-
Notifications
You must be signed in to change notification settings - Fork 158
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
69 additions
and
0 deletions.
There are no files selected for viewing
69 changes: 69 additions & 0 deletions
69
docs/website/blog/2024-04-23-replacing-saas-with-python-etl.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,69 @@ | ||
| --- | ||
| slug: replacing-saas-elt | ||
| title: "Replacing Saas ETL with Python dlt: A painless experience for Yummy.eu" | ||
| image: https://storage.googleapis.com/dlt-blog-images/martin_salo_tweet.png | ||
| authors: | ||
| name: Adrian Brudaru | ||
| title: Open source Data Engineer | ||
| url: https://github.com/adrianbr | ||
| image_url: https://avatars.githubusercontent.com/u/5762770?v=4 | ||
| tags: [full code etl, yes code etl, etl, python elt] | ||
| --- | ||
|
|
||
| About [Yummy.eu](https://about.yummy.eu/) | ||
|
|
||
| Yummy is a Lean-ops meal-kit company streamlines the entire food preparation process for customers in emerging markets by providing personalized recipes, | ||
| nutritional guidance, and even shopping services. Their innovative approach ensures a hassle-free, nutritionally optimized meal experience, | ||
| making daily cooking convenient and enjoyable. | ||
|
|
||
| Yummy is a food box business. At the intersection of gastronomy and logistics, this market is very competitive. | ||
| To make it in this market, Yummy needs to be fast and informed in their operations. | ||
|
|
||
| ### Pipelines are not yet a commodity. | ||
|
|
||
| At Yummy, efficiency and timeliness are paramount. Initially, Martin, Yummy’s CTO, chose to purchase data pipelining tools for their operational and analytical | ||
| needs, aiming to maximize time efficiency. However, the real-world performance of these purchased solutions did not meet expectations, which | ||
| led to a reassessment of their approach. | ||
|
|
||
| ### What’s important: Velocity, Reliability, Speed, time. Money is secondary. | ||
|
|
||
| Martin was initially satisfied with the ease of setup provided by the SaaS services. | ||
|
|
||
| The tipping point came when an update to Yummy’s database introduced a new log table, leading to unexpectedly high fees due to the vendor’s default settings that automatically replicated new tables fully on every refresh. This situation highlighted the need for greater control over data management processes and prompted a shift towards more transparent and cost-effective solutions. | ||
|
|
||
| <aside> | ||
| 💡 Proactive management of data pipeline settings is essential. | ||
| Automatic replication of new tables, while common, often leads to increased costs without adding value, especially if those tables are not immediately needed. | ||
