直接看概念,柯里化是把一个多参函数转换为一个嵌套的一元函数的过程
不理解,莫方!举个栗子就明白了。
假设我们有一个函数,add:
const add = (x,y)=>x+y;
我们调用的时候当然就是add(1,2),没有什么特别的。当我们柯里化了以后呢,就是如下版本:
const add = x => y => x + y;
调用的时候呢,就是这个样子的:
addCurried(4)(4)//8
-
内存泄漏指任何对象在您不再拥有或需要它之后仍然存在。垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为0(没有其他对象引引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收。
-
settimeout的第一个参数使用字符串而非函数的话,会引发内存泄漏。 闭包、控制台日志、循环(在两个对象彼此引用且彼此保留时,就会产生一个循环)
-
标记清除(mark and sweep) 这是js最常见的垃圾回收方式,当变量进入执行环境的时候,比如函数中声明一个变量,垃圾回收器将其标记为“进入环境”,当变量离开环境的时候(函数执行结束)将其标记为“离开环境”。 垃圾回收器会在运行的时候给存储在内存中的所有变量加上标记,然后去掉环境中的变量以及被环境中变量所引用的变量(闭包),在这些完成之后仍然存在标记的就是要删除的变量。
-
引用计数(reference counting) 在低版本IE中经常出现内存泄漏,很多时候就是因为采用引用技术的方式进行垃圾回收。 引用计数的策略是跟踪记录每个值被引用的次数,当声明一个变量并将一个引用类型赋值给该变量的时候这个值的引用次数+1,如果该变量的值变成了另一个,则这个值的引用次数-1,当引用次数为0的时候就回收。
- 堆( 引用数据类型(对象、数组、函数)保存在堆 ) 动态分配内存,大小不定也不会自动释放。
- 栈( 基本数据类型保存在栈。 ) 由编译器自动分配内存空间、有系统自动释放,存放函数的参数值,局部变量的值等。
ps:堆栈存在意义: 为了使程序运行时占用的内存最小!!!
-
原型链实现继承 优点: 非常简便的实现了多重继承的关系; 能够确定原型和实例之间的关系; 缺点: 创建子类型实例时,无法向父类型传递参数,尤其是多重继承时,弊端非常明显; 所有的实例会共享通过原型链继承的属性,在一个实例中改变了,会在另一个实例中反映出来; 不能使用字面量添加新方法,会使继承关系中断(会重写constructor属性)。
-
构造函数实现继承 优点: 通过使用call可以在调用的时候向父类型传递参数。 缺点: 仅仅借用构造函数,方法都在构造函数中定义,就无法实现函数复用; 通过借用构造函数,在父类型原型中定义的方法也无法通过原型链暴露给子类型;
-
组合继承 组合继承就是将前面两种方法组合到一起。 原理是通过原型链实现对原型属性和方法的继承,而通过构造函数实现对实例属性的继承。这样,既保证原型上定义的属性和方法可以共享,又保证每个实例都有自己的属性。 优点: 组合继承避免了原型继承和借用构造函数继承的缺点,融合了他们的优点,是目前最常用的继承方式。
-
原型式继承 (省略,自己去了解)
-
寄生式继承 (省略,自己去了解)
-
寄生组合式继承 (省略,自己去了解) ps:主要记住原型链继承、构造函数继承和他们相结合的组合式继承。
- html5 websoket
- Websocke通过Flash
- XHR长时间连接
- XHR Multipart Streaming
- 不可见的 iframe
- < script>标签的长时间连接(可跨域)
- 1字头 响应信息提示
- 2字头 请求成功
- 3字头 重定向
- 4字头 客户端错误
- 5字头 服务器错误
拓展:250 请求的文件操作正确,已完成;600 源站没有返回响应头部,只返回实体内容。
- rem是根据根的font-size变化,em是根据父级的font-size变化
- link属于HTML标签,除了加载CSS外,还能用于定义RSS,定义rel连接属性等作用;而@import是CSS提供,只能加载CSS;
- 页面被加载的时,link会同时被加载,而@import引用的CSS会等到页面被加载完再加载;
- important > 内联样式 > ID > 类 | 伪类 | 属性选择 > 标签 | 伪元素 > 继承 > 通配符
- 内联样式表的权值最高 1000;
- ID 选择器的权值为 100;
- Class 类选择器的权值为 10;
