Deep Learning music generator, using Embedding =>Bidirectional GRU networks. Data were collected from networks, we choose JJ Lam's music. Chinese paper in detail.
Author:cmd23333
E-mail:[email protected]
All Rights Reserved.
( • ̀ω•́ )✧

音乐是人类历史上最伟大的发明之一。然而音乐因为其专业性需要大量的音乐领域知识和乐器技能,没有一定天赋的平常人难以进行音乐创作,而专业音乐人创作音乐也同样耗时耗力。如那我们能否用机器代替我们创作音乐呢?
随着机器学习技术的发展,越来越多的工作开始将艺术创作与计算机技术结合起来,成为人工智能领域的一大新研究方向。比如在图像领域,神经风格转换技术可以将任意一张图片转化成梵高等大师风格的作品;对抗生成网络通过生成器和鉴别器的互相博弈,可以生成很真实的图片。在文字领域,我们可以使用循环神经网络写出莎士比亚风格的诗歌;微软公司的产品“微软小冰”还可以实现看图写诗。
相较于以上二者,尤其是当前火爆的计算机视觉领域,用AI创造音乐更少的被人提及。其原因可能在于音乐完全是主观性的,结果美不美完全是凭人的感觉定的,而且不同的人对同一个曲子的评价可能差别显著。所以音乐的创作对计算机来讲是巨大的挑战,这也使一些人认为音乐的创作是人工智能最后攻克的领域。
但由于我们小组成员都喜欢听歌,加上这个领域比较新鲜,所以就决定使用深度学习技术来帮助林俊杰作曲。我们认为,音乐生成的价值在于它可以帮助音乐创作人创作音乐,提高人们的创造力。如果这一领域能够持续发展,AI必然将对未来的音乐创作提供巨大的帮助。
