简单的transformer架构复现llm模型
本项目实现了手搓一个简单的续写GPT
具体实现:从 基础二元语言模型 到 基于Transform架构(Only Decoder)的GPT模型
- BigramLanguageModel 数据集:绿野仙踪
- GPT 数据集:Openwebtext
jupyter: 1.biagram.ipynb
- python=3.10
pip install matplotlib numpy pylzma ipykernel# torch 安装适合cuda的版本
# torch=2.1.0
# 略torch pip下载慢可以用conda下载,换清华源
# 换源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
# conda下载torch
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia下载绿野仙踪
https://www.gutenberg.org/ebooks/22566
点击Plain Text下载
做一些处理,删除一些不需要的文本,以防干扰训练
- 保留的文本从这一段开始,前面的都删掉
DOROTHY AND THE WIZARD IN OZ
BY
L. FRANK BAUM
AUTHOR OF THE WIZARD OF OZ, THE LAND OF OZ, OZMA OF OZ, ETC.
ILLUSTRATED BY JOHN R. NEILL
BOOKS OF WONDER WILLIAM MORROW & CO., INC. NEW YORK
- 把从这里开始到最后的部分都删掉
End of Project Gutenberg's Dorothy and the Wizard in Oz, by L. Frank Baum
...
然后我们得到了一个用于训练的文本,之后会在这个文本上训练一个transformer,或者至少一个后台语言模型。
在进行其他工作之前,要知道如何操作文本
with open('./wizard_of_oz.txt', 'rw', encoding='utf-8') as f:
text = f.read()
print(text[:200])把它们放入一个我们可以使用的小词汇表中
with open('./wizard_of_oz.txt', 'r', encoding='utf-8') as f:
text = f.read()
# 文本中所有字符的集合
chars = sorted(set(text))
print(chars)分词器(tokenizer)由encoder和decoder组成
- encoder:将这个数组的每一个元素转化为整数(比如有十个字符,那么可以编码为0-9)
# 字符到索引的映射
string_to_int = {ch:i for i, ch in enumerate(chars)}
int_to_string = {i:ch for i, ch in enumerate(chars)}
# encoder 和 decoder
encode = lambda s: [string_to_int[c] for c in s]
decode = lambda l: ''.join([int_to_string[i] for i in l]) # 接受一个整数列表 l 转换为字符串
# 测试
en = encode('hello')
de = decode(en)
print(en)
# [61, 58, 65, 65, 68]
print(de)
# hello现在有了一个字符级tokenizer,能够将每一个字符转化为一个整数
一些补充: 字符级tokenizer,将每一个字符转化为一个整数
- 有一个非常小的词汇表(vocabulary)和大量的词元(tokens)需要转换
- 比如说现在的文本有40000个字符,虽然词汇表(可能几十个)很小,但是有许多字符需要编码和解码
单词级tokenizer,将每一个单词转化为一个整数
- 会有非常非常多的词汇,vocab会很大
- 处理的数据集会更小,因为一个文本中需要编码解码的tokens更少
子词(subword)tokenizer:介于字符级和单词级之间
在语言模型背景下,高效处理数据非常重要,拥有一个巨大的字符串可能最好的选择。
我们将使用Pytorch框架进行高效处理
import torch将所有内容放入一个张量中,这样torch可以更高效的处理
# 字符到索引的映射
string_to_int = {ch:i for i, ch in enumerate(chars)}
int_to_string = {i:ch for i, ch in enumerate(chars)}
# encoder 和 decoder
encode = lambda s: [string_to_int[c] for c in s]
decode = lambda l: ''.join([int_to_string[i] for i in l]) # 接受一个整数列表 l 转换为字符串
# 创建数据元素,对整个文本编码
data = torch.tensor(encode(text), dtype=torch.long)
# 打印前一百个字符
print(data[: 100])将数据分为训练集和验证集。
n = int(0.8*len(data))
train_data = data[:n]
val_data = data[n:]补充:什么叫做 bigram language model hello 每一次预测是一个二元组(通过前一个seq预测后一个字符seq) start of content -> h h -> e e -> l l -> l l -> 0
如何训练一个二元模型以达到我们的目标?
