LSTM Implementation in Caffe
Note that the master branch of Caffe supports LSTM now. (Jeff Donahue's implementation has been merged.)
This repo is no longer maintained.
Jeff's code is more modularized, whereas this code is optimized for LSTM.
This code computes gradient w.r.t. recurrent weights with a single matrix computation.
- Batch size = 20, Length = 100
| Code | Forward(ms) | Backward(ms) | Total (ms) |
|---|---|---|---|
| This code | 248 | 291 | 539 |
| Jeff's code | 264 | 462 | 726 |
- Batch size = 4, Length = 100
| Code | Forward(ms) | Backward(ms) | Total (ms) |
|---|---|---|---|
| This code | 131 | 118 | 249 |
| Jeff's code | 140 | 290 | 430 |
- Batch size = 20, Length = 20
| Code | Forward(ms) | Backward(ms) | Total (ms) |
|---|---|---|---|
| This code | 49 | 59 | 108 |
| Jeff's code | 52 | 92 | 144 |
- Batch size = 4, Length = 20
| Code | Forward(ms) | Backward(ms) | Total (ms) |
|---|---|---|---|
| This code | 29 | 26 | 55 |
| Jeff's code | 30 | 61 | 91 |
An example code is in /examples/lstm_sequence/.
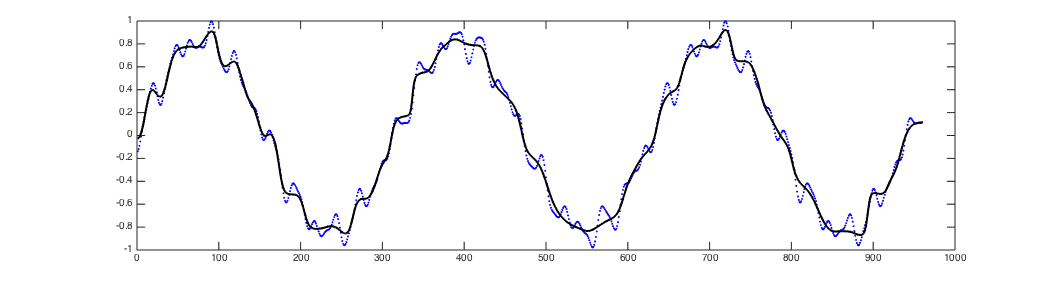
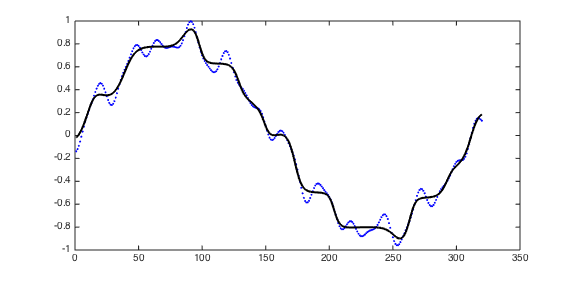
In this code, LSTM network is trained to generate a predefined sequence without any inputs.
This experiment was introduced by Clockwork RNN.
Four different LSTM networks and shell scripts(.sh) for training are provided.
Each script generates a log file containing the predicted sequence and the true sequence.
You can use plot_result.m to visualize the result.
The result of four LSTM networks will be as follows:
- 1-layer LSTM with 15 hidden units for short sequence
- 1-layer LSTM with 50 hidden units for long sequence
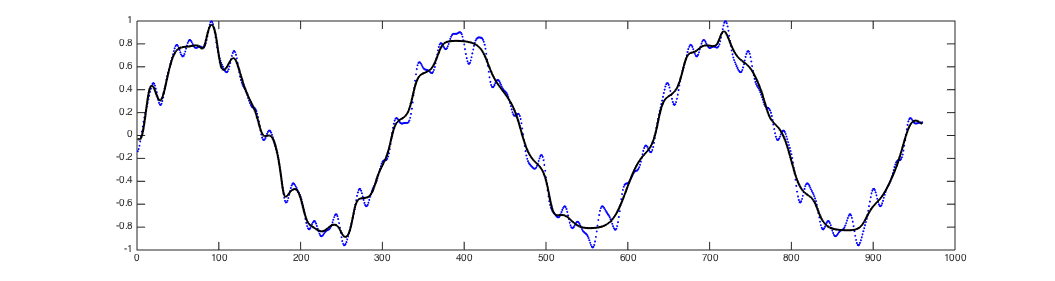
- 3-layer deep LSTM with 7 hidden units for short sequence
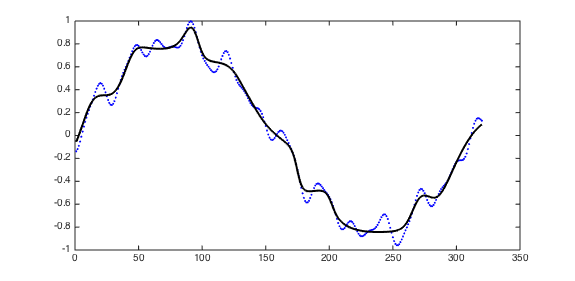
- 3-layer deep LSTM with 23 hidden units for long sequence