{kind=link}
{kind=link}
![]()
Semantic search for developers



![]()

codequestion is a semantic search application for developer questions.

Developers typically have a web browser window open while they work and run web searches as questions arise. With codequestion, this can be done from a local context. This application executes similarity queries to find similar questions to the input query.
The default model for codequestion is built off the Stack Exchange Dumps on archive.org. Once a model is installed, codequestion runs locally, no network connection is required.


codequestion is built with Python 3.8+ and txtai.
The easiest way to install is via pip and PyPI
pip install codequestion
Python 3.8+ is supported. Using a Python virtual environment is recommended.
codequestion can also be installed directly from GitHub to access the latest, unreleased features.
pip install git+https://github.com/neuml/codequestion
See this link for environment-specific troubleshooting.
Once codequestion is installed, a model needs to be downloaded.
python -m codequestion.download
The model will be stored in ~/.codequestion/
The model can also be manually installed if the machine doesn't have direct internet access. The default model is pulled from the GitHub release page
unzip cqmodel.zip ~/.codequestion
Start up a codequestion shell to get started.
codequestion
A prompt will appear. Queries can be typed into the console. Type help to see all available commands.
The latest release integrates txtai 5.0, which has support for semantic graphs.
Semantic graphs add support for topic modeling and path traversal. Topics organize questions into groups with similar concepts. Path traversal uses the semantic graph to show how two potentially disparate entries are connected. An example covering both topic and path traversal is shown below.

