -> non const必须const cast)
- 空指针转换为目标类型指针
- 任何类型转为void
- 子类指针转父类指针
- dynamic_cast:只用于对象和引用,父类指针转换为子类指针,要求父类有虚函数
- reinpreter_cast:指针引用函数指针算数类型成员指针,二进制拷贝.
-
智能指针
- shared_ptr:共享,多个智能指针指向相同对象,最后一个引用被销毁才释放资源
- unique_ptr:独占式,同一时刻只有一个智能指针指向该对象
- weak_ptr:共享但不拥有某对象,当shared_ptr最后一个释放资源,weak_ptr失效
- 可打破循环引用,即两个对象互值,造成还在使用的假象,造成内存泄漏
-
什么是循环引用,为什么weak_ptr可以解决循环引用
-
define和typedef
- define是预处理,只进行字符串替换,不进行正确性检查,只有在编译期展开编译器才会发现
- typedef一般用来给变量类别起别名,define还可以用来宏开关,定义常量
- typedef有自己的作用域,define没有
-
位域
-
typedef struct Test { char a : 1; char b : 1; char c : 1; }Test;
-
a b c各占一位 节省空间,位域不能跨字节存储,也不能跨类型
-
-
枚举
-
c++98和c++11不同
-
enum是全局的
-
enum A { yellow, red }; enum B { yellow }; 编译失败,yellow重复定义,可以用Namespace结局
-
允许隐式转换为int,可能不安全
-
c++11强enum类型
-
enum class A { yello, white };
-
强enum特点:强作用域,解决全局空间问题.不可以与Int隐式转换,可以强制转换
-
-
-
constexpr:
-
修饰变量,函数.构造函数,相当于告诉编译器将它修饰的当作在编译期就能得出的常量值去优化
-
constexpr int func() { return 10; } main(){ int arr[func()]; } //编译通过 编译期就确定func返回值是10无需等到运行期计算
-
const只表示const修饰的在运行期不被更改,但是可能还是个变量,constexpt表示在编译期就得到值
-
-
右值引用:只能绑定右值的引用
-
const T&常量左值,既能绑定右值,又可以绑定左值
-
已命名的右值引用是左值
-
移动语义:移动构造和移动赋值将自己的指针指向这个资源,将别的指针指向Null将这个资源的所有权偷过来
class Demo { public: int* data; public: Demo(Demo&& src) noexpect : data(src.data) { src.data = nullptr; } };
-
-
decltype:
- 推断出该变量的类型,但是不初始化,auto需要初始化,auto忽略顶层const,decltype保留顶层const,对引用,auto推断出原有类型,decltype推断出引用
-
noexpect:
-
告诉编译器,函数不可以抛出任何异常,编译器会对代码进行优化,减小生成目标文件体积
-
空间配置器:
- 一级空间配置器:大于128字节
- 调用malloc和free,realloc分配内存,当内存不足可以自定义函数
- 一级调用失败时,调用oom_alloc函数尝试清理,如果失败,抛出bad_alloc异常
- 二级空间配置器:小于128字节
- 16个元素的自由链表,每个节点挂载着大小为(8,16, .., 128)的内存块
- 将客端申请的内存提升到8的倍数,如果对应的链表有内存块就分给客端
- 如果对应的链表没有内存块,并且内存池有足够的内存,则取出20块内存,19块放到链表上,一块给客端
- 如果内存池中不够20块但是够1块,就拿出来一块给客端然后把剩下的放到链表上
- 如果一个内存块都不够了,则将剩下的内存挂载到相应的链表下,然后申请内存
- 如果内存池内存没有,需要申请内存,申请20个所需要内存的内存块*2个大小的内存比如需要16b则申请 2 * 16 * 20b字节,20个节点放到内存池,19个内存挂载到链表,1个内存返回给客端
- 如果内存池申请内存失败,说明Malloc内存失败内存不够,则从大于这个节点的节点分配出足够的内存,返回给客端
- 如果内存分配失败并且大于这个节点的节点也没有内存了,调用oom_allocate清理内存,如果再失败说明没有内存可用了
- 一级空间配置器:大于128字节
-
explict:
- 构造函数只能是显示构造,默认是隐式构造的
-
final:
-
class Base final { }; Base类不会被继承
-
class Base { public: virtual void foo final { } }; Base类的foo方法不会被重写
-
-
delete[] 和 delete
- delete删除数组会造成内存泄漏,只调用了一个对象的析构函数,只删除了一块内存
-
new[]
- new[10] 内存对象模型,会先有一个数组大小的记录,然后是10个object,如下所示
- [10] [object] [object] [object] [object] [object] [object] [object] [object] [object] [object]
- 因此delete[]的时候知道调用多少个析够函数
-
GC
1、引用计数算法(Reference counting) 每个对象在创建的时候,就给这个对象绑定一个计数器。每当有一个引用指向该对象时,计数器加一;每当有一个指向它的引用被删除时,计数器减一。这样,当没有引用指向该对象时,该对象死亡,计数器为0,这时就应该对这个对象进行垃圾回收操作。
2、标记–清除算法(Mark-Sweep) 为每个对象存储一个标记位,记录对象的状态(活着或是死亡)。 分为两个阶段,一个是标记阶段,这个阶段内,为每个对象更新标记位,检查对象是否死亡;第二个阶段是清除阶段,该阶段对死亡的对象进行清除,执行 GC 操作。
3、标记–整理算法 标记-整理法是标记-清除法的一个改进版。同样,在标记阶段,该算法也将所有对象标记为存活和死亡两种状态;不同的是,在第二个阶段,该算法并没有直接对死亡的对象进行清理,而是将所有存活的对象整理一下,放到另一处空间,然后把剩下的所有对象全部清除。这样就达到了标记-整理的目的。
4、复制算法 该算法将内存平均分成两部分,然后每次只使用其中的一部分,当这部分内存满的时候,将内存中所有存活的对象复制到另一个内存中,然后将之前的内存清空,只使用这部分内存,循环下去。
这个算法与标记-整理算法的区别在于,该算法不是在同一个区域复制,而是将所有存活的对象复制到另一个区域内。
5、JVM不同的版本垃圾回收机制不一样,jdk1.7和1.8新版本和老版本区别 jdk1.7和1.8旧版本Parallel Old,(老年代) jdk1.7和1.8新版本Parallel Scavenge,(新生代)
Parallel Old 收集器 Parallel Scavenge收集器的老年代版,使用多线程与标记–整理算法。这个收集器在jdk1.6中才开始提供的,直到Parallel Old 收集器出现后,“吞吐量优先”收集器终于有了比较名副其实的应用组合,在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge加 Parallel Old收集器
Parallel Scavenge收集器 Parallel Scavenge收集器是一个新生代的手机器,使用的是复制算法的收集器,而且也是多线程的收集器。。Parallel Scavenge收集器,目标达到一个可控制的吞吐量,使用-XX:MaxGCPauseMillus参数控制垃圾停顿时间,使用-XX:GCTimeRatio参数控制吞吐量。Parallel Scavenge收集器设置-XX:UseAdaptiveSizePolicy参数,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大吞吐量(GC自使用的调节策略)。 自适应调节策略也是Parallel Scavenge收集器和ParNew收集器一个重要的区别。