此次工作使用了最新版本的tensorflow 2.0作为框架来构建深度学习网络。Tensorflow 2.0版本在2019年年初推出了测试版本并于今年10月1日发布了官方正式版。相较于Tensorflow 1.x版本,2.0版本取消了“tf.session”等一系列劝退式的复杂API,专注于简单性和易用性,可以通过tf.keras和eager execution模式轻松搭建深度学习网络。并且tensorflow 2.0相较于其它框架的优势是它能自动将数据传输到GPU上,加速计算。

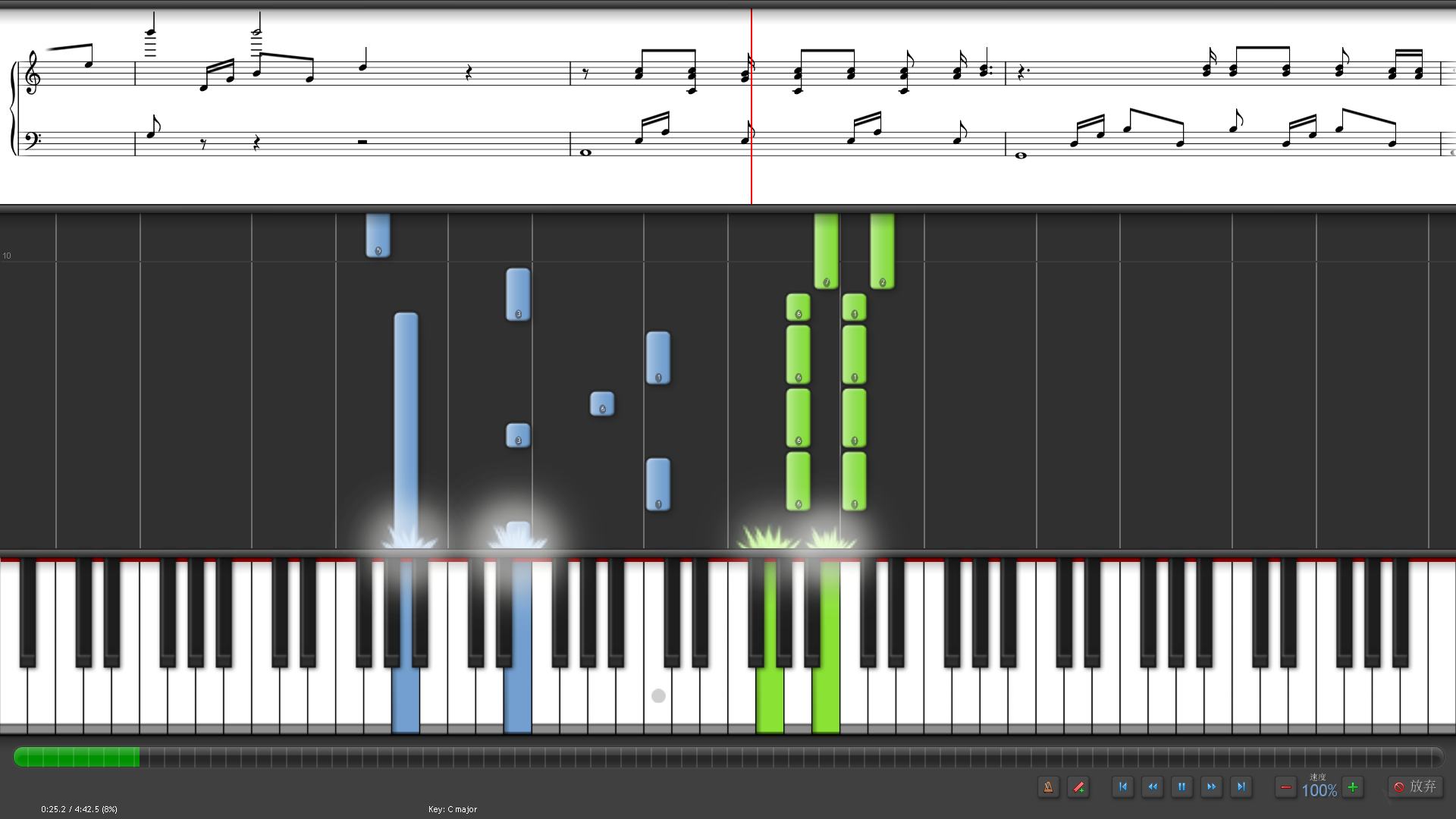
Synthesia,中文名称为钢琴英雄,是一款钢琴模拟软件。能在屏幕上显示虚拟钢琴按键,可以让不懂五线谱或简谱的人知道怎么弹钢琴,支持任何MIDI文件(即后缀为.mid的文件)的导入和弹奏。效果如下图所示。
从https://www.midishow.com 上下载得到,歌曲均为.mid文件,其原始编曲人为著名歌手林俊杰。共计22首曲子,共计约4800秒。
 在处理数据之前,先介绍一下.mid的音频文件。不同于.mp3,.wav等格式, mid传输的不是声音信号,而是音符、控制参数等指令,它指示设备要做什么,如演奏哪个音符、多大音量等。
在处理数据之前,先介绍一下.mid的音频文件。不同于.mp3,.wav等格式, mid传输的不是声音信号,而是音符、控制参数等指令,它指示设备要做什么,如演奏哪个音符、多大音量等。
一个示例如下面视频所展示。
Python中有许多库可以用来处理.mid文件,本文我们使用了pretty_midi,它可以操作并且创建新的.mid文件。
使用pretty_midi时,一个.mid文件是如下表示的:

