
A Stream-Fueled Hive Mind for Reinforcement Learning.
This project originated as implementing the portfolio assignment for the data engineering module DLMDSEDE02 at the International University of Applied Sciences. It demonstrates how to build a streaming data-intensive application with a machine-learning focus.
Borg-DQN presents a distributed approach to reinforcement learning centered around a shared replay memory. Echoing the collective intelligence of the Borg from the Star Trek universe, the system enables individual agents to tap into a hive-mind-like pool of communal experiences to enhance learning efficiency and robustness.
This system adopts a containerized microservices architecture enhanced with real-time streaming capabilities. Agents employ Deep Q-Networks (DQN) within game containers for training on the Atari Pong environment from OpenAI Gym. The replay memory resides in a separate container, consisting of a Redis Queue, wherein agents interface via protocol buffer messages.
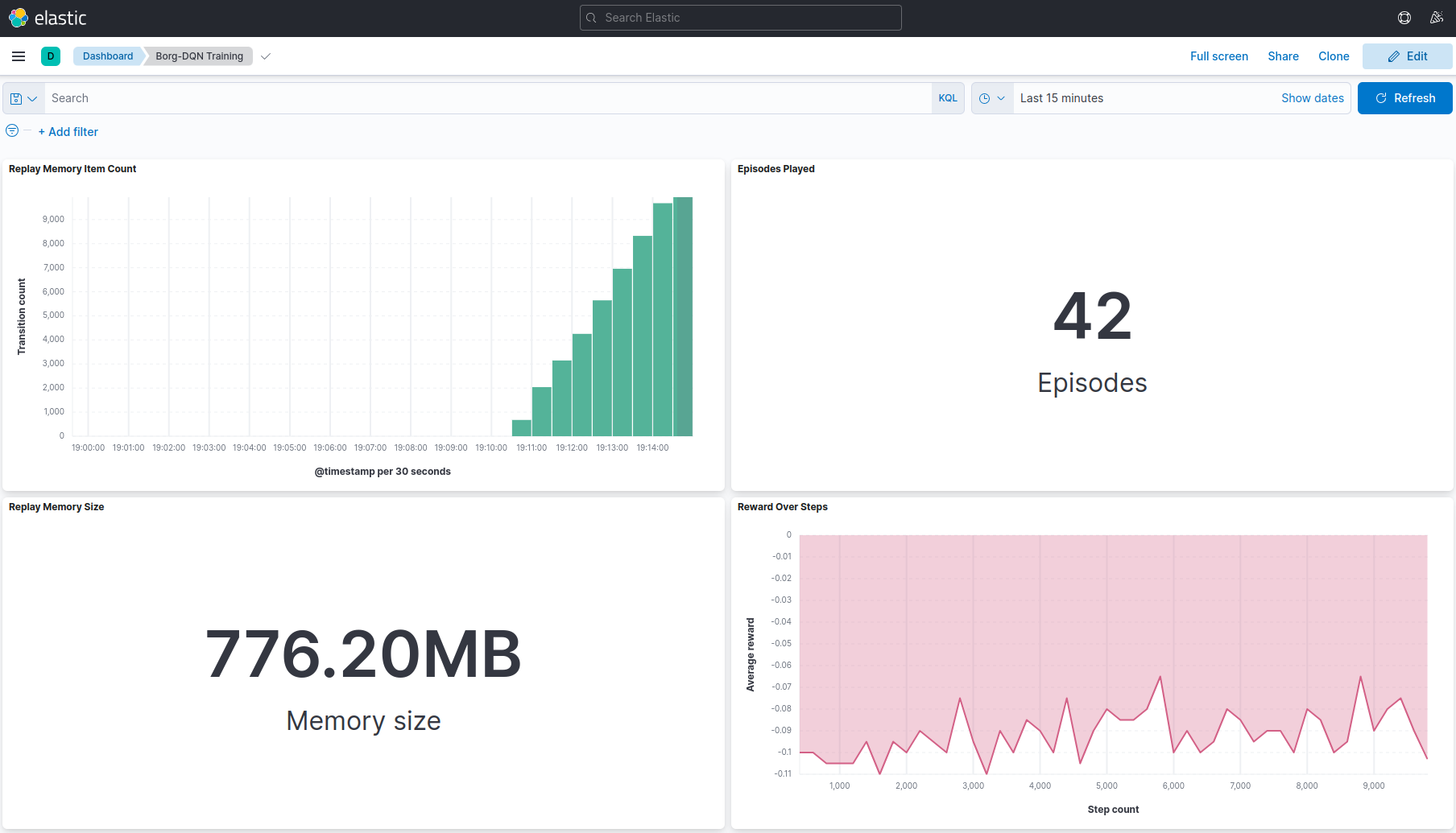
The architecture continuously streams agents' learning progress and replay memory metrics to Kafka, enabling instant analysis and visualization of learning trajectories and memory growth on a Kibana dashboard.