- HTML 标签(类型)选择器的权值为 1
- merge 是一个合并操作,会将两个分支的修改合并在一起,默认操作的情况下会提交合并中修改的内容
- merge 的提交历史忠实地记录了实际发生过什么,关注点在真实的提交历史上面
- rebase 并没有进行合并操作,只是提取了当前分支的修改,将其复制在了目标分支的最新提交后面
- rebase 的提交历史反映了项目过程中发生了什么,关注点在开发过程上面
- merge 与 rebase 都是非常强大的分支整合命令,没有优劣之分,使用哪一个应由项目和团队的开发需求决定
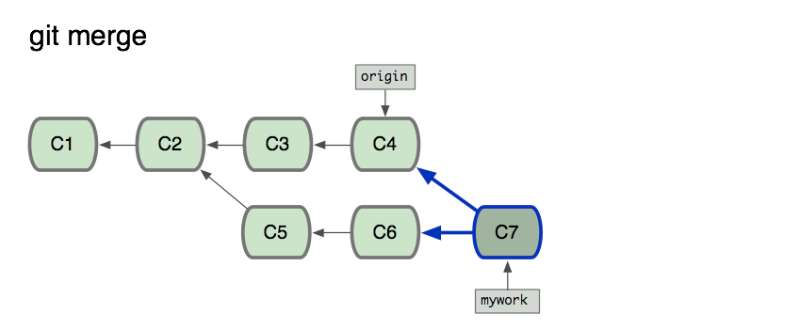
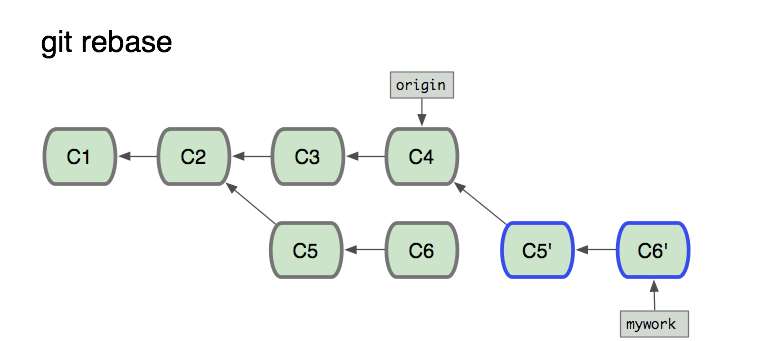
- 作用都是为了改变函数运行时上下文而存在的。即改变函数体内部this的指向。说白点,a有xx方法,b没有。b可以问a借!
- 区别:接受参数方式不一样。call接受的是连续参数,apply接受的是数组参数。
- Javascript的new关键字主要的作用是继承 new一共经历4个阶段
- 1、创建一个空对象
var obj = new Object();
- 2、设置原型链 此时便建立了obj对象的原型链
obj._proto_ = Object.prototype;
- 3、让Func的this指向obj,并执行Func函数体
Object.call(obj);
- 4、判断Func的返回值类型 如果是值类型,返回obj; 如果是引用类型,返回这个引用类型的对象。
return typeof result === 'obj'? result : obj;
- 原理:事件冒泡机制
- 优点 1.可以大量节省内存占用,减少事件注册。比如ul上代理所有li的click事件就很不错。 2.可以实现当新增子对象时,无需再对其进行事件绑定,对于动态内容部分尤为合适
- 缺点
事件代理的常用应用应该仅限于上述需求,如果把所有事件都用事件代理,可能会出现事件误判。即本不该被触发的事件被绑定上了事件。
- 事件捕获 处于目标阶段 事件冒泡
- 含义 Websocket是一个持久化的协议,相对于HTTP这种非持久的协议来说。
- 原理
类似长轮循长连接 ; 发送一次请求 ; 源源不断的得到信息
- localStorage会跟cookie一样受到跨域的限制,会被document.domain影响
- 发布者-订阅者模式(backbone.js)
- 脏值检查(angular.js)
- 数据劫持
tips:vue.js 数据劫持+发布订阅模式/
-
Hash Mode: hash 值的变化,并不会导致浏览器向服务器发出请求,浏览器不发出请求,也就不会刷新页面。另外每次 hash 值的变化,还会触发
hashchange这个事件,通过这个事件我们就可以知道 hash 值发生了哪些变化。检测到 hash 的变化后,就可以通过替换 DOM 的方式来实现页面的更换。 -
HTML5 Mode: HTML5标准发布。多了两个 API,pushState 和 replaceState,通过这两个 API 可以改变 url 地址且不会发送请求。同时还有 onpopstate 事件。通过这些就能用另一种方式来实现前端路由了,但原理都是跟 hash 实现相同的。用了 HTML5 的实现,单页路由的 url 就不会多出一个#,变得更加美观。但因为没有 # 号,所以当用户刷新页面之类的操作时,浏览器还是会给服务器发送请求。为了避免出现这种情况,所以这个实现需要服务器的支持,需要把所有路由都重定向到根页面。
-
ps:简单来说,路由就是用来跟后端服务器进行交互的一种方式,通过不同路径来请求不同资源。请求不同页面是路由的其中一种功能。 本质上就是检测 url 的变化,截获 url 地址,然后解析来匹配路由规则。
- 重绘:是一个元素的外观变化所引发的浏览器行为;例如改变visibility、outline、背景色等属性。
- 重排:是引起DOM树重新计算的行为。 1.添加、删除可见的dom 2.元素的位置改变 3.元素的尺寸改变(外边距、内边距、边框厚度、宽高、等几何属性) 4.页面渲染初始化 5.浏览器窗口尺寸改变
避免: 减少重排次数,缩小重排范围(在body最后插入元素不会导致整个浏览器重新渲染,在body元素最前面插入元素会)、 将多次手动改变js样式合并为一次处理、将需要多次重排的dom节点设置为position:absolute\fixed,脱离文档流、 内存中多次处理dom节点,完了push进文档