-
1.为什么会有年轻代
我们先来屡屡,为什么需要把堆分代?不分代不能完成他所做的事情么?其实不分代完全可以,分代的唯一理由就是优化GC性能。你先想想,如果没有分代,那我们所有的对象都在一块,GC的时候我们要找到哪些对象没用,这样就会对堆的所有区域进行扫描。而我们的很多对象都是朝生夕死的,如果分代的话,我们把新创建的对象放到某一地方,当GC的时候先把这块存“朝生夕死”对象的区域进行回收,这样就会腾出很大的空间出来。
2.年轻代中的GC
HotSpot JVM把年轻代分为了三部分:1个Eden区和2个Survivor区(分别叫from和to)。默认比例为8:1,为啥默认会是这个比例,接下来我们会聊到。一般情况下,新创建的对象都会被分配到Eden区(一些大对象特殊处理),这些对象经过第一次Minor GC后,如果仍然存活,将会被移到Survivor区。对象在Survivor区中每熬过一次Minor GC,年龄就会增加1岁,当它的年龄增加到一定程度时,就会被移动到年老代中。
因为年轻代中的对象基本都是朝生夕死的(80%以上),所以在年轻代的垃圾回收算法使用的是复制算法,复制算法的基本思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还活着的对象复制到另外一块上面。复制算法不会产生内存碎片。
在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,“To”区被填满之后,会将所有对象移动到年老代中。
3.一个对象的这一辈子
我是一个普通的java对象,我出生在Eden区,在Eden区我还看到和我长的很像的小兄弟,我们在Eden区中玩了挺长时间。有一天Eden区中的人实在是太多了,我就被迫去了Survivor区的“From”区,自从去了Survivor区,我就开始漂了,有时候在Survivor的“From”区,有时候在Survivor的“To”区,居无定所。直到我18岁的时候,爸爸说我成人了,该去社会上闯闯了。于是我就去了年老代那边,年老代里,人很多,并且年龄都挺大的,我在这里也认识了很多人。在年老代里,我生活了20年(每次GC加一岁),然后被回收。
4.有关年轻代的JVM参数
1)-XX:NewSize和-XX:MaxNewSize
用于设置年轻代的大小,建议设为整个堆大小的1/3或者1/4,两个值设为一样大。
2)-XX:SurvivorRatio
用于设置Eden和其中一个Survivor的比值,这个值也比较重要。
3)-XX:+PrintTenuringDistribution
这个参数用于显示每次Minor GC时Survivor区中各个年龄段的对象的大小。
4).-XX:InitialTenuringThreshol和-XX:MaxTenuringThreshold
用于设置晋升到老年代的对象年龄的最小值和最大值,每个对象在坚持过一次Minor GC之后,年龄就加1。
-
- 从年轻代空间(包括 Eden 和 Survivor 区域)回收内存被称为 Minor GC;
- 对老年代GC称为Major GC;
- 而Full GC是对整个堆来说的;
在最近几个版本的JDK里默认包括了对永生带即方法区的回收(JDK8中无永生带了),出现Full GC的时候经常伴随至少一次的Minor GC,但非绝对的。Major GC的速度一般会比Minor GC慢10倍以上。下边看看有那种情况触发JVM进行Full GC及应对策略。
Minor GC触发条件: 当Eden区满时,触发Minor GC。
Full GC触发条件:
(1)System.gc()方法的调用
此方法的调用是建议JVM进行Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加Full GC的频率,也即增加了间歇性停顿的次数。强烈影响系建议能不使用此方法就别使用,让虚拟机自己去管理它的内存,可通过通过-XX:+ DisableExplicitGC来禁止RMI(Java远程方法调用)调用System.gc。
(2)老年代空间不足
旧生代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误: java.lang.OutOfMemoryError: Java heap space 为避免以上两种状况引起的FullGC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
(3)方法区空间不足
JVM规范中运行时数据区域中的方法区,在HotSpot虚拟机中又被习惯称为永生代或者永生区,Permanet Generation中存放的为一些class的信息、常量、静态变量等数据,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下也会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息: java.lang.OutOfMemoryError: PermGen space 为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。
(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
如果发现统计数据说之前Minor GC的平均晋升大小比目前old gen剩余的空间大,则不会触发Minor GC而是转为触发full GC
(5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
-
- Bootstrap ClassLoader:根类加载器,负责加载java的核心类,它不是java.lang.ClassLoader的子类,而是由JVM自身实现;
- Extension ClassLoader:扩展类加载器,扩展类加载器的加载路径是JDK目录下jre/lib/ext,扩展类的getParent()方法返回null,实际上扩展类加载器的父类加载器是根加载器,只是根加载器并不是Java实现的;
- System ClassLoader:系统(应用)类加载器,它负责在JVM启动时加载来自java命令的-classpath选项、java.class.path系统属性或CLASSPATH环境变量所指定的jar包和类路径。程序可以通过getSystemClassLoader()来获取系统类加载器;
- 首先会先查找当前ClassLoader是否加载过此类,有就返回;
- 如果没有,查询父ClassLoader是否已经加载过此类,如果已经加载过,就直接返回Parent加载的类;
- 如果整个类加载器体系上的ClassLoader都没有加载过,才由当前ClassLoader加载(调用findClass)。
作用:保证JDK核心类的优先加载;
- 自定义类加载器,重写loadClass方法;
- 使用线程上下文类加载器;
1.第一次破坏
由于双亲委派模型是在JDK1.2之后才被引入的,而类加载器和抽象类java.lang.ClassLoader则在JDK1.0时代就已经存在,面对已经存在的用户自定义类加载器的实现代码,Java设计者引入双亲委派模型时不得不做出一些妥协。在此之前,用户去继承java.lang.ClassLoader的唯一目的就是为了重写loadClass()方法,因为虚拟机在进行类加载的时候会调用加载器的私有方法loadClassInternal(),而这个方法唯一逻辑就是去调用自己的loadClass()。
2.第二次破坏
双亲委派模型的第二次“被破坏”是由这个模型自身的缺陷所导致的,双亲委派很好地解决了各个类加载器的基础类的同一问题(越基础的类由越上层的加载器进行加载),基础类之所以称为“基础”,是因为它们总是作为被用户代码调用的API,但世事往往没有绝对的完美。
如果基础类又要调用回用户的代码,那该么办?
