This is tools to convert SQL Query result into JSON file. Implemented using JDBC and Currently only support MySQL, altough other DBMS is planned soon.
- Import this project into Eclipse
- Edit config.json. Read config.json.sample for available options and documentation
- Run it.
- The output will be results.json in the project directory
Employees sample database
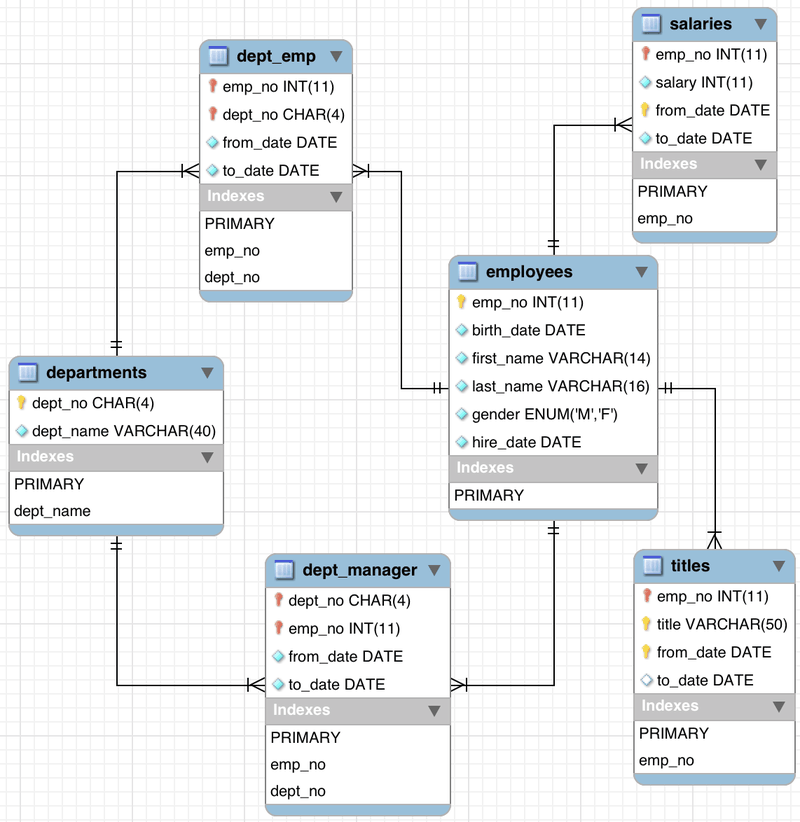
Suppose we would like to convert this schema into Self-Contained Json for employee no 110386. On the config.json, modify the query field:
"query" : "Select * FROM employees e left join titles t on e.emp_no = t.emp_no left join salaries s on e.emp_no = s.emp_no
left join dept_emp de on de.emp_no = e.emp_no left join departments d on d.dept_no = de.dept_no left join dept_manager dm on
dm.emp_no = e.emp_no where e.emp_no = 110386"
This query will left join all tables for employee no 110386 using emp_no field. ResultSet Output
JSON Output :
{
"results" : [ {
"emp_no" : 110386,
"birth_date" : "1953-10-04",
"first_name" : "Shem",
"last_name" : "Kieras",
"gender" : "M",
"hire_date" : "1988-10-14",
"titles" : [ {
"title" : "Manager",
"from_date" : "1992-08-02",
"to_date" : "1996-08-30"
}, {
"title" : "Technique Leader",
"from_date" : "1988-10-14",
"to_date" : "1992-08-02"
}, {
"title" : "Technique Leader",
"from_date" : "1996-08-30",
"to_date" : "9999-01-01"
} ],
"salaries" : [ {
"salary" : 40000,
"from_date" : "1988-10-14",
"to_date" : "1989-10-14"
}, {
"salary" : 42536,
"from_date" : "1989-10-14",
"to_date" : "1990-10-14"
}, {
"salary" : 45922,
"from_date" : "1990-10-14",
"to_date" : "1991-10-14"
}, {
"salary" : 47117,
"from_date" : "1991-10-14",
"to_date" : "1992-10-13"
}, {
"salary" : 47794,
"from_date" : "1992-10-13",
"to_date" : "1993-10-13"
}, {
"salary" : 51381,
"from_date" : "1993-10-13",
"to_date" : "1994-10-13"
}, {
"salary" : 53926,
"from_date" : "1994-10-13",
"to_date" : "1995-10-13"
}, {
"salary" : 56028,
"from_date" : "1995-10-13",
"to_date" : "1996-10-12"
}, {
"salary" : 56528,
"from_date" : "1996-10-12",
"to_date" : "1997-10-12"
}, {
"salary" : 56530,
"from_date" : "1997-10-12",
"to_date" : "1998-10-12"
}, {
"salary" : 59960,
"from_date" : "1998-10-12",
"to_date" : "1999-10-12"
}, {
"salary" : 61207,
"from_date" : "1999-10-12",
"to_date" : "2000-10-11"
}, {
"salary" : 64392,
"from_date" : "2000-10-11",
"to_date" : "2001-10-11"
}, {
"salary" : 66995,
"from_date" : "2001-10-11",
"to_date" : "9999-01-01"
} ],
"dept_emp" : [ {
"dept_no" : "d004",
"from_date" : "1988-10-14",
"to_date" : "9999-01-01"
} ],
"dept_manager" : [ {
"dept_no" : "d004",
"from_date" : "1992-08-02",
"to_date" : "1996-08-30"
} ],
"departments" : [ {
"dept_no" : "d004",
"dept_name" : "Production"
} ]
} ]
}
- The returned result from executed query is modelled using Object Exchange model (OEM). Read more info about the underlying model here
- The OEM will implemented using Map data structure, with column number as its keys, and List of Objects as its value