- 块的概念
- 从整个语料库中随机取出一小部分
- 举例:
- _ _ [ 5, 67, 21, 58, 40 ], 35 _ _ _ input
- _ _ 5, [ 67, 21, 58, 40, 35 ] _ _ _ target
用代码展示具体例子,假设block_size = 8
block_size = 8
x = train_data[: block_size]
y = train_data[1: block_size+1]
for t in range(block_size):
context = x[:t+1]
target = y[t]
print('when input is', context, 'target is', target)
# when input is tensor([80]) target is tensor(1)
# when input is tensor([80, 1]) target is tensor(1)
# when input is tensor([80, 1, 1]) target is tensor(28)
# when input is tensor([80, 1, 1, 28]) target is tensor(39)
# when input is tensor([80, 1, 1, 28, 39]) target is tensor(42)
# when input is tensor([80, 1, 1, 28, 39, 42]) target is tensor(39)
# when input is tensor([80, 1, 1, 28, 39, 42, 39]) target is tensor(44)
# when input is tensor([80, 1, 1, 28, 39, 42, 39, 44]) target is tensor(32)如果仅此,用一段序列窗口预测下一段窗口,顺序执行,这可以预测,但是不可扩展(并行)
这个过程是顺序(Sequential)的,在CPU的执行过程就是顺序的(CPU可以执行许多复杂操作,但是只能顺序执行)
而GPU可以将很多更简单的任务并行执行
所以我们可以进行大量的非常小或者计算不复杂的计算,在许多不太好但是数量大的小处理器上进行
做法:取这些小块的每一个,堆叠它们(batch)并将它们推送到GPU以大幅扩展我们的训练
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)jupyter:2.torch_example.ipynb
import torch
import time
import numpy as nptorch_rand1 = torch.rand(10000, 10000).to(device)
torch_rand2 = torch.rand(10000, 10000).to(device)
np_rand1 = torch.rand(10000, 10000)
np_rand2 = torch.rand(10000, 10000)
start_time = time.time()
rand = (torch_rand1 @ torch_rand2)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"{elapsed_time:.8f}")
# ========================
start_time = time.time()
rand = np.multiply(np_rand1, np_rand2)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"{elapsed_time:.8f}")结果:
- GPU:0.00801826
- CPU:0.00000000
- 从这个结果来看CPU还要快,因为矩阵的形状并不是很大,它 们只是二维的
如果把维度加大
torch_rand1 = torch.rand(100, 100, 100, 100).to(device)
torch_rand2 = torch.rand(100, 100, 100, 100).to(device)
np_rand1 = torch.rand(100, 100, 100, 100)
np_rand2 = torch.rand(100, 100, 100, 100)
start_time = time.time()
rand = (torch_rand1 @ torch_rand2)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"{elapsed_time:.8f}")
# ========================
start_time = time.time()
rand = np.multiply(np_rand1, np_rand2)
end_time = time.time()
elapsed_time = end_time - start_time
print(f"{elapsed_time:.8f}")- GPU:0.01275229
- CPU:0.09202719
jupyter: 1.diagram2.ipynb
跟之前一样,不过换到了GPU
import torch
import torch.nn as nn
from torch.nn import functional as F
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
block_size = 8
batch_size = 4with open('./wizard_of_oz.txt', 'r', encoding='utf-8') as f:
text = f.read()