一个典型的例子就是JNDI服务,JNDI现在已经是Java的标准服务, 它的代码由启动类加载器去加载(在JDK1.3时放进去的rt.jar),但JNDI的目的就是对资源进行集中管理和查找,它需要调用由独立厂商实现并部署在应用程序的ClassPath下的JNDI接口提供者的代码,但启动类加载器不可能“认识”这些代码。
为了解决这个问题,Java设计团队只好引入了一个不太优雅的设计:线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader()方法进行设置,如果创建线程时还未设置,他将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。
有了线程上下文加载器,JNDI服务就可以使用它去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作,这种行为实际上就是打通了双亲委派模型层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则,但这也是无可奈何的事情。Java中所有涉及SPI的加载动作基本上都采用这种方式,例如JNDI、JDBC、JCE、JAXB和JBI等。
3.第三次破坏
双亲委派模型的第三次“被破坏”是由于用户对程序动态性的追求导致的,这里所说的“动态性”指的是当前一些非常“热门”的名词:代码热替换、模块热部署等,简答的说就是机器不用重启,只要部署上就能用。 OSGi实现模块化热部署的关键则是它自定义的类加载器机制的实现。每一个程序模块(Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。在OSGi幻境下,类加载器不再是双亲委派模型中的树状结构,而是进一步发展为更加复杂的网状结构,当受到类加载请求时,OSGi将按照下面的顺序进行类搜索: 1)将java.*开头的类委派给父类加载器加载。 2)否则,将委派列表名单内的类委派给父类加载器加载。 3)否则,将Import列表中的类委派给Export这个类的Bundle的类加载器加载。 4)否则,查找当前Bundle的ClassPath,使用自己的类加载器加载。 5)否则,查找类是否在自己的Fragment Bundle中,如果在,则委派给Fragment Bundle的类加载器加载。 6)否则,查找Dynamic Import列表的Bundle,委派给对应Bundle的类加载器加载。 7)否则,类加载器失败。
-
ThreadLocal是什么呢?其实ThreadLocal并非是一个线程的本地实现版本,它并不是一个Thread,而是threadlocalvariable(线程局部变量)。也许把它命名为ThreadLocalVar更加合适。线程局部变量(ThreadLocal)其实的功用非常简单,就是为每一个使用该变量的线程都提供一个变量值的副本,是Java中一种较为特殊的线程绑定机制,是每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。
-
JVM并不知道泛型的存在,因为泛型在编译阶段就已经被处理成普通的类和方法; 处理机制是通过类型擦除,擦除规则:
-
若泛型类型没有指定具体类型,用Object作为原始类型;
-
若有限定类型< T exnteds XClass >,使用XClass作为原始类型;
-
若有多个限定< T exnteds XClass1 & XClass2 >,使用第一个边界类型XClass1作为原始类型;
-
因为不管是 ArrayList 还是 ArrayList,在编译完成后都会被编译器擦除成了 ArrayList。
Java 泛型擦除是 Java 泛型中的一个重要特性,其目的是避免过多的创建类而造成的运行时的过度消耗。所以,想 ArrayList 和 ArrayList 这两个实例,其类实例是同一个。
-
-
StringBuilder StringBuffer:区别
- String不可变,用final修饰char[],StringBuilder和StringBuffer可变
- StringBuffer用Synchronized修饰,是线程安全的
- StringBuffer获取toString使用缓冲区构造字符串
-
StringBuffer效率不如StringBuilder
-
CMS垃圾回收过程
-
synchronized是Java中的关键字,是一种同步锁。它修饰的对象有以下几种: \1. 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象; \2. 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象; \3. 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象; \4. 修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象
小结:
synchronized修饰不加static的方法,锁是加在单个对象上,不同的对象没有竞争关系;修饰加了static的方法,锁是加载类上,这个类所有的对象竞争一把锁。
-
synchronized reentractlock
-
Synchronized进过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释放为止。
-
由于ReentrantLock是java.util.concurrent包下提供的一套互斥锁,相比Synchronized,ReentrantLock类提供了一些高级功能,主要有以下3项:
1.等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。通过lock.lockInterruptibly()来实现这个机制。
2.公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
-
-
transient //短暂的
- 将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会被序列化。
-
HashMap是很常用的Map,它根据键的hashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。因为键对象不可以重复,所以HashMap最多只允许一条记录的键为Null,允许多条记录的值为Null,是非同步的,底层是数组+链表。先对Key用hashcode()计算存放位置,再对Key用equals()遍历链表查找。
默认:初始容量为 16,负载因子为 0.75,当存储元素>容量*负载因子时扩容。
在jdk1.8版本后,java对HashMap做了改进,在链表长度大于8的时候,将后面的数据存在红黑树中,以加快检索速度。
1.7头插,1.8尾插
头插法是操作速度最快的,找到数组位置就直接找到插入位置了,但是课程里演示过, jdk8之前hashmap这种插入方法在并发场景下如果多个线程同时扩容会出现循环列表。 jdk8开始hashmap链表在节点长度达到8之后会变成红黑树,这样一来在数组后节点长 度不断增加时,遍历一次的次数就会少很多很多(否则每次要遍历所有),相比头插法 而言,尾插法操作额外的遍历消耗已经小很多了,也可以避免之前的循环列表问题。 (同时如果变成红黑树,也不可能做头插法了)
HashMap链表转红黑树需要同时满足两个条件: 1.table数组长度>=64 2.链表长度>8
判断table数组的长度,如果小于64的话,就扩容,容量为原来的2倍。
-
LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。
-
Hashtable
Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
-
concurrentHashMap
-
1.7分段+ReentrantLock
-
1.8cas+Synchronized
-
只要线程可以在30到50次自旋里拿到锁,那么Synchronized就不会升级为重量级锁,而等待的线程也就不用被挂起,我们也就少了挂起和唤醒这个上下文切换的过程开销.
但如果是ReentrantLock呢?它则只有在线程没有抢到锁,然后新建Node节点后再尝试一次而已,不会自旋,而是直接被挂起,这样一来,我们就很容易会多出线程上下文开销的代价.
如果是线程并发量不大的情况下,那么Synchronized因为自旋锁,偏向锁,轻量级锁的原因,不用将等待线程挂起,偏向锁甚至不用自旋,所以在这种情况下要比ReentrantLock高效
-
\1. jdk1.7 ConcurrentHashMap采用 分段锁的机制,实现并发的更新操作,底层采用数组+链表的存储结构,jdk1.8的实现已经抛弃了Segment分段锁机制,利用CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构。
- 键值对节点使用的Node
- Node:保存key,value及key的hash值的数据结构。
class Node<K, V> implements Map.Entry<K, V> { final int hash; final K key; volatile V val; volatitle Node<K, V> next; }
其中value和next都用volatile修饰,保证并发的可见性。
\3. put操作采用CAS+synchronized实现并发插入或更新操作, key没有元素则cas插入否则synchronized上锁
4.其他的和hashMap 差不多。
5.线程安全,不允许有null值null 键
-
-
什么是AQS?
答:AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面。AQS是一个用来构建锁和同步器的框架,比如ReentrantLock,Semaphore,ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。
问:AQS的核心思想是什么?它是怎么实现的?
答:AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。 AQS使用一个voliate int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值的修改。
AQS定义了两种资源获取方式:独占(只有一个线程能访问执行,又根据是否按队列的顺序分为公平锁和非公平锁,如ReentrantLock) 和共享(多个线程可同时访问执行,如Semaphore/CountDownLatch,Semaphore、CountDownLatCh、 CyclicBarrier )。ReentrantReadWriteLock 可以看成是组合式,允许多个线程同时对某一资源进行读。
AQS底层使用了模板方法模式, 自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在上层已经帮我们实现好了。
-
cas问题

cas优点:如一描述在并发量不是很高时cas机制会提高效率。 cas缺点: 1、cpu开销大,在高并发下,许多线程,更新一变量,多次更新不成功,循环反复,给cpu带来大量压力。 2、只是一个变量的原子性操作,不能保证代码块的原子性。 3、ABA问题CAS存在一个很明显的问题,即ABA问题。
问题:如果变量V初次读取的时候是A,并且在准备赋值的时候检查到它仍然是A,那能说明它的值没有被其他线程修改过了吗?
如果在这段期间曾经被改成B,然后又改回A,那CAS操作就会误认为它从来没有被修改过。针对这种情况,java并发包中提供了一个带有标记的原子引用类AtomicStampedReference,它可以通过控制变量值的版本来保证CAS的正确性。
z那开发过程中ABA怎么保证的?
加标志位,例如搞个自增的字段,操作一次就自增加一,或者搞个时间戳,比较时间戳的值。
demo:现在我们去要求操作数据库,根据CAS的原则我们本来只需要查询原本的值就好了,现在我们一同查出他的标志位版本字段vision。
-
volatile具有可见性、有序性,不具备原子性。
注意,volatile不具备原子性,这是volatile与java中的synchronized、java.util.concurrent.locks.Lock最大的功能差异,这一点在面试中也是非常容易问到的点。
有序性:即程序执行时按照代码书写的先后顺序执行。在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性
-
volatile VS synchronized
- volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
- volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的
- volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性
- volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
- volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
-
线程池
什么是线程池?
线程池是一种多线程处理形式,处理过程中将任务提交到线程池,任务的执行交由线程池来管理。
如果每个请求都创建一个线程去处理,那么服务器的资源很快就会被耗尽,使用线程池可以减少创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
为什么要使用线程池?
创建线程和销毁线程的花销是比较大的,这些时间有可能比处理业务的时间还要长。这样频繁的创建线程和销毁线程,再加上业务工作线程,消耗系统资源的时间,可能导致系统资源不足。(我们可以把创建和销毁的线程的过程去掉)
线程池有什么作用?
线程池作用就是限制系统中执行线程的数量。
1、提高效率 创建好一定数量的线程放在池中,等需要使用的时候就从池中拿一个,这要比需要的时候创建一个线程对象要快的多。
2、方便管理 可以编写线程池管理代码对池中的线程同一进行管理,比如说启动时有该程序创建100个线程,每当有请求的时候,就分配一个线程去工作,如果刚好并发有101个请求,那多出的这一个请求可以排队等候,避免因无休止的创建线程导致系统崩溃。
说说几种常见的线程池及使用场景
1、newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
2、newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
3、newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
4、newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行。
线程池中的几种重要的参数
corePoolSize就是线程池中的核心线程数量,这几个核心线程,只是在没有用的时候,也不会被回收
maximumPoolSize就是线程池中可以容纳的最大线程的数量
keepAliveTime,就是线程池中除了核心线程之外的其他的最长可以保留的时间,因为在线程池中,除了核心线程即使在无任务的情况下也不能被清 除,其余的都是有存活时间的,意思就是非核心线程可以保留的最长的空闲时间,
util,就是计算这个时间的一个单位。
workQueue,就是等待队列,任务可以储存在任务队列中等待被执行,执行的是FIFIO原则(先进先出)。
threadFactory,就是创建线程的线程工厂。
handler,是一种拒绝策略,我们可以在任务满了之后,拒绝执行某些任务。
说说线程池的拒绝策略
当请求任务不断的过来,而系统此时又处理不过来的时候,我们需要采取的策略是拒绝服务。RejectedExecutionHandler接口提供了拒绝任务处理的自定义方法的机会。在ThreadPoolExecutor中已经包含四种处理策略。-
AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作。
-
CallerRunsPolicy 策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前的被丢弃的任务。
-
DiscardOleddestPolicy策略: 该策略将丢弃最老的一个请求,也就是即将被执行的任务,并尝试再次提交当前任务。
-
DiscardPolicy策略:该策略默默的丢弃无法处理的任务,不予任何处理。
除了JDK默认提供的四种拒绝策略,我们可以根据自己的业务需求去自定义拒绝策略,自定义的方式很简单,直接实现RejectedExecutionHandler接口即可。
execute和submit的区别?