其中,start和end分别表示这个音符的起止时间,单位是秒。在同一个时刻可以有多个音符同时演奏,所以多个音符的起止时间可以重叠。pitch代表这个音符的音调,velocity代表这个音符的强度。下面这张图表示了pitch如何与某一个音符对应。通常来说,MIDI定义了128个音符,中央C编号为60,5个八度的键盘编号可能就是36到96。

类似Note(start=2.572845, end=2.749606, pitch=67, velocity=86)的数据是无法直接传递给神经网络的,因此我们需要一步一步的对原始数据进行处理,使其能够作为神经网络的输入。
一个.mid文件中通常不止有一个音轨,但为了便于建立模型,我们只选取了最主要的,用钢琴弹奏的音轨(位于第1个音轨上)。通过pretty_midi提供的get_piano_roll方法,定义一个FPS(每秒帧数),它可以返回一个二维的numpy数组,形状为(128,x),其中128表示所有pitch的个数,x等于当前音乐持续时间乘以FPS,也就是这段音乐持续的帧数。

琴声矩阵中含有大量的0,为方便处理,我们将其转化为Python字典。


其数据组织形式为:键代表第几帧,值是numpy的数组,代表这一帧的音符音调(可能有多个)。如上图所示,我们的样本发出的第一个音符在第12帧(第12/5=2.4秒)。
对于深度学习的序列生成模型来说,训练样本的输入为一段连续时间内的值,目标输出为下一时间步的值。一个文本生成的示例就是,如果我们的训练集只有底下这一段话:
The quick brown fox jumps over the lazy dog
如果我们设定的序列长度为5,那么用于监督学习的样本对就是:
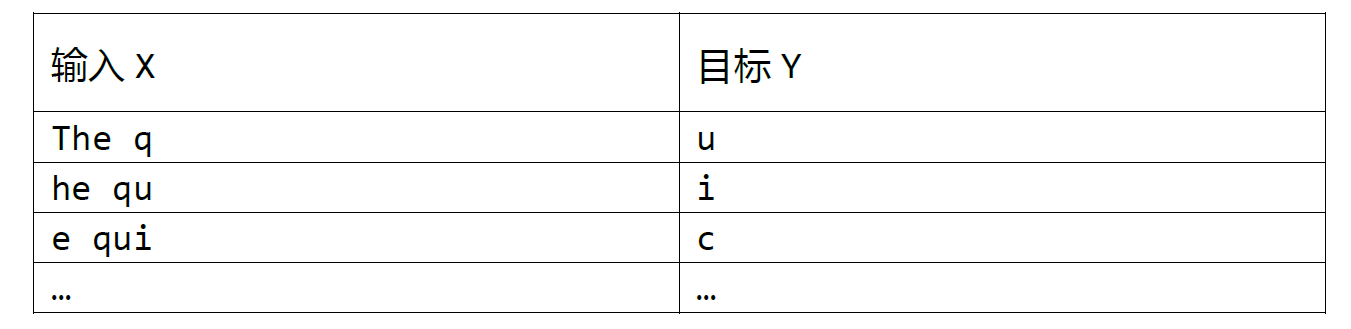