| Understanding and adjusting these settings can lead to significant cost savings and more efficient data use. | ||
| </aside> | ||
|
|
||
|
|
||
| ## 10x faster, 182x cheaper with dlt + async + modal | ||
|
|
||
| Motivated to find a solution that balanced cost with performance, Martin explored using dlt, a tool known for its simplicity in building data pipelines. | ||
| By combining dlt with asynchronous operations and using [Modal](https://modal.com/) for managed execution, the improvements were substantial: | ||
|
|
||
| * Data processing speed increased tenfold. | ||
| * Cost reduced by 182 times compared to the traditional SaaS tool. | ||
| * The new system supports extracting data once and writing to multiple destinations without additional costs. | ||
|
|
||
| For a peek into on how Martin implemented this solution, [please see Martin's async Postgres source on GitHub.](https://gist.github.com/salomartin/c0d4b0b5510feb0894da9369b5e649ff). | ||
|
|
||
|
|
||
| [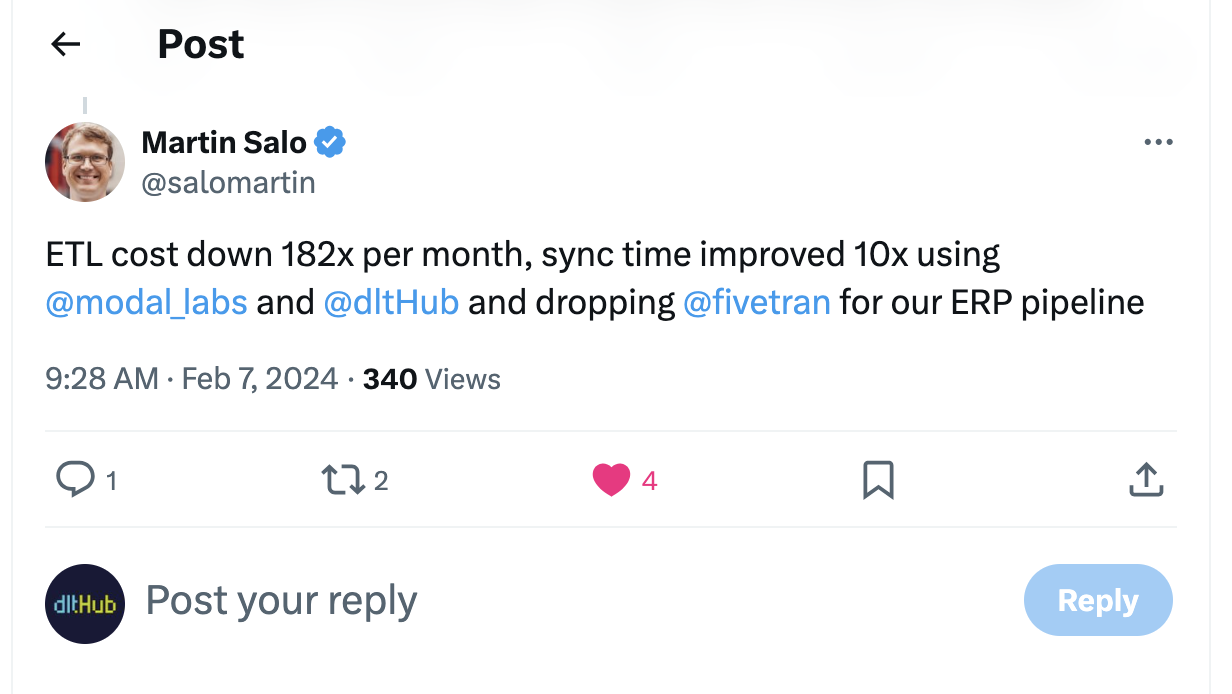](https://twitter.com/salomartin/status/1755146404773658660) | ||
|
|
||
| ## Taking back control with open source has never been easier | ||
|
|
||
| Taking control of your data stack is more accessible than ever with the broad array of open-source tools available. SQL copy pipelines, often seen as a basic utility in data management, do not generally differ significantly between platforms. They perform similar transformations and schema management, making them a commodity available at minimal cost. | ||
|
|
||
| SQL to SQL copy pipelines are widespread, yet many service providers charge exorbitant fees for these simple tasks. In contrast, these pipelines can often be set up and run at a fraction of the cost—sometimes just the price of a few coffees. | ||
|
|
||
| At dltHub, we advocate for leveraging straightforward, freely available resources to regain control over your data processes and budget effectively. | ||
|
|
||
| Setting up a SQL pipeline can take just a few minutes with the right tools. Explore these resources to enhance your data operations: | ||
|
|
||
| - [30+ SQL database sources](https://dlthub.com/docs/dlt-ecosystem/verified-sources/sql_database) | ||
| - [Martin’s async PostgreSQL source](https://gist.github.com/salomartin/c0d4b0b5510feb0894da9369b5e649ff) | ||
| - [Arrow + connectorx](https://www.notion.so/Martin-Salo-Yummy-2061c3139e8e4b7fa355255cc994bba5?pvs=21) for up to 30x faster data transfers | ||
|
|
||
| For additional support or to connect with fellow data professionals, [join our community](https://dlthub.com/community). |