A codequestion prompt can be started within Visual Studio Code. This enables asking coding questions right from your IDE.
Run Ctrl+` to open a new terminal then type codequestion.
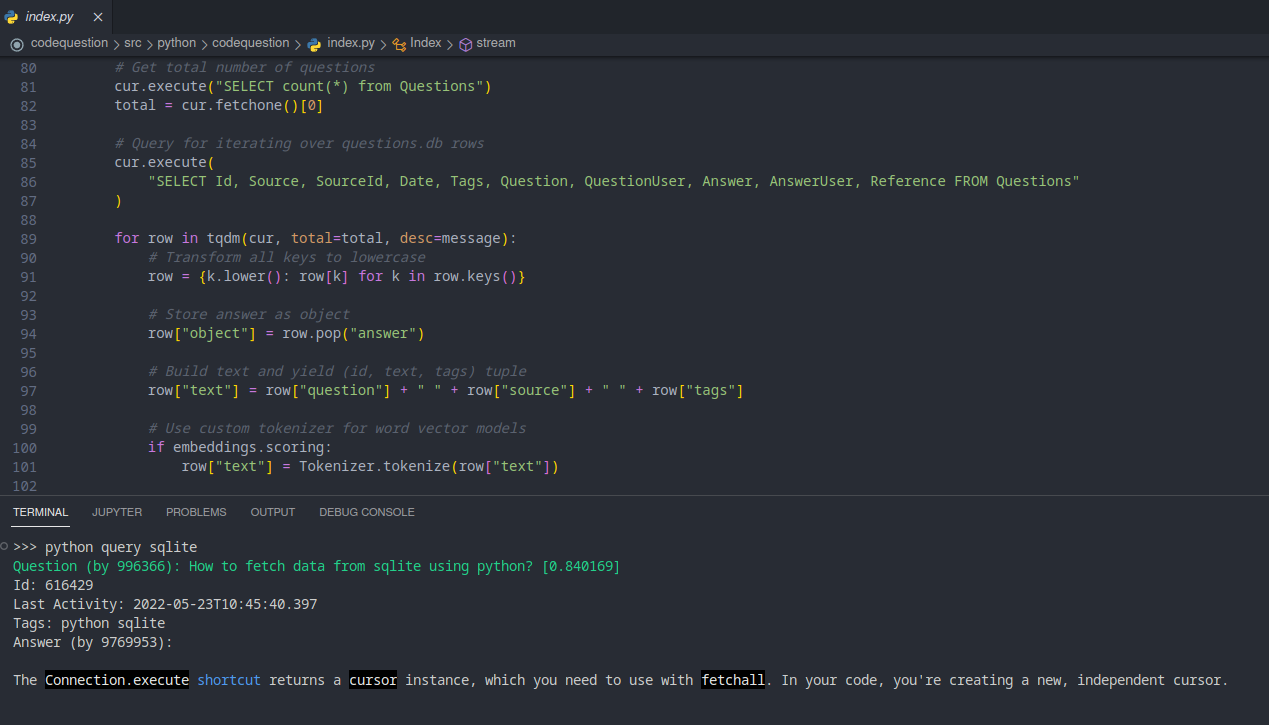
codequestion builds a standard txtai embeddings index. As such, it supports hosting the index via a txtai API service.
Running the following:
app.yml
path: /home/user/.codequestion/models/stackexchange/
embeddings:# Install API extra
pip install txtai[api]
# Start API
CONFIG=app.yml uvicorn "txtai.api:app"
# Test API
curl "http://127.0.0.1:8000/search?query=python+query+sqlite&limit=1"
Outputs:
[{
"id":"616429",
"text":"How to fetch data from sqlite using python? stackoverflow python sqlite",
"score":0.8401689529418945
}]Additional metadata fields can be pulled back with SQL statements.
curl
--get
--data-urlencode "query=select id, date, tags, question, score from txtai where similar('python query sqlite')"
--data-urlencode "limit=1"
"http://127.0.0.1:8000/search"
[{
"id":"616429",
"date":"2022-05-23T10:45:40.397",
"tags":"python sqlite",
"question":"How to fetch data from sqlite using python?",
"score":0.8401689529418945
}]The following is an overview covering how this project works.
The raw 7z XML dumps from Stack Exchange are processed through a series of steps (see building a model). Only highly scored questions with accepted answers are retrieved for storage in the model. Questions and answers are consolidated into a single SQLite file called questions.db. The schema for questions.db is below.
questions.db schema
Id INTEGER PRIMARY KEY
Source TEXT
SourceId INTEGER
Date DATETIME
Tags TEXT
Question TEXT
QuestionUser TEXT
Answer TEXT
AnswerUser TEXT
Reference TEXT
codequestion builds a txtai embeddings index for questions.db. Each question in the questions.db schema is vectorized with a sentence-transformers model. Once questions.db is converted to a collection of sentence embeddings, the embeddings are normalized and stored in Faiss, which enables fast similarity searches.
codequestion tokenizes each query using the same method as during indexing. Those tokens are used to build a sentence embedding. That embedding is queried against the Faiss index to find the most similar questions.
The following steps show how to build a codequestion model using Stack Exchange archives.
This is not necessary if using the default model from the GitHub release page
1.) Download files from Stack Exchange: https://archive.org/details/stackexchange
2.) Place selected files into a directory structure like shown below (current process requires all these files).
- stackexchange/ai/ai.stackexchange.com.7z
- stackexchange/android/android.stackexchange.com.7z
- stackexchange/apple/apple.stackexchange.com.7z
- stackexchange/arduino/arduino.stackexchange.com.7z
- stackexchange/askubuntu/askubuntu.com.7z
- stackexchange/avp/avp.stackexchange.com.7z
- stackexchange/codereview/codereview.stackexchange.com.7z
- stackexchange/cs/cs.stackexchange.com.7z
- stackexchange/datascience/datascience.stackexchange.com.7z
- stackexchange/dba/dba.stackexchange.com.7z
- stackexchange/devops/devops.stackexchange.com.7z
- stackexchange/dsp/dsp.stackexchange.com.7z
- stackexchange/raspberrypi/raspberrypi.stackexchange.com.7z
- stackexchange/reverseengineering/reverseengineering.stackexchange.com.7z
- stackexchange/scicomp/scicomp.stackexchange.com.7z
- stackexchange/security/security.stackexchange.com.7z
- stackexchange/serverfault/serverfault.com.7z
- stackexchange/stackoverflow/stackoverflow.com-Posts.7z
- stackexchange/stats/stats.stackexchange.com.7z
- stackexchange/superuser/superuser.com.7z
- stackexchange/unix/unix.stackexchange.com.7z
- stackexchange/vi/vi.stackexchange.com.7z
- stackexchange/wordpress/wordpress.stackexchange.com.7z
3.) Run the ETL process
python -m codequestion.etl.stackexchange.execute stackexchange
This will create the file stackexchange/questions.db
4.) OPTIONAL: Build word vectors - only necessary if using a word vectors model. If using word vector models, make sure to run pip install txtai[similarity]
python -m codequestion.vectors stackexchange/questions.db
This will create the file ~/.codequestion/vectors/stackexchange-300d.magnitude
5.) Build embeddings index
python -m codequestion.index index.yml stackexchange/questions.db
The default index.yml file is found on GitHub. Settings can be changed to customize how the index is built.
After this step, the index is created and all necessary files are ready to query.
The following sections show test results for codequestion v2 and codequestion v1 using the latest Stack Exchange dumps. Version 2 uses a sentence-transformers model. Version 1 uses a word vectors model with BM25 weighting. BM25 and TF-IDF are shown to establish a baseline score.
StackExchange Query
Models are scored using Mean Reciprocal Rank (MRR).
| Model | MRR |
|---|---|
| all-MiniLM-L6-v2 | 85.0 |
| SE 300d - BM25 | 77.1 |
| BM25 | 67.7 |
| TF-IDF | 61.7 |
STS Benchmark
Models are scored using Pearson Correlation. Note that the word vectors model is only trained on Stack Exchange data, so it isn't expected to generalize as well against the STS dataset.
| Model | Supervision | Dev | Test |
|---|---|---|---|
| all-MiniLM-L6-v2 | Train | 87.0 | 82.7 |
| SE 300d - BM25 | Train | 74.0 | 67.4 |
To reproduce the tests above, run the following. Substitute $TEST_PATH with any local path.
mkdir -p $TEST_PATH
wget https://raw.githubusercontent.com/neuml/codequestion/master/test/stackexchange/query.txt -P $TEST_PATH/stackexchange
wget http://ixa2.si.ehu.es/stswiki/images/4/48/Stsbenchmark.tar.gz
tar -C $TEST_PATH -xvzf Stsbenchmark.tar.gz
python -m codequestion.evaluate -s test -p $TEST_PATH