
The existing dataset for the task of Ethereum Transactions Fraud Detection is available in Kaggle Link to the Original Dataset, with 9841 samples and spread across 51 features. Besides this, the class distribution of the samples for Fraud : Legitimate = 1 : 4.
Why is the dataset the way it is :
- In the sectors of finance or health care, there is always a scarcity of data due to privacy concerns of their users. And so the size of the datasets being used for classificaiton purposes in such domains also reduces.
- Also, the number of cases having a particular condition in the domain of some health care or finance issue is very minute as compared to the number of samples which aren't affected by that condition. For example, at any point of time, the number of people infected by a virus in a population is always considerably low. This also explains why the number of frauds are very less as compared to the number of legitimate transactions in our dataset.
This leads to the following issues as :
- Such a small dataset causes our models which we use for classification tend to overfit on the training set and do not capture the necessary root causes for finding frauds in the ecosystem.
- In addition to an already existing small dataset, the outliers and incomplete samples also cause the dataset to diminish on data pre processing steps.
- When our models are exposed to such a skewed datasets, they get trained on a very few fraud transactions due to the imbalanced nature of the data; which creates a hard time for the model to detect frauds in a real time system as there are not much patterns which can be learnt.
- This may lead to misclassification of some fruadulent transactions as legitimate ones, and they persist in the ecosystem and adversely affecting other innocent transactors.
Our methodology to fix the issues :
- We've considered generating new synthetic data samples from our already existing dataset by employing the CTGAN Model CTGANSynthesizer Model which is very suitable for generating samples statisitcally representative of our original tabular dataset.
- Then we made use of cost sensitive learning while using our classification models inorder to minimize the misclassification of fraud samples. This is accomplished by assigning higher misclassification costs for missing out fraudulent transactions thus helping the model in prioritizing which error costs to minimize.
Tasks Accomplished :
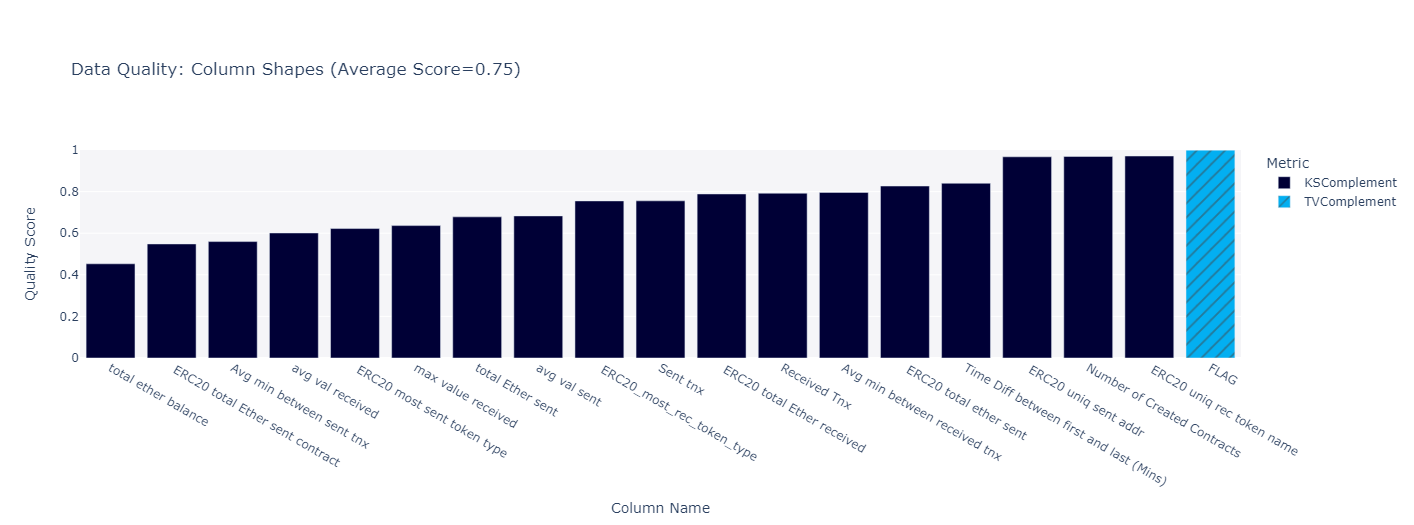
- Successfully created an aggregated dataset by doubling the original dataset with synthetic data samples, which have
85.63% similarity qualitywith the existing dataset Aggregated Dataset available here. - The incorporation of Cost Sensitive Learning depicts the usefulness of our models for real time detection systems which can afford identifying legitimate as fraud ones, as we can reassure this with the transactors; rather than allowing a fraudulent transaction to harm the ecosystem as it couldn't be detected by our system.
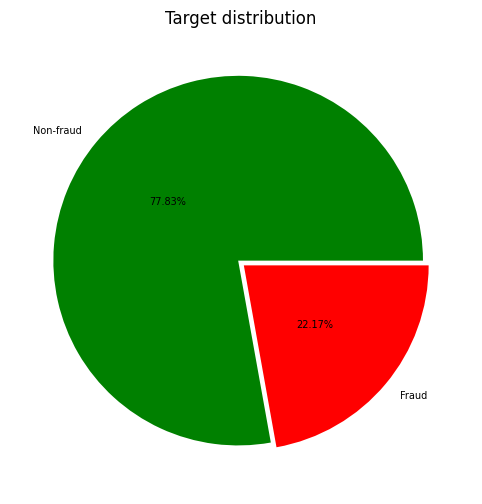
Overall Distribution of the FLAG Column
| Model | Accuracy | Precision | Recall |
|---|---|---|---|
| Decision Tree Classifier | 0.9805 | 0.9827 | 0.9309 |
| Random Forest Classifier | 0.9837 | 0.9898 | 0.938 |
| AdaBoost Classifier | 0.9798 | 0.9673 | 0.9435 |
| Light Gradient Boosting Machine | 0.9881 | 0.987 | 0.9606 |
| Extreme Gradient Boosting Machine | 0.99 | 0.9857 | 0.9703 |
Evaluation Metrics of Models without Cost Sensitive Learning
| Model | Accuracy | Precision | Recall |
|---|---|---|---|
| Decision Tree Classifier | 0.9781 | 0.9524 | 0.9517 |
| Random Forest Classifier | 0.9854 | 0.986 | 0.9494 |
| AdaBoost Classifier | 0.977 | 0.9416 | 0.9584 |
| Light Gradient Boosting Machine | 0.9897 | 0.9842 | 0.9703 |
| Extreme Gradient Boosting Machine | 0.9907 | 0.9842 | 0.9747 |
Evaluation Metrics of Models using Cost Sensitive Learning(= 3)