We use Piper library to finetuning VITS for TTS tasks with different voice in Vietnamese.
We also built a Tornado server to deploy TTS model on microservice with Docker. The server uses ONNX model type to infer lightweight and excellent performance.
Video demo: https://youtu.be/1mAhaP26aQE
Read Project Docs: Paper
On your terminal, type these commands to build a Docker Image:
docker build ./ -f .Dockerfile -t vits-tts-vi:v1.0
Then run it with port 5004:
docker run -d -p 5004:8888 vits-tts-vi:v1.0
While the Docker Image was running, you now make a request to use the TTS task via this API on your browser.
http://localhost:5004/?text=Xin chào bạn&speed=normal
The result seems like this:
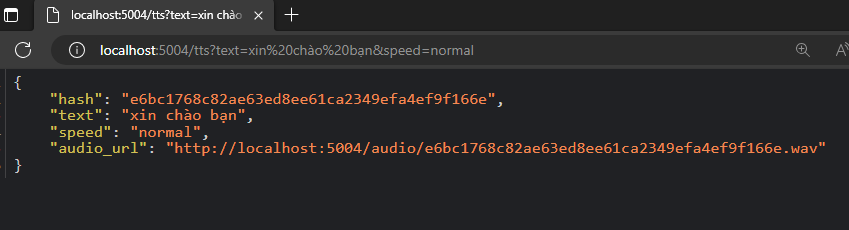
{
"hash": "e6bc1768c82ae63ed8ee61ca2349efa4ef9f166e",
"text": "xin chào bạn",
"speed": "normal",
"audio_url": "http://localhost:5004/audio/e6bc1768c82ae63ed8ee61ca2349efa4ef9f166e.wav"
}The speed has 5 options: normal, fast, low, very_fast, very_slow
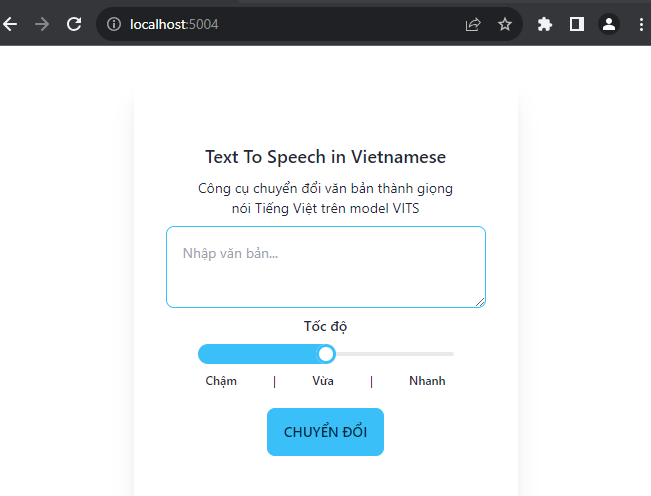
Or you can use the Web UI via this URL:
http://localhost:5004/
The repo of this React Front-end: vits-tts-webapp
In the repo folder, type in Terminal:
pip install -r requirements.txt
Then run the server file:
python server.py
Now, you can access the TTS API with port 8888:
http://localhost:8888/?text=Xin chào bạn&speed=normal
The result also seems like this:
{
"hash": "e6bc1768c82ae63ed8ee61ca2349efa4ef9f166e",
"text": "xin chào bạn",
"speed": "normal",
"audio_url": "http://localhost:5004/audio/e6bc1768c82ae63ed8ee61ca2349efa4ef9f166e.wav"
}Audio before finetuning voice (unmute to hear):
test_original.mov
Audio AFTER finetuining voice (unmute to hear):
test_finetuning.mov
### Metrics in test data BEFORE finetuning:
Mean Square Error: (lower is better) 0.044785238588228825
Root Mean Square Error (lower is better): 2.0110066944004297
=============================================
### Metrics in test data AFTER finetuning:
Mean Square Error: (lower is better) 0.043612250527366996
Root Mean Square Error (lower is better): 1.97773962268741
In TTS tasks, the output spectrogram for a given text can be represented in many different ways. So, loss functions like MSE and MAE are just used to encourage the model to minimize the difference between the predicted and target spectrograms. The right way to Evaluate TTS model is to use MOS(mean opinion scores) BUT it is a subjective scoring system and we need human resources to do it. Reference: https://huggingface.co/learn/audio-course/chapter6/evaluation
See train_vits.ipynb file in the repo or via this Google Colab:
https://colab.research.google.com/drive/1UK6t_AQUw9YJ_RDFvXUJmWMu-oS23XQs?usp=sharing
ProtonX New: https://protonx.io/news/hoc-vien-protonx-xay-dung-mo-hinh-chuyen-van-ban-thanh-giong-noi-tieng-viet-1698233526932
Author: Nguyen Thanh Phat - aka phatjk