![]()
Optimized and flexible helpers for reading large data files from cloud storages (or more generally, from the network).
Most client libraries to read from the network in Rust are async. One example is the AWS S3 client library. On the other hand, data processing systems prefer to read data using the std::io::Read trait that is blocking, partly because it is more performant for large files, partly beacause many data processing libraries such as protobuf use that trait in their interfaces. In that case, the data processing flow looks like this:

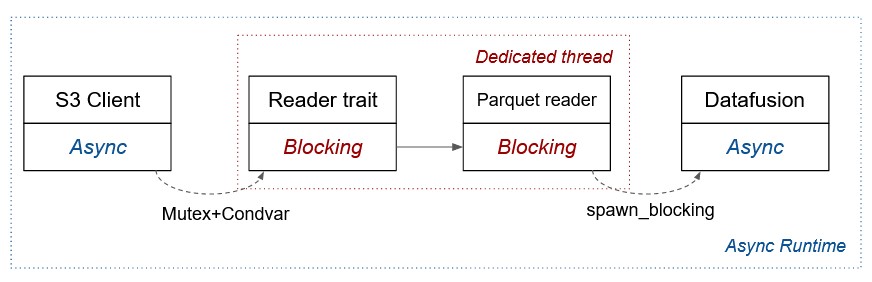
If we apply this to the example of Buzz, we get the following flow:

Additionally, the strategy to fetch data from the network will be different from reading from a high bandwith hard drive. When reading local data, the bottleneck might be the CPU and not the disk bandwidth, and even if that is not the case, you will usually not get much benefit from reading multiple chunks in parallel as one read stream will already fully utilizes the bandwidth of the disk (this might not be completely true when multiple drives are attached). The situation is completely different when reading from the network. Each read will usually be throttled on the data provider side. When using AWS S3 for instance, you get a much better overall bandwidth if you read 8 chunks in parallel (even for a single file). This means that it is worth decoupling the read strategy from the processing by eagerly downloading and caching in memory for future processings.
The proposed solution is to introduce a dedicated data structure that takes care of scheduling the downloads and caching the results, while providing a blocking API that implements the std::io::Read trait. The scheduling strategy remains customizable to adapt to different types of reads (chunks of a Parquet file will be read in a different order thant those of a CSV file) and different infrastructures (Cloud storage will behave differently from an on-premise HDFS). But most of the caching and synchronization mechanismes will be common to all the use cases.
The proposed strategy is the following one:
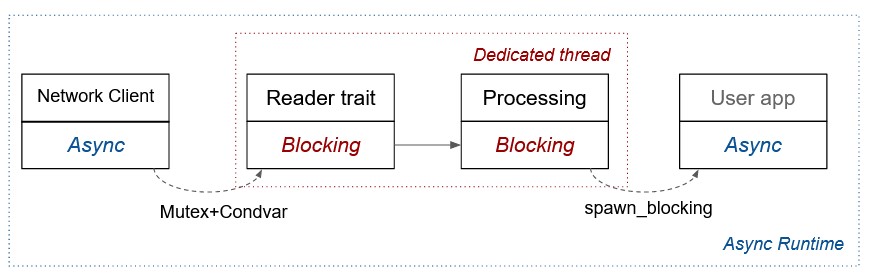
If we apply it to the specific usecase of Buzz, it boils down to this:
The library has a stats feature flag that allows to control whether it should collect execution statistics or not.