# 文本中所有字符的集合
chars = sorted(set(text))
print(chars)
vocab_size = len(chars)# 字符到索引的映射
string_to_int = {ch:i for i, ch in enumerate(chars)}
int_to_string = {i:ch for i, ch in enumerate(chars)}
# encoder 和 decoder
encode = lambda s: [string_to_int[c] for c in s]
decode = lambda l: ''.join([int_to_string[i] for i in l]) # 接受一个整数列表 l 转换为字符串
# 创建数据元素,对整个文本编码
data = torch.tensor(encode(text), dtype=torch.long)
# 打印前一百个字符
print(data[: 100])- 分割数据集, 放入GPU
n = int(0.8*len(data))
train_data = data[:n]
val_data = data[n:]
def get_batch(split):
data = train_data if split == "train" else val_data
# 随机一个batch的索引,从0到(len(data)-block_size), 一个batch有batch_size个
# batch_size = 4
ix = torch.randint(len(data) - block_size, (batch_size,))
print(ix)
# 分批堆叠
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1: i+block_size+1] for i in ix])
# 将数据放在GPU
x, y = x.to(device), y.to(device)
return x, y
x, y = get_batch("train")
print("inputs:")
print(x)
print("targets:")
print(y)对于logits的解释,参考博客:深度学习中的 logits 、softmax,TensorFlow中的 tf.nn.softmax_cross_entropy_with_logits 、tf.nn.sparse_soft...对比_tf.logit-CSDN博客
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# 嵌入表 vocab_size * vocab_size
self.token_embeddings_table = nn.Embedding(vocab_size, vocab_size)
def forward(self, index, targets=None):
# logits
logits = self.token_embeddings_table(index)
if targets is None:
loss = None
else:
# batch, time(sequence), channels(vocab_size)
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
# 生成token的函数
def generate(self, index, max_new_tokens):
# index is (B, T) array of indices in the current context
# 根据需要生成的token数进行循环
for _ in range(max_new_tokens):
# 获得预测, 这里没有给target,返回的logits是三维的 B*T*C
logits, loss = self.forward(index)
# print("shape", logits.shape)
# 只关心最后一个时间步(time step)
logits = logits[:, -1, :] # become (B, C)
# 应用Softmax,得到概率分布 只应用最后一维
probs = F.softmax(logits, dim=-1) # (B, C)
# 从分布中取样
index_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# 增加取样的索引到当前序列
index = torch.cat((index, index_next), dim=1) # (B, T+1)
return index
model = BigramLanguageModel(vocab_size)
m = model.to(device)
# 模拟一下
context = torch.zeros((1,1), dtype=torch.long, device=device)
generated_chars = decode(m.generate(context, max_new_tokens=500)[0].tolist())
print(generated_chars) - 计算损失的函数
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ["train", "val"]:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out- 优化器及训练
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
for iter in range(max_iters):
# sample
xb, yb = get_batch("train")
# evaluate
logits, loss = model.forward(xb, yb)
