![]()
As part of my Video Quality Checker project the scripts in this repository relate to the specific issue of pixel-error detection and classification. A deep learning methodology is used to build a binary classifier to detect death pixel in a video file.
![]()
Convolutional neural networks are known to be especially suited for analyzing image data. For this project a CNN model is build using functions from the Keras Python package and sklearn library for validation.
Other packages are used to import and process image files: time, os, random, PIL, numpy, pandas, matplotlib
For generating training data a variaty of cinematic images differing in aspect ratio, luminance level and colouristic look is used. Setting up a labled data set this images are stored in different locations, distinguishing between clean images and images containing pixel errors.
In order to process video files from different aspect ratio, every image is sliced into smaller chunks of 63x63 pixel.
The Keras ImageDataGenerator is utilized to split the data set into train and test data. As the used dataset for training the model is 100% balanced and of significant size (>120K each), no image augmentation is applied during this process.
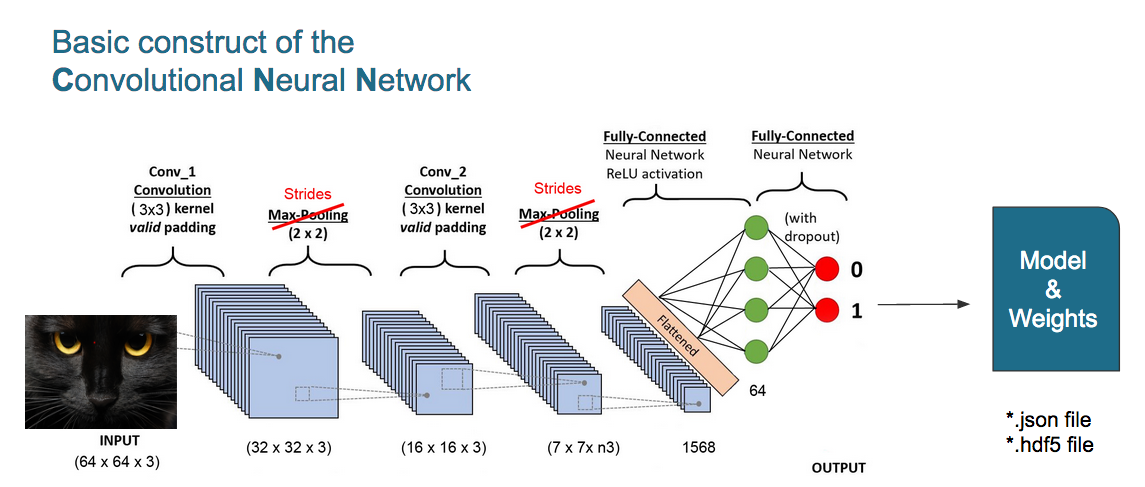
The CNN model contains several 2D convolution layers with a 3x3 kernal size and a dense layer with a sigmoid function on the end for a binary classification. Between both sections a additional dense layer is applied to flatten the three dimensional image data (matrix of image pixels) into a one dimensional array.
To downsample the number of features (pixels) from the size of the input image (64x64x3) to a binary output(2), strides of 2x2 was used instead of max pooling, as it resulted in better accuracy score.
Overfitting was not much of a problem for this network, but regularization tools where still applied to improve the processing time of the network. By decresing the number of neurons during training (Dropout), but still maintaining a significant number of neurons in each layer. Also the accuracy of the model was improving slightly (L2).
Used regularisation technics:
- Dropout
- L2
At every iteration a randomly selected number of neurons will not be concidered along with all of their incoming and outgoing connections. This shall make the network generally more robust to the inputs. Dropout can be applied to hidden layers and input layers alike. Note that this regulizer is only used during training, and not during testing.
A neural network with smaller weight matrices leads to simpler models. Utilizing L2 regulization therefore, will reduce overfitting. L2 is also known as weight decay and will forces the weights to decay towards zero (but not exactly zero). For comparison, the L1 regulizer would reduce the weigth to zero and therefore further compress the size of the model.

The model and weight are stores during training (to prevent loss of data) and afterwards into JSON and HDF5 files for usage in the Video Quality Checker Python script.