我们希望通过当前的一段时间的输入值,来预测下一个时间步的输出值。和文本序列生成模型类似,对于音乐生成来说,我们的输入为一段时间的音符,目标输出为下一个时间步的音符。

本次项目我们将序列长度设置为50。模型的输入为连续50帧的音调,目标输出为第51帧的音调。在FPS=5的情况下,也就是说我们的输入序列长度为10秒。但有时会出现歌曲在某个时间点并没有演奏音符的情况,因此我们还需添加‘e’到序列中,代表这一帧没有音符被演奏。

比如这个例子,我们发现第13帧和第16帧缺失了,因此我们需要将它补全为[…, '67,77', 'e', '75', '75', 'e', 'e', …]。在生成输入时,(我们设定的序列长度为50)如果是前50帧的某一音调,我们无法选取这个音调的前50帧,因此需要对其补'e'。举例来说,图中的第12帧,67作为Y的话,X即为50个'e';图中的第13帧,'e'作为Y的话,X为49个'e'和一个67,以此类推。
在将数据投入神经网络之前,我们需要将音符序列转化为音符索引的序列。需要创建一个映射,将音符和它的索引一一对应。例如:
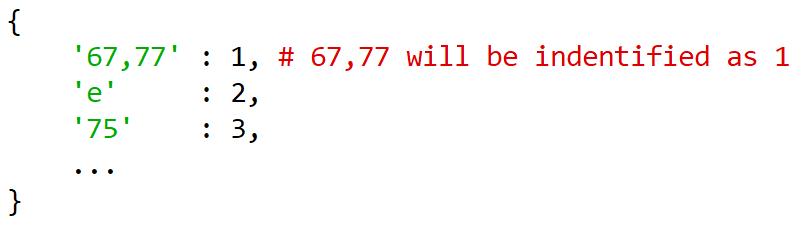

将被转换为:
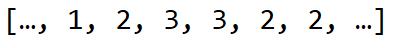
Embedding翻译为嵌入,最初应用在自然语言处理领域,它的提出是为了用向量来表示单个单词的信息。举例来说,如果我们有六个单词:king,queen,prince,princess,banana,apple,他们的一个想象的词嵌入可以如下表所示:
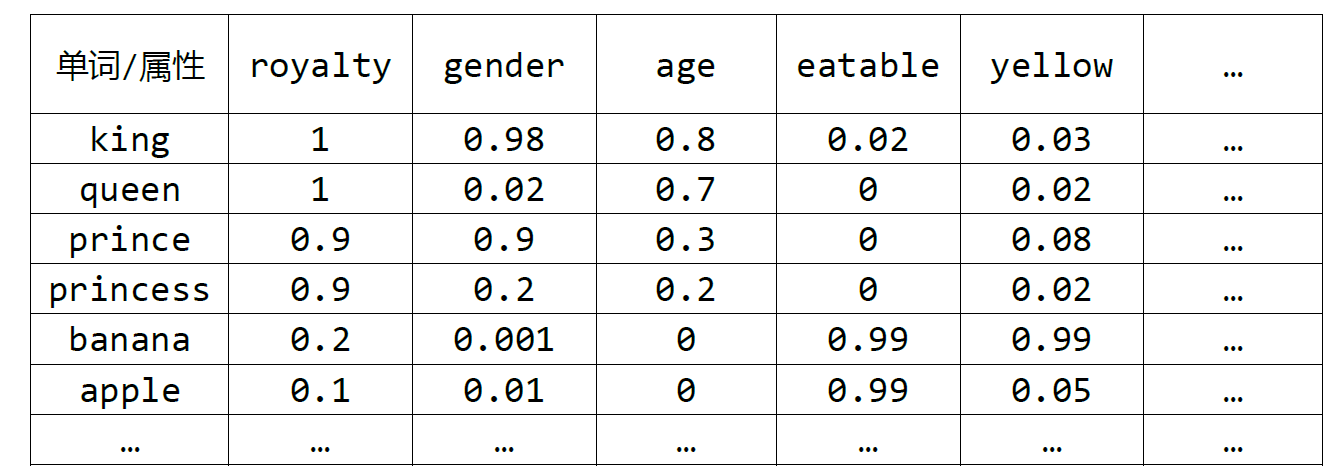