optimizer.zero_grad(set_to_none=True) # 这里设置None会比设置0占用空间小很多
loss.backward()
optimizer.step()
if (iter) % eval_iters == 0:
# print(f"step:{iter}; loss:{loss.item():.5f}")
losses = estimate_loss()
print(f"step:{iter}; train loss:{losses['train']:.5f}, val loss:{losses['val']:.5f}")- 测试
context = torch.zeros((1,1), dtype=torch.long, device=device)
generated_chars = decode(m.generate(context, max_new_tokens=500)[0].tolist())
print(generated_chars)"ber,
"Wh,"As win ch avenothexpar fad y themede thre tegabethest awathe e y
bup tote wod theverro 2. tcind e, se ththed ave t, mame mery O]Zg ce no Eulvardy
any, ousstt, than t t worof m it o an t lvier sn'le ctthar, a s ilornthe, ngny whepanqul, list whe, toors ad We kilafrd talas F tardibst; re t--Vleaf as. the calincoot abutoned 16[k; nd, u. ppo m atheridnksal thimithel s l gre g shit the lasizan pus t g ple
"an hest w avern sthr toth heriowereathese Wid OO-llye hndithe sintint "Ther oun
这样的二元模型可能仍然效果不是那么好,接下来用更强大的语言模型训练
3.gpt-v1-openwebtext.ipynb
下载:https://www.kaggle.com/datasets/seanandjoanna/openwebtext
训练集,验证机数据处理见 data-extract-v2.py
与Transformer架构非常接近,但是Only Decoder
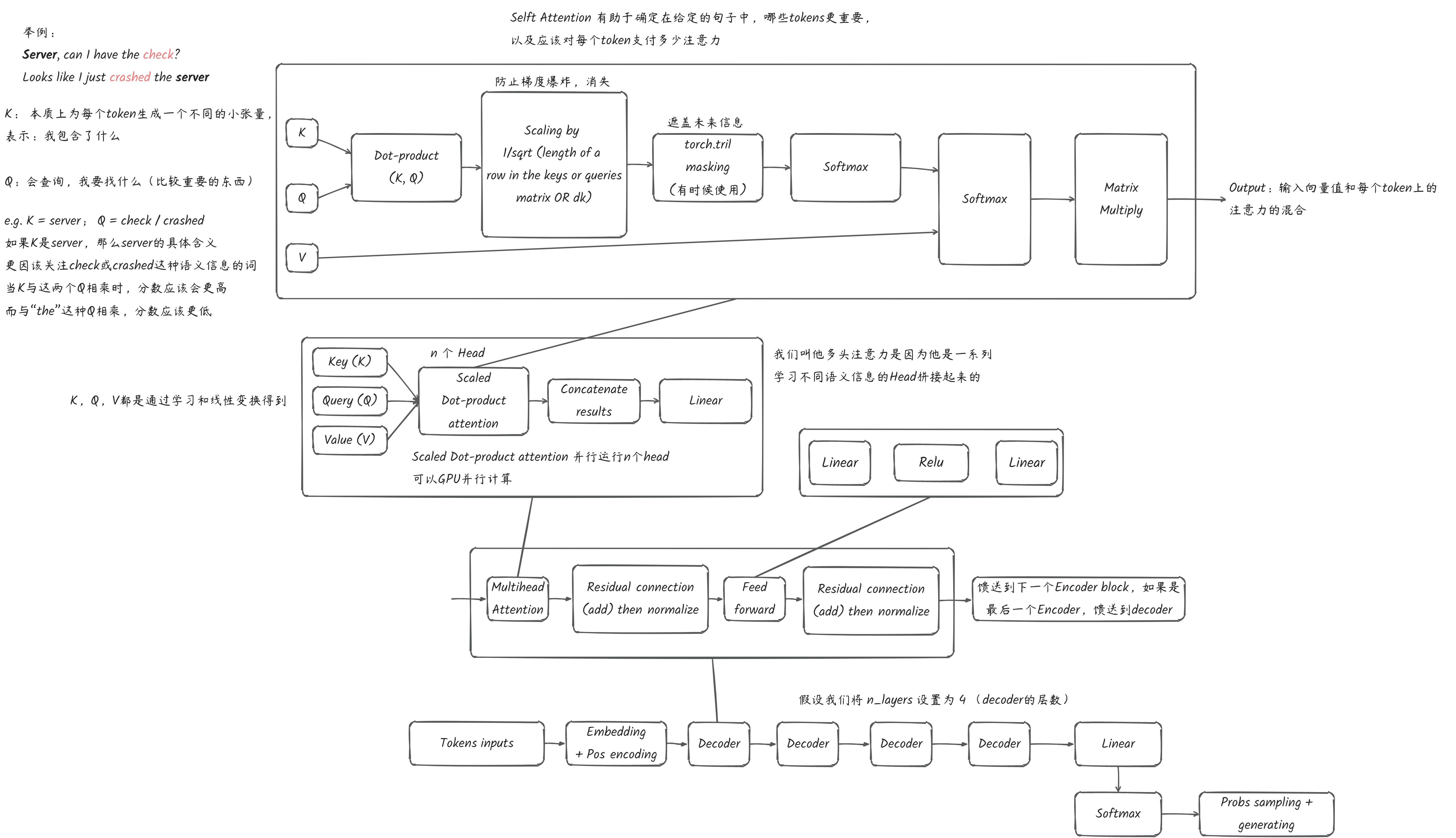
我们这里新增加了一个位置编码,以及改变了一个更大的词向量维度
# 嵌入表 vocab_size * n_embd
self.token_embeddings_table = nn.Embedding(vocab_size, n_embd)
# 位置编码 block_size:序列长度
self.position_embedding_table = nn.Embedding(block_size, n_embd)
这里使用8个decoder(n_layers = 8)
# 添加decoder blocks
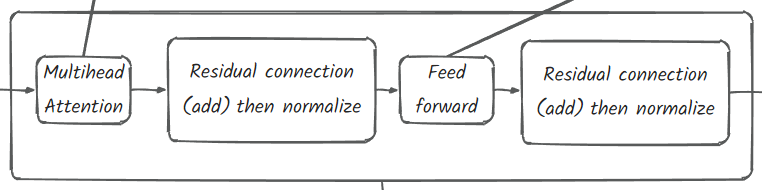
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layers) ])class Block(nn.Module):
""" Transformer block """
def __init__(self, n_embd, n_head):
# n_embd 嵌入维度 n_head:头数量
super().__init__()
# head_size 每个头在多头注意力中要捕获的特征数量
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
y = self.sa(x)
## add-norm
x = self.ln1(x + y)
y = self.ffwd(x)
x = self.ln2(x + y)
return x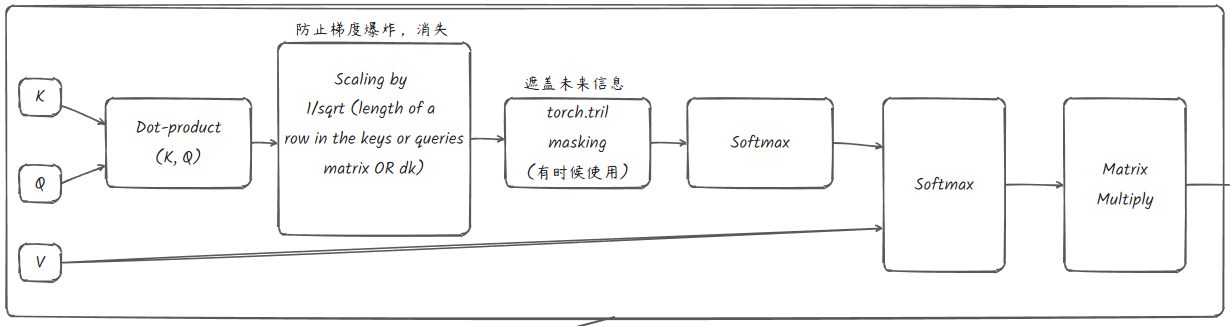
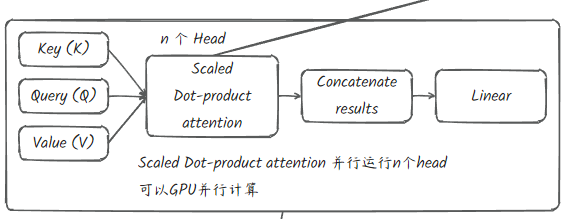
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
# 投影 projection 将头大小*头数量投影到嵌入中
# 这样写只是为了便于以后修改,可以复用
# 且能够帮助网络更多的了解这个文本,添加更多可学习的参数
self.proj = nn.Linear(head_size * num_heads, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 拼接词向量维度
out = torch.cat([h(x) for h in self.heads], dim=-1) #(B, T, C) 最后一个维度C
out = self.dropout(self.proj(out))
return outclass Head(nn.Module):
""" one head of self-attention
head_size: 这个头所捕获的特征数量
"""
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
# 掩码层, 在模型中注册 no look ahead masking
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 输入维度 (batch_size, time-step, channels)