The execution of Borg-DQN requires a working installation of Docker, as well as the nvidia-container-toolkit to pass through CUDA acceleration to the game container instances. Refer to the respective documentation for installation instructions:
The development of the game and monitor containers furthermore requires a working Python 3.11 interpreter and poetry for dependency management:
To start the application, run from the root directory:
docker compose upObserve the learning progress and memory growth on the live dashboard.
To start the application with multiple game containers, run:
docker compose up --scale game=3The Elasticsearch indices can also be looked into.
Upon startup, game containers load the most recent model checkpoint from the mode store location, while the replay memory will be prefilled with persisted transitions.
The application follows an infrastructure-as-code (IaC) approach, wherein individual services run inside Docker containers, whose configuration and interconnectivity are defined in a compose.yaml at its root directory.

In the following, there is a short overview of each component of the application.
The game container encapsulates an Atari Pong environment (OpenAI gym) and a double deep Q-network agent (using PyTorch). The code is adapted from MERLIn, an earlier reinforcement learning project by pykong.

The game container instances can be configured via environment variables. The easiest way is to place a .env file at the project's root; keys must bear the prefix CONFIG_, for example, CONFIG_alpha=1e-2, would configure the learning rate. For a complete list of configuration parameters, consult config.py.
The game container will put each game transition into the shared replay memory and sample minibatches from that memory again. Protocol Buffers short protobuf is used for serialization, which is fast and byte-safe, allowing for efficient transformation of the NumPy arrays of the game states.
This approach, however, requires the definition and maintenance of a .proto schema file, from which native Python code is derived:
syntax = "proto3";
package transition.proto;
message Transition {
bytes state = 1;
uint32 action = 2;
float reward = 3;
bytes next_state = 4;
bool done = 5;
...
}The shared replay memory employs Redis to hold game transitions. Redis is performant and allows storing the transitions as serialized protobuf messages due to its byte-safe characteristics.
Redis, however, does not natively support queues, as demanded by the use case. The workaround used is to emulate queue behavior by the client-side execution of the LTRIM command.
The memory monitor is a Python microservice that periodically polls the Redis shared memory for transition count and memory usage statistics and publishes those under a dedicated Kafka topic. While ready-made monitoring solutions, like a Kibana integration, exist, the memory monitor demonstrates using Kafka with multiple topics, the other being the training logs.
Apache Kafka is a distributed streaming platform that excels in handling high-throughput, fault-tolerant messaging. In Borg-DQN, Kafka serves as the middleware that decouples the data-producing game environments from the consuming analytics pipeline, allowing for robust scalability and the flexibility to introduce additional consumers without architectural changes. Specifically, Kafka channels log to two distinct topics, 'training_log' and 'memory_monitoring', both serialized as JSON, ensuring structured and accessible data for any downstream systems.
The ELK stack, comprising Elasticsearch, Logstash, and Kibana, serves as a battle-tested trio for managing, processing, and visualizing data in real-time, making it ideal for observing training progress and replay memory growth in Borg-DQN. Elasticsearch is a search and analytics engine with robust database characteristics, allowing for quick retrieval and analysis of large datasets. Logstash seamlessly ingests data from Kafka through a declarative pipeline configuration, eliminating the need for custom code. Kibana leverages this integration to provide a user-customizable dashboard, all components being from Elastic, ensuring compatibility and stability.
- Create external documentation, preferably using MkDocs
- Allow game container instances to be individually configured (e.g., different epsilon values to address the exploitation-exploration tradeoff)
- Upgrade the replay memory to one featuring prioritization of transitions.
If you like Borg-DQN and want to develop it further, feel free to fork and open any pull request. 🤓
- Borg Collective
- Docker Engine
- NVIDIA Container Toolkit
- Poetry Docs
- Redis Docs
- Apache Kafka
- ELK Stack
- Protocol Buffers
- Massively Parallel Methods for Deep Reinforcement Learning
- a more intricate architecture than Borg-DQN, also featuring a shared replay memory