在前面的讲解中,我们执行任务是用的execute方法,除了execute方法,还有一个submit方法也可以执行我们提交的任务。这两个方法有什么区别呢?分别适用于在什么场景下呢?我们来做一个简单的分析。
execute适用于不需要关注返回值的场景,只需要将线程丢到线程池中去执行就可以了。
submit方法适用于需要关注返回值的场景
五种线程池的使用场景
- newSingleThreadExecutor:一个单线程的线程池,可以用于需要保证顺序执行的场景,并且只有一个线程在执行。
- newFixedThreadPool:一个固定大小的线程池,可以用于已知并发压力的情况下,对线程数做限制。
- newCachedThreadPool:一个可以无限扩大的线程池,比较适合处理执行时间比较小的任务。
- newScheduledThreadPool:可以延时启动,定时启动的线程池,适用于需要多个后台线程执行周期任务的场景。
- newWorkStealingPool:一个拥有多个任务队列的线程池,可以减少连接数,创建当前可用cpu数量的线程来并行执行。
线程池的关闭
关闭线程池可以调用shutdownNow和shutdown两个方法来实现
shutdownNow:对正在执行的任务全部发出interrupt(),停止执行,对还未开始执行的任务全部取消,并且返回还没开始的任务列表。
shutdown:当我们调用shutdown后,线程池将不再接受新的任务,但也不会去强制终止已经提交或者正在执行中的任务。
初始化线程池时线程数的选择
如果任务是IO密集型,一般线程数需要设置2倍CPU数以上,以此来尽量利用CPU资源。
如果任务是CPU密集型,一般线程数量只需要设置CPU数加1即可,更多的线程数也只能增加上下文切换,不能增加CPU利用率。
上述只是一个基本思想,如果真的需要精确的控制,还是需要上线以后观察线程池中线程数量跟队列的情况来定。
线程池都有哪几种工作队列
1、ArrayBlockingQueue
是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
2、LinkedBlockingQueue
一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列
3、SynchronousQueue
一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
4、PriorityBlockingQueue
一个具有优先级的无限阻塞队列。
-
-
偏向所锁,轻量级锁都是乐观锁,重量级锁是悲观锁。 一个对象刚开始实例化的时候,没有任何线程来访问它的时候。它是可偏向的,意味着,它现在认为只可能有一个线程来访问它,所以当第一个线程来访问它的时候,它会偏向这个线程,此时,对象持有偏向锁。偏向第一个线程,这个线程在修改对象头成为偏向锁的时候使用CAS操作,并将对象头中的ThreadID改成自己的ID,之后再次访问这个对象时,只需要对比ID,不需要再使用CAS在进行操作。 一旦有第二个线程访问这个对象,因为偏向锁不会主动释放,所以第二个线程可以看到对象时偏向状态,这时表明在这个对象上已经存在竞争了,检查原来持有该对象锁的线程是否依然存活,如果挂了,则可以将对象变为无锁状态,然后重新偏向新的线程,如果原来的线程依然存活,则马上执行那个线程的操作栈,检查该对象的使用情况,如果仍然需要持有偏向锁,则偏向锁升级为轻量级锁,(偏向锁就是这个时候升级为轻量级锁的)。如果不存在使用了,则可以将对象回复成无锁状态,然后重新偏向。 轻量级锁认为竞争存在,但是竞争的程度很轻,一般两个线程对于同一个锁的操作都会错开,或者说稍微等待一下(自旋),另一个线程就会释放锁。 但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁膨胀为重量级锁,重量级锁使除了拥有锁的线程以外的线程都阻塞,防止CPU空转。
-
rpc限流--资源隔离
资源隔离,就是将多个依赖服务的调用分别隔离到各个资源的内部,避免因为依赖服务的失败或者延迟,导致服务所有的线程资源花费在这个上面,继而导致服务崩塌。在货船中,为了防止漏水和火灾的扩散,一般会将货仓进行分割,避免了一个货仓出事导致整艘船沉没的悲剧。同样的,在Hystrix中,也采用了这样的舱壁模式,将系统中的服务提供者隔离起来,一个服务提供者延迟升高或者失败,并不会导致整个系统的失败,同时也能够控制调用这些服务的并发度。
-
信号量
-
线程池
-
在该模式下,用户请求会被提交到各自的线程池中执行,把执行每个下游服务的线程分离,从而达到资源隔离的作用。当线程池来不及处理并且请求队列塞满时,新进来的请求将快速失败,可以避免依赖问题扩散。
在信号量模式提到的问题,对所依赖的多个下游服务,通过线程池的异步执行,可以有效的提高接口性能。
优势
-
减少所依赖服务发生故障时的影响面,比如ServiceA服务发生异常,导致请求大量超时,对应的线程池被打满,这时并不影响ServiceB、ServiceC的调用。
-
如果接口性能有变动,可以方便的动态调整线程池的参数或者是超时时间,前提是Hystrix参数实现了动态调整。
缺点
- 请求在线程池中执行,肯定会带来任务调度、排队和上下文切换带来的开销。
- 因为涉及到跨线程,那么就存在ThreadLocal数据的传递问题,比如在主线程初始化的ThreadLocal变量,在线程池线程中无法获取
-
-
前面讨论的几种算法都属于单机限流的范畴,但是业务需求五花八门,简单的单机限流,根本无法满足他们。
比如为了限制某个资源被每个用户或者商户的访问次数,5s只能访问2次,或者一天只能调用1000次,这种需求,单机限流是无法实现的,这时就需要通过集群限流进行实现。
如何实现? 为了控制访问次数,肯定需要一个计数器,而且这个计数器只能保存在第三方服务,比如redis。
大概思路:每次有相关操作的时候,就向redis服务器发送一个incr命令,比如需要限制某个用户访问/index接口的次数,只需要拼接用户id和接口名生成redis的key,每次该用户访问此接口时,只需要对这个key执行incr命令,在这个key带上过期时间,就可以实现指定时间的访问频率。
-
-
1.2 RPC架构 一个完整的RPC架构里面包含了四个核心的组件,分别是Client,Client Stub,Server以及Server Stub,这个Stub可以理解为存根。
- 客户端(Client),服务的调用方。
- 客户端存根(Client Stub),存放服务端的地址消息,再将客户端的请求参数打包成网络消息,然后通过网络远程发送给服务方。
- 服务端(Server),真正的服务提供者。
- 服务端存根(Server Stub),接收客户端发送过来的消息,将消息解包,并调用本地的方法。
1.3 RPC调用过程
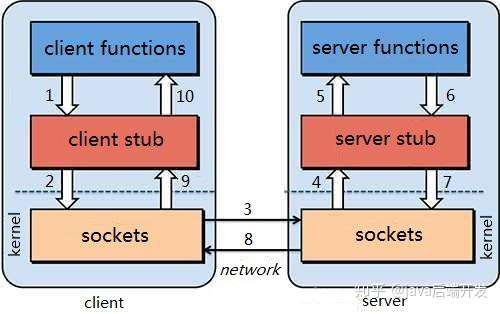
(1) 客户端(client)以本地调用方式(即以接口的方式)调用服务; (2) 客户端存根(client stub)接收到调用后,负责将方法、参数等组装成能够进行网络传输的消息体(将消息体对象序列化为二进制); (3) 客户端通过sockets将消息发送到服务端; (4) 服务端存根( server stub)收到消息后进行解码(将消息对象反序列化); (5) 服务端存根( server stub)根据解码结果调用本地的服务; (6) 本地服务执行并将结果返回给服务端存根( server stub); (7) 服务端存根( server stub)将返回结果打包成消息(将结果消息对象序列化); (8) 服务端(server)通过sockets将消息发送到客户端; (9) 客户端存根(client stub)接收到结果消息,并进行解码(将结果消息发序列化); (10) 客户端(client)得到最终结果。 RPC的目标是要把2、3、4、7、8、9这些步骤都封装起来。 注意:无论是何种类型的数据,最终都需要转换成二进制流在网络上进行传输,数据的发送方需要将对象转换为二进制流,而数据的接收方则需要把二进制流再恢复为对象。
-
http rpc比较
Http协议:超文本传输协议,是一种应用层协议。规定了网络传输的请求格式、响应格式、资源定位和操作的方式等。但是底层采用什么网络传输协议,并没有规定,不过现在都是采用TCP协议作为底层传输协议。说到这里,大家可能觉得,Http与RPC的远程调用非常像,都是按照某种规定好的数据格式进行网络通信,有请求,有响应。没错,在这点来看,两者非常相似,但是还是有一些细微差别。
- RPC并没有规定数据传输格式,这个格式可以任意指定,不同的RPC协议,数据格式不一定相同。
- Http中还定义了资源定位的路径,RPC中并不需要
- 最重要的一点:RPC需要满足像调用本地服务一样调用远程服务,也就是对调用过程在API层面进行封装。Http协议没有这样的要求,因此请求、响应等细节需要我们自己去实现。
- 优点:RPC方式更加透明,对用户更方便。Http方式更灵活,没有规定API和语言,跨语言、跨平台
- 缺点:RPC方式需要在API层面进行封装,限制了开发的语言环境。
例如我们通过浏览器访问网站,就是通过Http协议。只不过浏览器把请求封装,发起请求以及接收响应,解析响应的事情都帮我们做了。如果是不通过浏览器,那么这些事情都需要自己去完成。
既然两种方式都可以实现远程调用,我们该如何选择呢?