如上表所示,每个单词都含有不同的属性,比如高贵、性别、年龄、是否可食用等等,对于king国王这一单词,它很高贵,通常只男人,年龄较大,不可食用,和黄色联系不大,因此它对应的特征向量为[1,0.98,0.8,0.02,0.03,…],同样的对于banana香蕉,因为它并没有体现出高贵、性别和年龄,所以前三个属性的值都很小,但香蕉是可以食用的,而且容易让人联想到黄色,所以它对应的特征向量为[0.2,0.001,0,0.99,0.99,…]。这样我们就将不同的单词用向量化进行了表示,可以进行后续的计算。
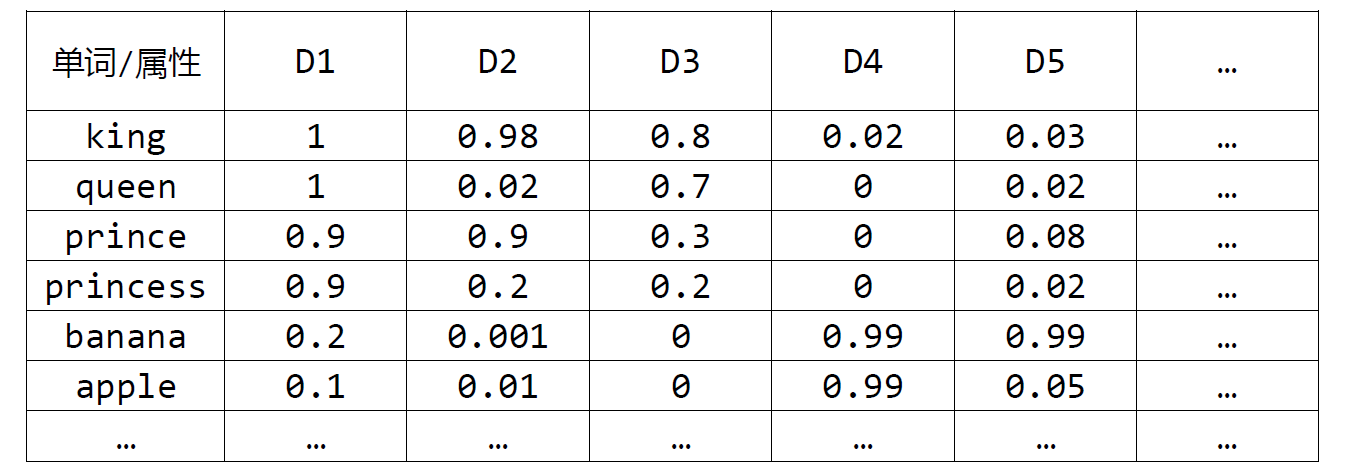
但是通常在深度学习中,我们并不知道单词对应特征向量的每一个分量代表什么,这些分量不一定代表了高贵、性别、年龄、是否可食用这些信息,也可能是其他你还未想到的属性,也有可能是多个属性的组合,但这些属性是可以通过深度学习的计算,通过反向传播优化得到的。
同样的,我们对不同的音符做了维度为100的Embedding,这样就可以尝试获得各种不同音符的信息,进行计算,如下图所示。注意到同一音符的特征向量永远是相同的。

通常人们喜欢使用循环神经网络(Recurrent Neuron Networks)对序列数据构建模型。GRU是循环神经网络的一种,可以用来捕捉更早的时间步的信息。如果一个序列下一个时间步的值只和之前的信息有关,我们仅需使用单向的GRU网络,但更实际的情况往往是序列某一个时间点的值,它既与之前的信息有关,又和之后的信息有关。比如我们需要语音识别这句话:
I want a bottle of pear/beer juice.
需要我们计算得到下划线上该填入的词,是梨(pear)还是啤酒(beer)。如果我们只考虑前面的信息I want a bottle of (),那后面的下划线就可以填beer,我想要一瓶啤酒;但如果我们同时考虑了后面的信息,__ juice,因为beer juice啤酒果汁是我虚构出来的东西,所以我们决定在下划线上填pear,表示我想要一瓶梨汁。