- Mapping SQl Types into Java Types is done by following Oracle guidelines
- JSON Parser and Generator are provided by Jackson
-
If you write query that joined tables, you should modify subnodes. Otherwise, multiple values will be written as Arrays. On the previous examples, salaries field will be written as:
"salary" : [40000, 42536, 45922, 47117, 47794, 51381, 53926, 56028, 56528, 56530, 59960, 61207, 64392, 66995], "from_date" : [1988-10-14, 1989-10-14, 1990-10-14, 1991-10-14, 1992-10-13, 1993-10-13, 1994-10-13, 1995-10-13, 1996-10-12, 1997-10-12, 1998-10-12, 1999-10-12, 2000-10-11, 2001-10-11], "to_date" : [1989-10-14, 1990-10-14, 1991-10-14, 1992-10-13, 1993-10-13, 1994-10-13, 1995-10-13, 1996-10-12, 1997-10-12, 1998-10-12, 1999-10-12, 2000-10-11, 2001-10-11, 9999-01-01]
-
Beware of the same collumn name between different table!. While JSON allow us to write duplicate field, only the last one will be used by other programs that consume the JSON. This probably isn't what you want
-
If you use alias in your query, make sure the first column's alias is the same as docRoot
-
You should use alias if you joined table
-
If your ResultSet contain multiple occurance of DocRoot (perhaps as FK), this tool is clever enough to ignore it.
- Data types limitations:
- If you have column that use LONGVARCHAR to store multi-megabyte strings. It can be unwieldy
- SQL Types ARRAY, BLOB, DISTINCT, CLOB, STRUCT, REF, and JAVA_OBJECT is ignored
- Currently only support one level of nested nodes.
Since it's possible that results set is quite large, and the OEM Tree can't be fitted all in the memory, we'll be using Producer - Consumer Design Pattern approach. The producer is OEMTree object, that will read the ResultSet, build the tree, and put it into the queue. The consumer is WriteJSON object that will retrieve the value from queue, perform necessary cleaning, and write it into the JSON file.
The queue implementation is LinkedBlockingQueue, which is recommended for this type of problems. If the queue is empty, the consumer will wait 400ms before consuming the queue again.
You know from the samples that Joined Table have a lot of duplicate values. How did this tools map it up into clean, self-contained JSON?
- Get Primary key for each collumn, and find its location in the ResultSet
- Since Joined table have alot of duplicate / null value, we need to add a bit more cleaning before adding it to the branch. We'll use each collumn PK information to define wheter this cell's data is unique or not.
- Finally, before writting OEM into JSON, we'll delete the duplicate by finding the minimum occurance of duplicate value in the branch. Then, cut the branch using sublist(0, branch.size()/duplicates)
- More output stream choices
- Other DBMS support
- Recursive Nodes
Copyright 2013 Mohammad Shahrizal Prabowo
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.