- 速度来看,RPC要比http更快,虽然底层都是TCP,但是http协议的信息往往比较臃肿
- 难度来看,RPC实现较为复杂,http相对比较简单
- 灵活性来看,http更胜一筹,因为它不关心实现细节,跨平台、跨语言。
因此,两者都有不同的使用场景:
- 如果对效率要求更高,并且开发过程使用统一的技术栈,那么用RPC还是不错的。
- 如果需要更加灵活,跨语言、跨平台,显然http更合适
那么我们该怎么选择呢?
微服务,更加强调的是独立、自治、灵活。而RPC方式的限制较多,因此微服务框架中,一般都会采用基于Http的Rest风格服务。
-
分布式id:
-
**那么,分布式唯一ID有哪些特性或要求呢? **① 唯一性:生成的ID全局唯一,在特定范围内冲突概率极小。 ② 有序性:生成的ID按某种规则有序,便于数据库插入及排序。 ③ 可用性:可保证高并发下的可用性, 确保任何时候都能正确的生成ID。 ④ 自主性:分布式环境下不依赖中心认证即可自行生成ID。 ⑤ 安全性:不暴露系统和业务的信息, 如:订单数,用户数等
-
**一、数据库自增ID ** 核心思想:使用数据库的id自增策略(如: Mysql的auto_increment)。
优点: ① 简单,天然有序。
缺点: ① 并发性不好。 ② 数据库写压力大。 ③ 数据库故障后不可使用。 ④ 存在数量泄露风险。
核心思想:如果使用单台机器做ID生成,可以避免固定步长带来的扩容问题。
具体做法是:每次批量生成一批ID给不同的机器去慢慢消费,这样数据库的压力也会减小到N分之一,且故障后可坚持一段时间。
这种做法的缺点是服务器重启、单点故障会造成ID不连续。
-
2.redis
核心思想:Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
优点: ① 不依赖于数据库,灵活方便,且性能优于数据库。 ② 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点: ① 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。 ② 需要编码和配置的工作量比较大。
优化方案: 考虑到单节点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量,并利用上面的方案(①数据库水平拆分,设置不同的初始值和相同的步长; ②批量缓存自增ID)来配置集群。
PS:比较适合使用 Redis 来生成每天从0开始的流水号。比如:“订单号=日期+当日自增长号”,则可以每天在Redis中生成一个Key,使用INCR进行累加。
-
3.UUID生成
核心思想:结合机器的网卡(基于名字空间/名字的散列值MD5/SHA1)、当地时间(基于时间戳&时钟序列)、一个随记数来生成UUID。
其结构如下: aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee(即包含32个16进制数字,以连字号-分为五段,最终形成“8-4-4-4-12”的36个字符的字符串,即32个英数字母+4个连字号)。 例如:550e8400-e29b-41d4-a716-446655440000
优点: ① 本地生成,没有网络消耗,生成简单,没有高可用风险。
缺点: ① 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。 ② 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。 ③ 无序查询效率低:由于生成的UUID是无序不可读的字符串,所以其查询效率低。
-
4.雪花算法
核心思想:把64-bit分别划分成多段,分开来标示机器、时间、某一并发序列等,从而使每台机器及同一机器生成的ID都是互不相同。
PS:这种结构是雪花算法提出者Twitter的分法,但实际上这种算法使用可以很灵活,根据自身业务的并发情况、机器分布、使用年限等,可以自由地重新决定各部分的位数,从而增加或减少某部分的量级。比如:百度的UidGenerator、美团的Leaf等,都是基于雪花算法做一些适合自身业务的变化。
-
-
分布式锁
-
zk
1.大家都是上来直接创建一个锁节点下的一个接一个的临时顺序节点 2.如果自己不是第一个节点,就对自己上一个节点加监听器 3.只要上一个节点释放锁,自己就排到前面去了,相当于是一个排队机制。
使用zookeeper创建临时序列节点来实现分布式锁,适用于顺序执行的程序,大体思路就是创建临时序列节点,找出最小的序列节点,获取分布式锁,程序执行完成之后此序列节点消失,通过watch来监控节点的变化,从剩下的节点的找到最小的序列节点,获取分布式锁,执行相应处理,依次类推……
实现步骤:
多个Jvm同时在Zookeeper上创建同一个相同的节点( /Lock)
zk节点唯一的! 不能重复!节点类型为临时节点, jvm1创建成功时候,jvm2和jvm3创建节点时候会报错,该节点已经存在。这时候 jvm2和jvm3进行等待。
jvm1的程序现在执行完毕,执行释放锁。关闭当前会话。临时节点不复存在了并且事件通知Watcher,jvm2和jvm3继续创建。
ps:zk强制关闭时候,通知会有延迟。但是close()方法关闭时候,延迟小
如果程序一直不处理完,可能导致思索(其他的一直等待)。设置有效期~ 直接close()掉 其实连接也是有有效期设置的 大家可以找下相关资料看下哦
-
redis
setnx + expire设置超时时间
-
-
sso过程:
用户访问app系统,app系统是需要登录的,但用户现在没有登录。
跳转到CAS server,即SSO登录系统,以后图中的CAS Server我们统一叫做SSO系统。 SSO系统也没有登录,弹出用户登录页。
用户填写用户名、密码,SSO系统进行认证后,将登录状态写入SSO的session,浏览器(Browser)中写入SSO域下的Cookie。
SSO系统登录完成后会生成一个ST(Service Ticket),然后跳转到app系统,同时将ST作为参数传递给app系统。
app系统拿到ST后,从后台向SSO发送请求,验证ST是否有效。
验证通过后,app系统将登录状态写入session并设置app域下的Cookie。
至此,跨域单点登录就完成了。以后我们再访问app系统时,app就是登录的。接下来,我们再看看访问app2系统时的流程。
- 用户访问app2系统,app2系统没有登录,跳转到SSO。
- 由于SSO已经登录了,不需要重新登录认证。
- SSO生成ST,浏览器跳转到app2系统,并将ST作为参数传递给app2。
- app2拿到ST,后台访问SSO,验证ST是否有效。
- 验证成功后,app2将登录状态写入session,并在app2域下写入Cookie。
这样,app2系统不需要走登录流程,就已经是登录了。SSO,app和app2在不同的域,它们之间的session不共享也是没问题的。
-
服务间调用用rpc不用http:
- rpc更好的接入服务治理中心,线上线下环境隔离
- http包头信息过多,无用数据带来开销
- Http无状态,短链接的话,频繁创建销毁
-
kafka
-
接口幂等
-
服务注册发现
-
api网关
-
网关
- 负载均衡
- nginx,lvm
- 数据预热
- 动静分离
- 负载均衡
-
分布式配置
-
分布式定时
-
rpc
-
分布式事务
-
数据库访问中间件,分库分表
-
限流熔段降级
-
分布式session
-
客户端负载均衡
-
lua脚本
- 因为一大坨复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性。
-
Redis事务
-
Redis事务的概念:
Redis 事务的本质是一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结说:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
Redis事务没有隔离级别的概念:
批量操作在发送 EXEC 命令前被放入队列缓存,并不会被实际执行,也就不存在事务内的查询要看到事务里的更新,事务外查询不能看到。
Redis不保证原子性:
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
Redis事务的三个阶段:
-
开始事务
-
命令入队
-
执行事务
Redis事务相关命令: watch key1 key2 ... : 监视一或多个key,如果在事务执行之前,被监视的key被其他命令改动,则事务被打断 ( 类似乐观锁 )
-
multi : 标记一个事务块的开始( queued )
exec : 执行所有事务块的命令 ( 一旦执行exec后,之前加的监控锁都会被取消掉 )
discard : 取消事务,放弃事务块中的所有命令
unwatch : 取消watch对所有key的监控
-
过期时间
-
1、设置过期时间
- expire key time(s)--这是最常用的方式
- setex(String key, int seconds, String value)--字符串独有的方式
注意:
-
除了string独有设置过期时间方法,其他类型都需要依靠expire方法来设置时间
-
如果没有设置时间,那缓存就是永不过期
-
如果设置了过期时间,之后又想让缓存永不过期,使用persist key
-
Redis TTL命令用于获取键到期的剩余时间(秒)。 返回值 以毫秒为单位的整数值TTL或负值
-
2、三种过期策略
-
定时删除
-
- 若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
- 定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
- 没人用
-
- 含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
- 优点:保证内存被尽快释放
- 缺点:
-
惰性删除
-
- 含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
- 优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
- 缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
-
定期删除
-
- 合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
-
- 在内存友好方面,不如"定时删除"
- 在CPU时间友好方面,不如"惰性删除"
-
- 通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点
- 定期删除过期key--处理"惰性删除"的缺点
-
- 含义:每隔一段时间执行一次删除过期key操作
- 优点:
- 缺点
- 难点
-
-
-
redis集群,三种启动方式
-
主从复制 主从读写分离
全量同步
1.从服务器发送SYNC 2.主服务器收到SYNC之后,执行BGSAVE,将数据持久化二进制RDB文件,并将此后命令写入缓冲区 3.从服务器收到快照文件后丢弃所有旧数据,载入收到的快照 4.主服务器发送完快照文件后,将缓冲区的命令发送给从服务器 5.从服务器执行命令 6.从服务器完成读请求 7.从服务器将rdb文件读到内存恢复数据增量同步
部分复制的条件,>2.8版本,runid 与master一致,掉线不重启,重启的话只能全量同步 master有数据更新,同步到slave -
哨兵 高可用,任务是监控和故障转移
- 主从的弊端,主节点挂掉后需要手动切换
- 通过发送命令监控主节点和从节点
- 当主节点挂机后,将slave升级为主节点,然后通知其他从节点更改配置
- 多个哨兵,当一个哨兵观察到主机下线,称为主观下线
- 后面的哨兵也检测到主机下线,数量到达一半以上,哨兵之间投票选出一个哨兵执行故障切换操作,然后通过发布订阅让各个哨兵监控主节点
-
集群
-
解决单机存储问题,需要将数据分片
-
虚拟哈希槽
-
CRC16(key) % 16384 计算在哪个槽节点
-
把数据存在master上,master和对应的slave同步
-
集群扩展时,把对应的节点数据移动到对应的槽节点
-
-
一致性哈希
-
一个0 -2的32次方的闭合圆,拥有这么多个桶空间
-
对节点(id)进行哈希,其值分布在圆上
-
对要存储的数据key进行哈希,其值分布在圆上,顺时针方向第一个节点
-
一致性哈希分区
一致性哈希的目的就是为了在节点数目发生改变时尽可能少的迁移数据,将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash 后会顺时针找到临接的存储节点存放。而当有节点加入或退 时,仅影响该节点在Hash环上顺时针相邻的后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
-
-
-
-
redis数据结构
-
redis pipeline
- 多条命令组合
-
rdb和aof
- RDB是Redis用来进行持久化的一种方式,是把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。二进制数据.
- save
- 阻塞当前redis服务器,执行save期间,redis服务器不能做其他事情,直到save完毕
- bgsave
- redis服务器后台异步执行快照操作,fork一个进程,rdb过程由子进程执行,只阻塞在子进程fork期间,时间短
- aof
- 以日志的方式追加写,只写增加删除改.
-
一致性哈希,虚拟哈希槽
- 一致性哈希 增加或者删除节点,数据迁移量降到最低.
-
数据倾斜
-
redis热点key
-
针对于热点Key的解决方案网上的查找出来无非就是服务端缓存和备份热点Key两种:
- 服务端缓存:即将热点数据缓存至服务端的内存中
- 备份热点Key:即将热点Key+随机数,随机分配至Redis其他节点中。这样访问热点key的时候就不会全部命中到一台机器上了。
其实这两个解决方案前提都是知道了热点Key是什么的情况,那么如何找到热点key呢? (1)热点检测 ① 凭借经验,进行预估:例如提前知道了某个活动的开启,那么就将此Key作为热点Key
② 客户端收集:在操作Redis之前对数据进行统计
③ 抓包进行评估:Redis使用TCP协议与客户端进行通信,通信协议采用的是RESP,所以能进行拦截包进行解析
④ 在proxy层,对每一个 redis 请求进行收集上报
⑤ Redis自带命令查询:Redis4.0.4版本提供了
redis-cli –hotkeys就能找出热点Key如果要用Redis自带命令查询时,要注意需要先把内存逐出策略设置为allkeys-lfu或者volatile-lfu,否则会返回错误。进入Redis中使用
config set maxmemory-policy allkeys-lfu即可。
-
-
redis大key问题
-
大key问题
由于Redis主线程为单线程模型,大key也会带来一些问题,如:
1、集群模式在slot分片均匀情况下,会出现数据和查询倾斜情况,部分有大key的Redis节点占用内存多,QPS高。
2、大key相关的删除或者自动过期时,会出现qps突降或者突升的情况,极端情况下,会造成主从复制异常,Redis服务阻塞无法响应请求。大key的体积与删除耗时可参考下表
命令执行: redis是单线程模型,所以对于一条客户端发起的命令,如果服务器端执行的时间过长,那么必然会导致同一redis slot上其他命令的阻塞。如果是不同的业务共用了同一个redis集群(必然共用同一slot),一个业务的大key问题就会有可能导致其他业务的不可用。
数据存储: 因为大key的问题,导致slot分片数据存储分配不均匀,会导致集群就算有较大的剩余容量,仍然会出现响应慢的情况
-
解决:
大key分割
-
-
增量全量同步:runid唯一标识
-
\1. redis什么时候会发生全量复制?