音乐也是一样,尤其是流行音乐,都会有一些重复的旋律,因此如果我们在预测某一个时间点的音符时使用了前后的信息,可以是预测的精度获得更大的提升。具体来说,本次实验模型的第一层双向GRU网络的示意图如下所示。
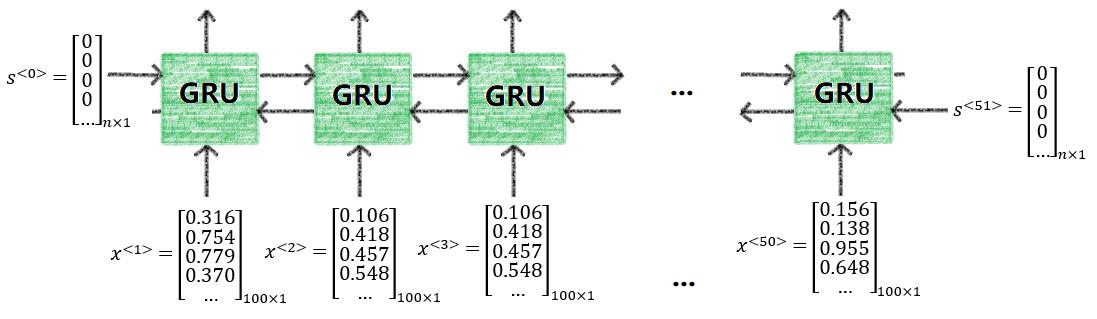
其中,下方为训练集连续50帧的音符的特征向量,因为我们设置了100维的Embedding,所以输入维数为100;左右分别为GRU单元隐藏状态的初始值(用全0向量表示),维数为n,向上箭头输出的维数也为n。
我们可以使用任意层的双向GRU网络来提升模型的拟合能力,但最后一层的GRU网络有些许不同,这一层的return_sequence设置为False,也就是我们只返回一个输出值。如下图所示。

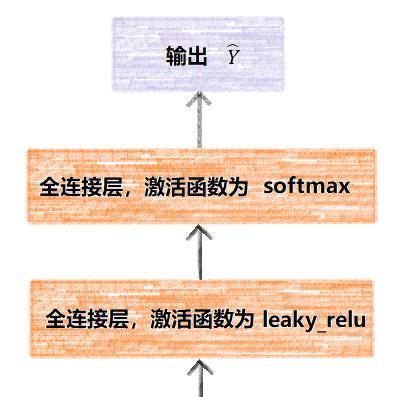
经过了双向循环网络得到特征信息后,还需使用全连接层进一步获取深层次的特征,最后经过Softmax激活函数获得输出为任意一个音符的概率。本次的训练集中一共有200种不同的音符或者音符的组合在同一帧出现,加上空音符'e',模型的最终输出为一个201维的向量。这一部分的示意图如下所示。
其中,模型的输出形如这个形式:

在训练过程中,使用交叉熵作为损失函数,并更新参数。Y代表目标输出,为1~201中任意一个数,表示标识后的第Y个音符。
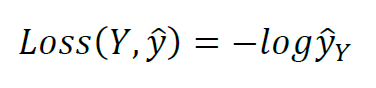
如果y ̂的第Y个值(代表输出为第Y个音符的概率)接近于1,那么Loss的值就很小;相反,如果输出为第Y个音符的概率很小,那么Loss将会很大。
通过测试以及用人耳去感受音乐,本次实验设计了多种网络结构,最终确定的网络模型如下图所示。