# 输出维度 (batch_size, time-step, head_size)
B, T, C = x.shape
k = self.key(x) # (B, T, hs)
q = self.query(x) # (B, T, hs)
# 计算注意力分数 (affinities)
# (B, T, hs) * (B, hs, T) -> (B, T, T)
wei = q @ k.transpose(-2, -1) * k.shape[-1] ** -0.5
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# 执行值的加权聚合
v = self.value(x)
out = wei @ v # (B, T, T) @ (B, T, hs) -> (B, T, hs)
return out在层最后正则化能够帮助收敛
# layer norm final 帮助模型更好的收敛(层规范化)
self.ln_f = nn.LayerNorm(n_embd)最终输出的词向量线性变换为词表的维度,以方便输入softmax求得概率分布
# language model head 最终投影(变换)
self.lm_head = nn.Linear(n_embd, vocab_size)
# index 和 targets 都是 (B, T)形状的整形张量 B:batch_size T:seqLen
# (B, T, C)
tok_emb = self.token_embeddings_table(index)
# (T, C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device))
# 将这两个词向量相加
x = tok_emb + pos_emb # 广播 (B, T, C)
x = self.blocks(x) # (B, T, C)
x = self.ln_f(x) # (B, T, C)
logits = self.lm_head(x) # (B, T, vocab_size)初始化的时候最好用标准差,实践中常用,古圣先贤的经验
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)class Head(nn.Module):
""" one head of self-attention
head_size: 这个头所捕获的特征数量
"""
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
# 掩码层, 在模型中注册 no look ahead masking
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 输入维度 (batch_size, time-step, channels)
# 输出维度 (batch_size, time-step, head_size)
B, T, C = x.shape
k = self.key(x) # (B, T, hs)
q = self.query(x) # (B, T, hs)
# 计算注意力分数 (affinities)
# (B, T, hs) * (B, hs, T) -> (B, T, T)
wei = q @ k.transpose(-2, -1) * k.shape[-1] ** -0.5
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# 执行值的加权聚合
v = self.value(x)
out = wei @ v # (B, T, T) @ (B, T, hs) -> (B, T, hs)
return out
class FeedFoward(nn.Module):
""" 一个简单的前馈神经网络 """
def __init__(self,n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd),
# 防止过拟合
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
# 投影 projection 将头大小*头数量投影到嵌入中
# 这样写只是为了便于以后修改,可以复用
# 且能够帮助网络更多的了解这个文本,添加更多可学习的参数
self.proj = nn.Linear(head_size * num_heads, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 拼接词向量维度
out = torch.cat([h(x) for h in self.heads], dim=-1) #(B, T, C) 最后一个维度C
out = self.dropout(self.proj(out))
return out
class Block(nn.Module):
""" Transformer block """
def __init__(self, n_embd, n_head):
# n_embd 嵌入维度 n_head:头数量
super().__init__()
# head_size 每个头在多头注意力中要捕获的特征数量
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
y = self.sa(x)
## add-norm
x = self.ln1(x + y)
y = self.ffwd(x)
x = self.ln2(x + y)
return x
class GPTLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# 嵌入表 vocab_size * n_embd
self.token_embeddings_table = nn.Embedding(vocab_size, n_embd)