a) redis slave首启动或者重启后,连接到master时
b) redis slave进程没重启,但是掉线了,重连后不满足部分复制条件
\2. redis什么时候会发生增量复制?
先来看部分复制需要的条件
a) 主从的redis版本>=2.8
b) redis slave进程没有重启,但是掉线了,重连了master(因为slave进程重启的话,run id就没有了)
c) redis slave保存的run id与master当前run id一致 (注:run id并不是pid,slave把它保存在内存中,重启就消失)
d) redis slave掉线期间,master保存在内存的offset可用,也就是master变化不大,被更改的指令都保存在内存
\3. redis进程重启后会发生全量复制还是增量复制?
a) master重启时,run id会发生变化
b) slave重启时,run id会丢失
答:很显然,会发生全量复制,因为增量复制的条件之一run id已经不能满足
4.当全量复制或者同步复制完毕,增量是如何更新到slave的?
答:通过流式的命令更新,此时master就是slave的client,这样去理解。
\5. run id如何查看?
答:通过info server命令查看
-
微服务,熔段,限流,api网关,go-micro
-
服务注册发现配置中心consul
-
微服务间通信,gRpc
-
api网关
- 路由转发
- 负载均衡
- 对外暴露的api接口,用于路由转发
-
gomicro一个服务的流程
- 在protobuf里写service
- 实现service接口的所有方法
- 注册到注册中心,把实现接口的方法的结构体传过去,这样别的服务调用这个这个微服务的方法实际执行的就是实现这个接口的方法的结构体的方法
- gomicro是一个微服务rpc框架
-
项目架构
-
api网关,
-
路由转发
-
http请求拦截,token验证
-
熔断限流
-
初始化用户微服务,上传微服务,下载微服务
-
-
dbProxy
-
文件表(文件哈系,文件名,文件存储路径)
-
用户表(用户名,密码)
-
用户Token表(用户名,登录token)
-
用户文件表(用户名,文件哈希,文件信息)
-
-
上传
-
分块上传
-
获得文件大小
-
获得redis连接
-
生成上传文件初始信息,文件哈希,文件大小,id,chunksize,一共多少chunk
-
写入Redis缓存
-
上传文件分块,将信息写入到redis缓存,用哈希,将分块文件写入磁盘,更新redis缓存状态
-
上传合并,查看id是否等于chunk数量,合并用Cat,更新文件表,用户文件表
-
-
秒传
- 查看文件表里面是否有文件哈希
- 如果有更新用户文件表
-
异步队列
- 文件上传的同时写入异步队列 包括文件哈希,文件地址,oss地址
-
-
下载
-
rabbitMq
- 异步上传到OSS
- 发布订阅模式
- 一个生产者发送消息,多个消费者获取消息,一个生产者一个交换机多个队列多个消费者
- 每个消费者都有自己的队列
- 生产者将消息发送到交换机
-
异步转移
- 从rabbitmq读取数据,包括文件哈希值,文件路径,oss路径
- 上传至oss公有云
- 和db微服务交互 mq
-
用户
- 生成token md5(username + time + sault)
- 用户注册登录
- 和db微服务交互
-
-
-
网络库项目总结
-
线程池
-
构造函数创建了n个线程和n个消息队列
- 每个线程创建的时候,会向对应id的消息队列注册可读事件,注册的文件描述符是eventfd,新建一个loop把这个loop传给消息队列
- 当该线程对应的队列有数据来时,给eventfd发送一个字节数据,唤醒线程
- 如果消息队列不空,从消息队列取出第一个元素,为消息(包括种类和socket句柄),将socket句柄注册到eventloop,回调函数是读取数据到用户缓存池
- 阻塞在eventloop的epollwait上,每次当epollwait收到eventfd数据,执行上一步的函数,即取出fd,注册fd和回调函数
-
线程id,池内线程index和消息队列id是一个
-
消息队列二级指针,掌管线程池的多条消息队列,消息队列组成:主线程监听socket,将连接的socket通过消息队列push给线程池中的线程,通过eventfd唤醒线程
-
消息:
- 消息种类,io连接还是任务
- socket句柄或者是任务回调函数
-
eventloop
- epollfd
- epollevents,存储从内核拷贝到用户态的就绪链表
- hash表:<fd, io事件>
- io事件:
- 可读
- 可写
- 添加io事件函数,删除Io事件函数
- 执行函数,阻塞在epollwait上,当epollwait唤醒,到hash表上找到这个fd对应的io事件,然后执行注册的回调函数
-
队列
-
eventfd(通过eventfd唤醒阻塞在epollwait的工作线程)
-
-
-
## 智力题
- 对一批编号为1-100,全部开关朝上(开)的灯进行以下操作:凡是1的倍数反方向拨一次开关;2的倍数反方向又拨一次开关;3的倍数反方向又拨一次开关……问:最后为关熄状态的灯的编号是哪些?
- 赛马问题 8个赛道,64个马,选前四(先跑8个一组跑,去除掉每组后四个,每组第一取出,后四名的组全淘汰,第四名的组后三个淘汰,以此类推淘汰3+2+1个,还剩10个)
- 有两根不均匀的香,烧完一根要1小时,怎么利用这两根香得到15分钟的时间?为什么这样是对的,能证明不
- 一个长方形(体)蛋糕中间有一个长方形(体)的空心位置,这个空心的长方形(体)是可见且贯穿的,怎么一刀分成平均的两份
- 鸡蛋掉落 leetcode887 二分法
- 有1000个一模一样的瓶子,其中有999瓶是普通的水,有一瓶是毒药。任何喝下毒药的生物都会在一个星期后死亡。现在,你只有10只小白鼠和一个星期的时间,如何检验出哪个瓶子里有毒药?(二分,把五百个瓶子的水放到A,另外五百水放到B,毒死了那个继续;不龙过滤器)