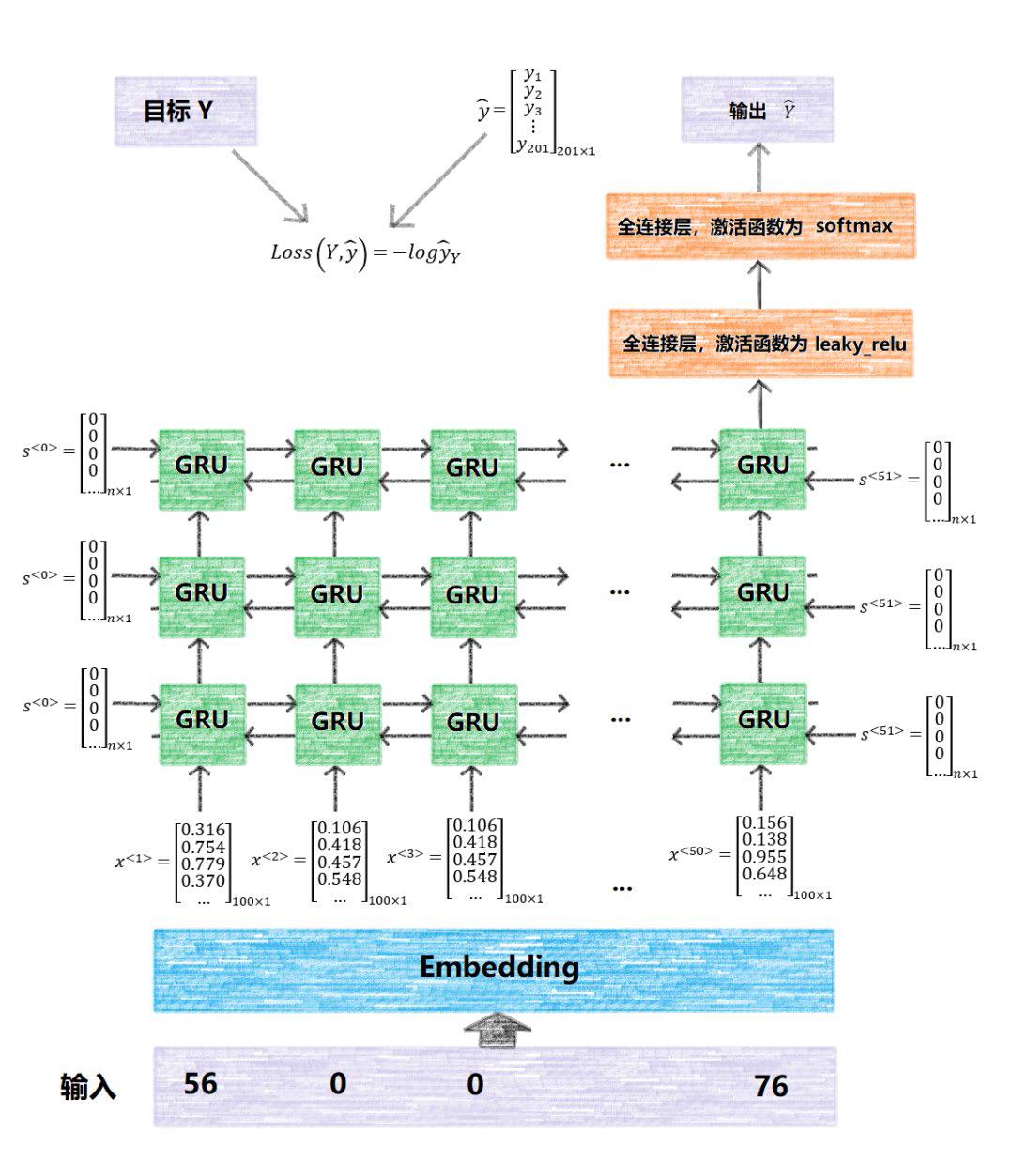
使用Tensorflow 2.0建立模型,首先是输入层,然后是Embedding层,Embedding的维度为100;然后将Embedding送入双向GRU层,经过三次这样的操作以提取特征。随后我们将最后一层生成的256维向量,输入全连接层并且使用leakyRelu函数激活,再使用一层全连接层,并使用softmax激活函数,生成一个201维的向量,这个201代表训练集一共出现了201种不同的音符组合。这个201维的向量即为我们最终的输出,它代表输入的50帧之后的下一帧可能出现的音符的概率。
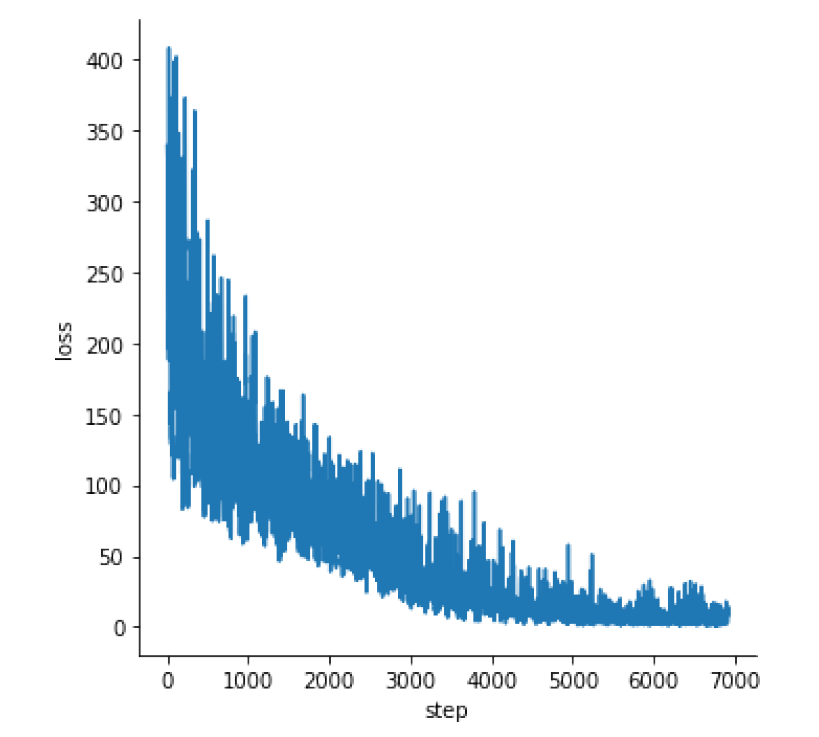
在Tensorflow 2.0版本里,我们可以使用GradientTape获得梯度,然后便使用梯度下降法进行训练。@tf.function装饰器可以将数据放入AutoGraph中,从而加速训练。本次实验一共训练了50轮,Loss的变化如下图所示。
模型需要输入50帧之前的音符才能生成下一帧的音符,因此,根据“初始化”的方式不同,我们有可以通过多种方式来生成mid音频文件。比如我们可以随机生成50帧的音符,或者使用49个空音符和一个自己输入的起始音符。
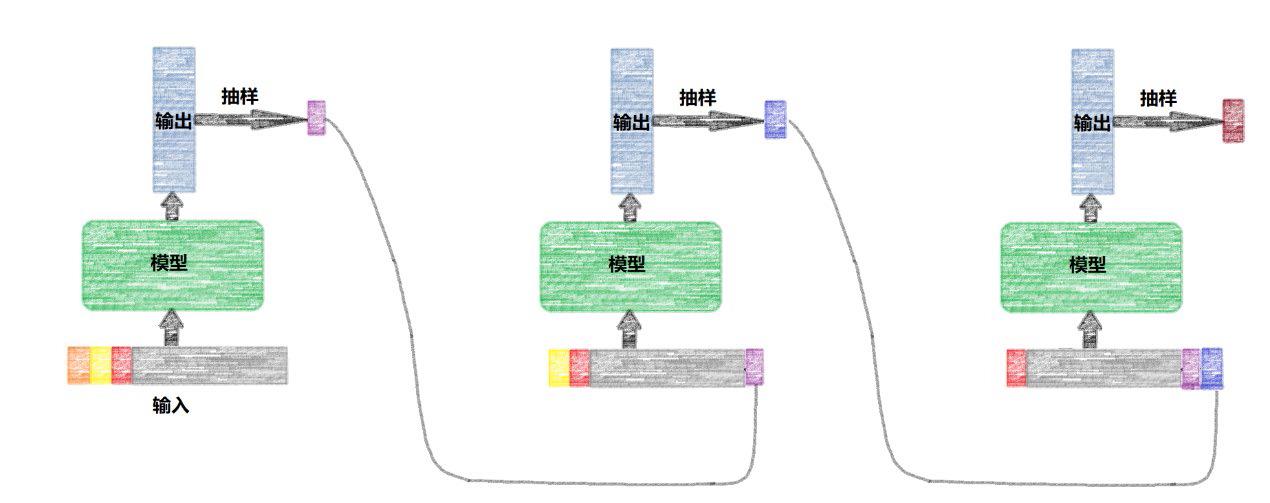
一个简化的生成过程如上图所。我们随机初始化一个长度为50的序列(假设为['62', '63', …, '56', '55']),将其输入到网络后,网络会输出一个201维的向量,每个元素代表下一个音符为该元素的概率。依概率随机抽取其中一个,比如我们抽到了'66,44'。接下来将前一步的后49个音符和现在抽取的音符将其作为下一步的输入(['63',… ,'56', '55', '66,44'])作为输入,并再次输出一个201维的向量。如此重复进行,指定生成音符的个数,将音符序列转换为pretty_midi对象,便可以输出音频文件了。
