We want to be able “bridge” different blockchains. We do so by safely sharing and verifying
information about each chain’s state, i.e. blockchain A should be able to verify that blockchain B
is at block #X.
Finality in blockchains is a concept that means that after a given block #X has been finalized, it will never be reverted (e.g. due to a re-org). As such, we can be assured that any transaction that exists in this block will never be reverted.
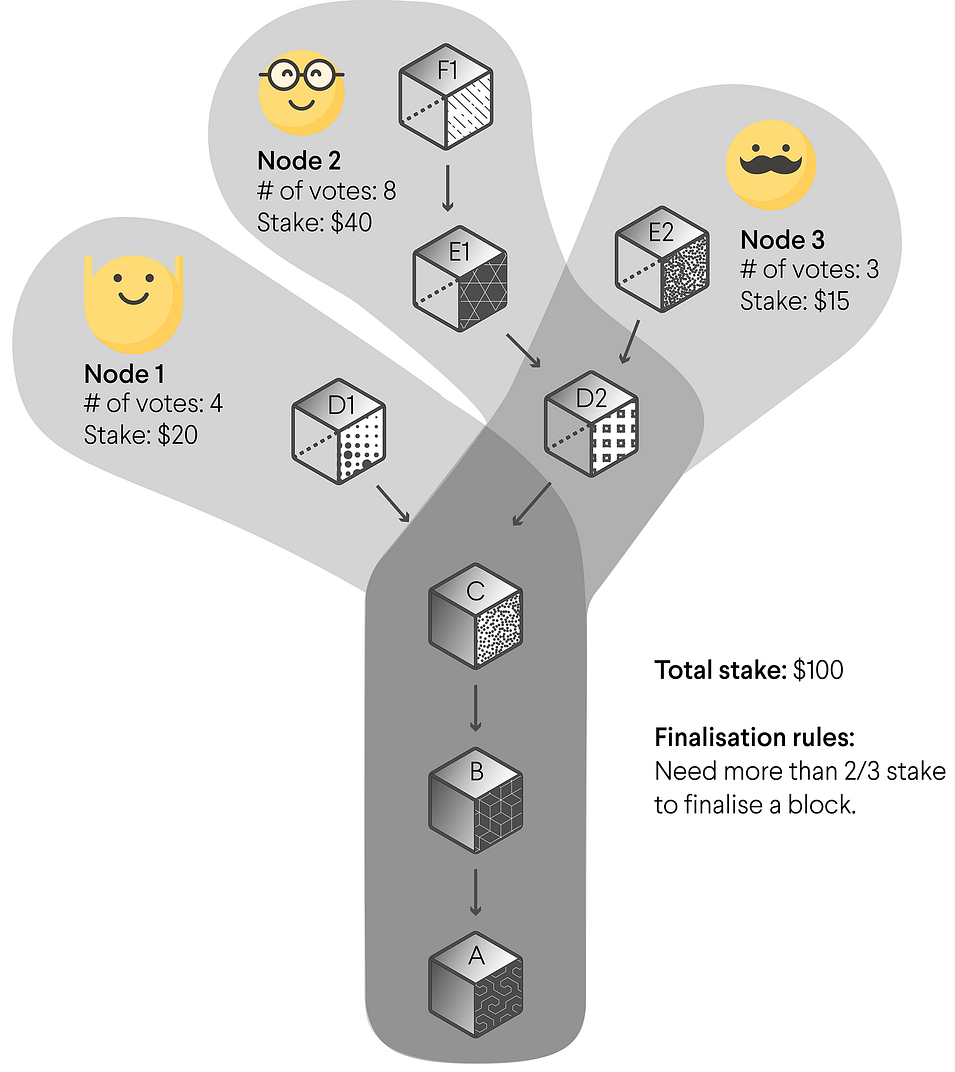
GRANDPA is our finality gadget. It allows a set of nodes to come to BFT agreement on what is the canonical chain. It requires that 2/3 of the validator set agrees on a prefix of the canonical chain, which then becomes finalized.
struct Justification<Block: BlockT> {
round: u64,
commit: Commit<Block>,
votes_ancestries: Vec<Block::Header>,
}
struct Commit<Hash, Number, Signature, Id> {
target_hash: Hash,
target_number: Number,
precommits: Vec<SignedPrecommit<Hash, Number, Signature, Id>>,
}
struct SignedPrecommit<Hash, Number, Signature, Id> {
precommit: Precommit<Hash, Number>,
signature: Signature,
id: Id,
}
struct Precommit<Hash, Number> {
target_hash: Hash,
target_number: Number,
}The main difficulty of verifying GRANDPA finality proofs comes from the fact that voters are voting on different things. In GRANDPA each voter will vote for the block they think is the latest one, and the protocol will come to agreement on what is the common ancestor which has > 2/3 support.
This creates two sets of inefficiencies:
- We may need to have each validator’s vote data because they’re all potentially different (i.e. just the signature isn’t enough).
- We may need to attach a couple of headers to the finality proof in order to be able to verify all of the votes’ ancestries.