# 位置编码 block_size:序列长度
self.position_embedding_table = nn.Embedding(block_size, n_embd)
# 添加decoder blocks
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layers) ])
# layer norm final 帮助模型更好的收敛(层规范化)
self.ln_f = nn.LayerNorm(n_embd)
# language model head 最终投影(变换)
self.lm_head = nn.Linear(n_embd, vocab_size)
# 初始化参数
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
# index: (B, T)
def forward(self, index, targets=None):
B, T = index.shape
# index 和 targets 都是 (B, T)形状的整形张量 B:batch_size T:seqLen
# (B, T, C)
tok_emb = self.token_embeddings_table(index)
# (T, C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device))
# 将这两个词向量相加
x = tok_emb + pos_emb # 广播 (B, T, C)
x = self.blocks(x) # (B, T, C)
x = self.ln_f(x) # (B, T, C)
logits = self.lm_head(x) # (B, T, vocab_size)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
# 生成token的函数
def generate(self, index, max_new_tokens):
# index is (B, T) array of indices in the current context
# 根据需要生成的token数进行循环
for _ in range(max_new_tokens):
# 剪裁tokens, 不要超过block size
index_cond = index[:, -block_size:]
# 获得预测, 这里没有给target,返回的logits是三维的 B*T*C
logits, loss = self.forward(index_cond)
# print("shape", logits.shape)
# 只关心最后一个时间步(time step)
logits = logits[:, -1, :] # become (B, C)
# 应用Softmax,得到概率分布 只应用最后一维
probs = F.softmax(logits, dim=-1) # (B, C)
# 从分布中取样
index_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# 增加取样的索引到当前序列
index = torch.cat((index, index_next), dim=1) # (B, T+1)
return index
model = GPTLanguageModel(vocab_size)
m = model.to(device)
# 模拟一下
context = torch.zeros((1,1), dtype=torch.long, device=device)
generated_chars = decode(m.generate(context, max_new_tokens=500)[0].tolist())
print(generated_chars)优化器选择Adam
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ["train", "val"]:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return outoptimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
for iter in range(max_iters):
# sample
xb, yb = get_batch("train")
# evaluate
logits, loss = model.forward(xb, yb)
optimizer.zero_grad(set_to_none=True) # 这里设置None会比设置0占用空间小很多
loss.backward()
optimizer.step()
if (iter) % eval_iters == 0:
# print(f"step:{iter}; loss:{loss.item():.5f}")
losses = estimate_loss()
print(f"step:{iter}; train loss:{losses['train']:.5f}, val loss:{losses['val']:.5f}")
if iter != 0 and iter % 500 == 0:
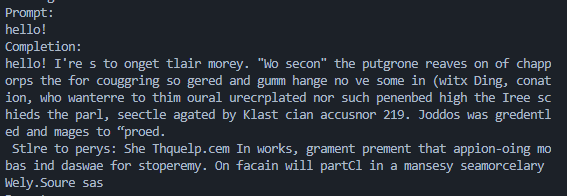
torch.save(model.state_dict(), f"./checkpoints/model_{iter}.pt")使用500次epoch的模型的效果:
- RNNs
- Transformer 2017
- BERT 2018
- GPT 2018
- GPT-v2 2019
- GPT-v3 2020