下面为几个生成音乐的示例。
见主目录下的各个.mid文件
随着物质生活水平的日益提高,人们的文化娱乐生活日渐丰富,人们对精神上的需求日益增加。但是,在人工智能领域,生成真实且具有美感的艺术作品一直被认为是一种挑战。
本文将音乐数据数字化以后,利用深度GRU序列模型成功地生成了带有林俊杰风格的mid格式音乐。虽然通过实验实现了音乐的生成,但同时也存在以下问题:
在生成的音乐片段中,发现有的生成的音乐片段和真实音乐数据相比,包含太多分散的音符,这样会导致生成的音乐和真实音乐相比远远不能满足人耳的听觉感受。
本文的数据集仅对钢琴这一个音轨的音乐进行生成,然而现实生活中,音乐还存在许多其它的音轨,并且不同的音乐包含的音轨种类和音轨数量均有所不同。因此,生成仅包含钢琴的音乐还不能满足现实生活的需求。
近几年,学术界对计算机音乐生成方面的研究越来越多,针对本文研究存在的不足和问题,仍有许多方向值得进一步研究,主要包括以下几个方面:
对于音乐数据方面。本文生成的音乐仅包钢琴一个音轨,然而,现实生活中有的音乐创作包含更多不同的音轨,因此,在后续的工作中,可以考虑使用更丰富的音乐数据集,来生成包含更多音轨的音乐,使生成的音乐具有更丰富的多样性。
除此之外,音乐是一种具有复杂结构的艺术,它的结构是有特定形式的,每一首歌曲的结构组成都有所不同,一般的流行歌曲的结构是以主歌、副歌、过渡句、流行句(即记忆点)等组成。本文设计的音乐生成模型,没有考虑一首歌曲的结构组成因素,因此,在后续的工作中,可以思考如何将歌曲的结构特征加入到网络模型中,从而生成一首完整的歌曲。