Additionally, since our interim goal is to bridge to Ethereum there is also a difficulty related to “incompatible” crypto schemes. We use `ed25519` signatures in GRANDPA which we can’t efficiently verify in the EVM.
As we bridge the information of each chain by relying on finality proofs we will not be doing this for every block. Therefore we might prove that block #5 with hash 0x42 was finalized, and later on we prove that block #10 with hash 0x1337 was finalized. But how do we prove what are the blocks #6-#9? The easiest way to do this is to just relay all of these headers, then we can verify the chain is correct. The downside of this is that we require syncing all of these intermediary headers which might not be feasible due to costs.
In order to create efficient proofs of block ancestry we rely on good old merkle proofs. We
merkelize all of the block header hashes which then allows us to prove that a given hash is part of
the tree with just log(n) nodes.
Merkle mountain ranges are just merkle trees with an efficient append operation.
To overcome the difficulty with GRANDPA finality proofs we will run a separate round of BFT agreement where each voter will be voting on the same thing. Namely, each voter will be voting on the MMR root of the latest block finalized by GRANDPA.
This is a completely separate protocol from GRANDPA but which piggybacks on it.
Using ECDSA for easier Ethereum compatibility.
It exists and works! Main TODO items are:
- Improve API for proof generation
- Pruning of non-peak nodes from storage
- Some low-level issues with the MMR implementation we are using.
Tomek should be able to say much more about this!
-
The pallet is mainly a thin layer of integration with the session module. It keeps track of the current authorities and emits a digest whenever these should change.
-
The primitives define the types of most of the statements that we will be signing as part of the BEEFY protocol. These were important to define as early as possible since the Snowfork team will be looking at these from the EVM side.
A working POC of the basic BEEFY round logic.
- We listen to GRANDPA finality notifications
- As we finalize new blocks we start a new BEEFY round for:
last_block_with_signed_mmr_root + NextPowerOfTwo((last_finalized_block - last_block_with_signed_mmr_root) / 2)- We fetch the MMR root for the given block (currently we fetch this from a header digest)
- We create a BEEFY commitment where the payload is the signed MMR root for the given block
struct Commitment<BlockNumber, Payload> {
payload: Payload,
block_number: BlockNumber,
validator_set_id: ValidatorSetId,
}- We gossip our vote and listen for any votes for that round, waiting until we have received > 2/3.
-
Validator set changes
The POC is currently not handling validator set changes at all and just assumes that we are always at validator set 0.
At each block we import we should check for the existence of any digest signalling a validator set change. We should then keep track of these changes as “pending changes” in a tree structure (we can reuse
ForkTreesimilar to what we are doing in GRANDPA), which are applied when the given block (or any of its descendents) is finalized. -
Round lifecycle
Currently the POC is just starting a new round according to the voting rule (next-power-of-two), regardless of how many previous rounds are still running.
We should have a more defined round lifecycle with clear rules for when we start a new round (rather than running all in parallel wildly), and also what happens to old rounds in the face of new rounds being concluded.
-
Cache MMR root
We should be listening to block import operations and as new blocks are imported we call into the runtime to fetch the latest MMR root value from storage and persist it on the client side. This will be necessary to make sure we always have the required data in the face of state pruning.
We will need to deal with forks here, as we import new blocks that might be on distinct branches. Later on we will prune this data based on finality and canonicality of each chain, i.e. if we had imported two different MMR roots for two different block #10, after one of those gets finalized the other one can be pruned.
-
Use per-round gossip topic
The current implementation is using a global gossip topic. We should be using a gossip topic for each round similar to what we do in GRANDPA.
-
Create some mechanism to avoid DDoS gossip
This ties to the point above. In order to make the gossip efficient and DDoS-proof we need to make sure we aren't gossiping useless data to our peers. Peers should exchange small messages to update each other's "view" of the protocol, i.e. peer 1 broadcasts the information that he is at round 42, a peer that is at round 20 will not be sending it any data since it would be useless.
This mechanism should be very similar to what we implemented for “polite GRANDPA”.
-
Support for bootstrapping BEEFY at arbitrary points
BEEFY will eventually be deployed on Kusama and Polkadot which are already running. This means that our client code cannot assume it is starting from genesis. The pallet should have some block number which dictates the point at which BEEFY started. We might be able to repurpose this mechanism for “restarting” BEEFY in case it is ever necessary to do so.
-
Sync with justifications
(I still need to think a bit more about what exactly needs to be done here.)
In order to verify the validator set changes correctly we need to verify at least one finality proof of the previous validator set, i.e. during validator set 1 there will be an event announcing the validator set 2, when we are syncing to make sure we are not duped we will need to verify one finality proof from validator set 1, which will implicitly attest the transition to validator set 2.
For BEEFY we are piggybacking on GRANDPA for finality, so we might be able to simply apply the validator set transitions as soon GRANDPA finalizes a given block. At the very least, in order to not rely on state being available, we might need to store the validator set transition signals on the client side, which we then apply automatically as GRANDPA finalizes blocks.
-
Slashing
We need to figure out the slashing conditions and how to prove them. We need to talk talk to research to define this.