![]()


Index and archive all of your scanned paper documents
I hate paper. Environmental issues aside, it's a tech person's nightmare:
- There's no search feature
- It takes up physical space
- Backups mean more paper
In the past few months I've been bitten more than a few times by the problem of not having the right document around. Sometimes I recycled a document I needed (who keeps water bills for two years?) and other times I just lost it... because paper. I wrote this to make my life easier.
Paperless does not control your scanner, it only helps you deal with what your scanner produces
- Buy a document scanner that can write to a place on your network. If you need some inspiration, have a look at the scanner recommendations page.
- Set it up to "scan to FTP" or something similar. It should be able to push scanned images to a server without you having to do anything. Of course if your scanner doesn't know how to automatically upload the file somewhere, you can always do that manually. Paperless doesn't care how the documents get into its local consumption directory.
- Have the target server run the Paperless consumption script to OCR the file and index it into a local database.
- Use the web frontend to sift through the database and find what you want.
- Download the PDF you need/want via the web interface and do whatever you like with it. You can even print it and send it as if it's the original. In most cases, no one will care or notice.
Here's what you get:
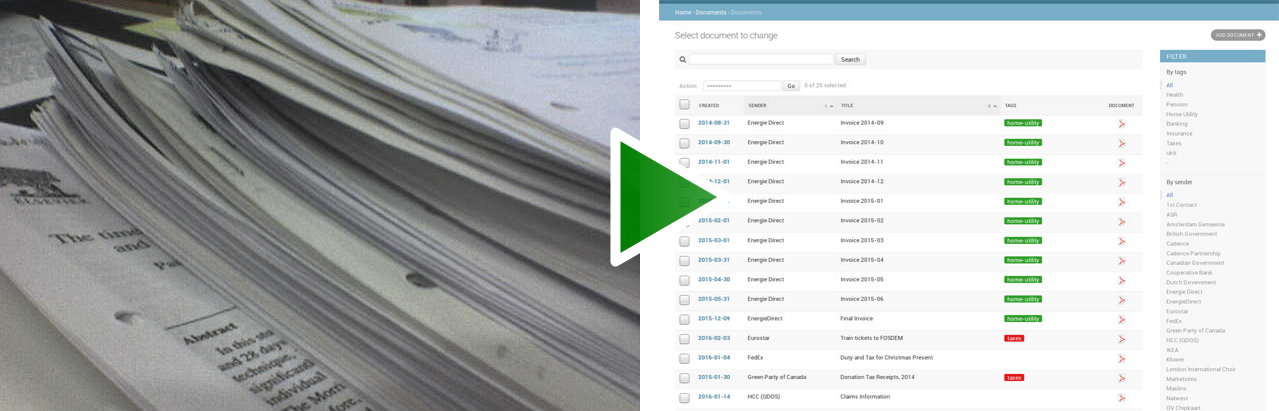
It's all available on ReadTheDocs.
This is all really a quite simple, shiny, user-friendly wrapper around some very powerful tools.
- ImageMagick converts the images between colour and greyscale.
- Tesseract does the character recognition.
- Unpaper despeckles and deskews the scanned image.
- GNU Privacy Guard is used as the encryption backend.
- Python 3 is the language of the project.
- Pillow loads the image data as a python object to be used with PyOCR.
- PyOCR is a slick programmatic wrapper around tesseract.
- Django is the framework this project is written against.
- Python-GNUPG decrypts the PDFs on-the-fly to allow you to download unencrypted files, leaving the encrypted ones on-disk.
This project has been around since 2015, and there's lots of people using it. For some reason, it's really popular in Germany -- maybe someone over there can clue me in as to why?
I am no longer doing new development on Paperless as it does exactly what I need it to and have since turned my attention to my latest project, Aletheia. However, I'm not abandoning this project. I am happy to field pull requests and answer questions in the issue queue. If you're a developer yourself and want a new feature, float it in the issue queue and/or send me a pull request! I'm happy to add new stuff, but I just don't have the time to do that work myself.
Paperless has been around a while now, and people are starting to build stuff on top of it. If you're one of those people, we can add your project to this list:
- Paperless Desktop: A desktop UI for your Paperless installation. Runs on Mac, Linux, and Windows.
- ansible-role-paperless: An easy way to get Paperless running via Ansible.
- paperless-cli: A golang command line binary to interact with a Paperless instance.
There's another project out there called Mayan EDMS that has a surprising amount of technical overlap with Paperless. Also based on Django and using a consumer model with Tesseract and Unpaper, Mayan EDMS is much more featureful and comes with a slick UI as well, but still in Python 2. It may be that Paperless consumes fewer resources, but to be honest, this is just a guess as I haven't tested this myself. One thing's for certain though, Paperless is a way better name.
Document scanners are typically used to scan sensitive documents. Things like your social insurance number, tax records, invoices, etc. While Paperless encrypts the original files via the consumption script, the OCR'd text is not encrypted and is therefore stored in the clear (it needs to be searchable, so if someone has ideas on how to do that on encrypted data, I'm all ears). This means that Paperless should never be run on an untrusted host. Instead, I recommend that if you do want to use it, run it locally on a server in your own home.
As with all Free software, the power is less in the finances and more in the collective efforts. I really appreciate every pull request and bug report offered up by Paperless' users, so please keep that stuff coming. If however, you're not one for coding/design/documentation, and would like to contribute financially, I won't say no ;-)
The thing is, I'm doing ok for money, so I would instead ask you to donate to the United Nations High Commissioner for Refugees. They're doing important work and they need the money a lot more than I do.