This project implements pruned rnnt for tensorflow with small limitations.
1. supports GPU only.
2. boundary information is mandatory.
It's based on the original fast RNN-T loss implementation in k2 project and following is based from https://github.com/k2-fsa/fast_rnnt
This project implements a method for faster and more memory-efficient RNN-T loss computation, called pruned rnnt.
Note: The original fast RNN-T loss implementation is in k2 project and this project is based on https://github.com/k2-fsa/fast_rnnt.
We make tf_fast_rnnt a stand-alone project for tensorflow users.
We first obtain pruning bounds for the RNN-T recursion using a simple joiner network that is just an addition of the encoder and decoder, then we use those pruning bounds to evaluate the full, non-linear joiner network.
The picture below display the gradients (obtained by rnnt_loss_simple with calc_gradients=true) of lattice nodes, at each time frame, only a small set of nodes have a non-zero gradient, which justifies the pruned RNN-T loss, i.e., putting a limit on the number of symbols per frame.
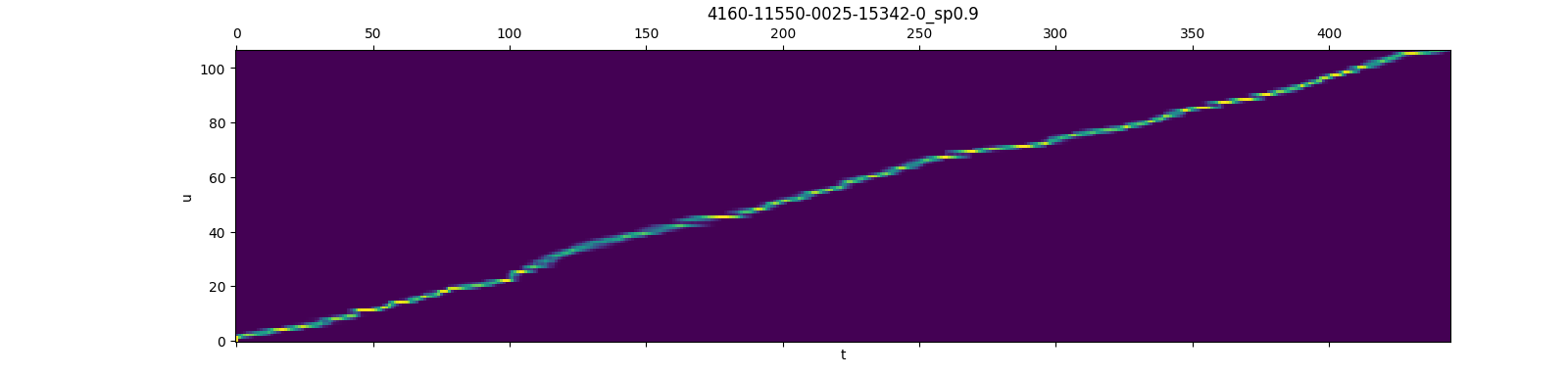
This picture is taken from here
You can install from source:
cd tf_fast_rnnt
pip install .
To check that tf_fast_rnnt was installed successfully, please run
python3 -c "import tf_fast_rnnt; print(tf_fast_rnnt.__version__)"
which should print the version of the installed tf_fast_rnnt, e.g., 1.2.
It has been tested on tensorflow >= 2.9.3.
Note: The cuda version of the tensorflow should be the same as the cuda version in your environment, or it will cause a compilation error.
This is a simple case of the RNN-T loss, where the joiner network is just addition.
Note: termination_symbol plays the role of blank in other RNN-T loss implementations, we call it termination_symbol as it terminates symbols of current frame.
am = np.random.randn(B, T, C).astype('f')
lm = np.random.randn(B, S + 1, C).astype('f')
symbols = np.random.randint(0, C - 1, (B, S)).astype(np.int32)
terminal_symbol = C - 1
boundary = np.zeros((B, 4))
boundary[:, 2] = seq_length
boundary[:, 3] = frames
simple_loss, (px_grad, py_grad) = tf_fast_rnnt.rnnt_loss_simple(
lm=lm,
am=am,
symbols=symbols,
termination_symbol=terminal_symbol,
boundary=boundary,
rnnt_type=rnnt_type,
calc_gradients=True,
reduction="none",
delay_penalty=0.2,
)rnnt_loss_pruned can not be used alone, it needs the gradients returned by rnnt_loss_simple/rnnt_loss_smoothed to get pruning bounds.
am = np.random.randn(B, T, C).astype('f')
lm = np.random.randn(B, S + 1, C).astype('f')
symbols = np.random.randint(0, C - 1, (B, S)).astype(np.int32)
terminal_symbol = C - 1
boundary = np.zeros((B, 4))
boundary[:, 2] = seq_length
boundary[:, 3] = frames
simple_loss, (px_grad, py_grad) = tf_fast_rnnt.rnnt_loss_simple(
lm=lm,
am=am,
symbols=symbols,
termination_symbol=terminal_symbol,
boundary=boundary,
rnnt_type=rnnt_type,
calc_gradients=True,
reduction="none",
delay_penalty=0.2,
)
s_range = 5 # can be other values
ranges = tf_fast_rnnt.get_rnnt_prune_ranges(
px_grad=px_grad,
py_grad=py_grad,
boundary=boundary,
s_range=s_range,
)
am_pruned, lm_pruned = tf_fast_rnnt.do_rnnt_pruning(am=am, lm=lm, ranges=ranges)
logits = model.joiner(am_pruned, lm_pruned)
pruned_loss = tf_fast_rnnt.rnnt_loss_pruned(
logits=logits,
symbols=symbols,
ranges=ranges,
termination_symbol=termination_symbol,
boundary=boundary,
reduction="sum",
)You can also find recipes here that uses rnnt_loss_pruned to train a model.
The repo compares the speed and memory usage of several transducer losses, the summary in the following table is taken from there, you can check the repository for more details.
Note: As we declared above, fast_rnnt is also implemented in k2 project, so k2 and fast_rnnt are equivalent in the benchmarking.
| Name | Average step time (us) | Peak memory usage (MB) |
|---|---|---|
| torchaudio | 601447 | 12959.2 |
| fast_rnnt(unpruned) | 274407 | 15106.5 |
| fast_rnnt(pruned) | 38112 | 2647.8 |
| optimized_transducer | 567684 | 10903.1 |
| warprnnt_numba | 229340 | 13061.8 |
| warp-transducer | 210772 | 13061.8 |