Author: Vivienne DiFrancesco
The contents of this repository detail an analysis of classification of Tanzanian water wells as either functional, non functional, or needs repair. This analysis is detailed in hopes of making the work accessible and replicable. A Tableau Public story was created in companion with this project and can be found here: https://public.tableau.com/profile/vivienned
- README.md: The top level README for reviewers of this project
- main_notebook.ipynb: narritive documentation of analysis in jupyter notebook
- TanzaniaWaterWellsSlides.pdf: pdf version of project presentation slides
- Data folder: Contains datasets used in this project

The purpose of this project is to use machine learning classification models to predict the functional status of water wells in Tanzania. The different status groups for classification are functional, non functional, and functional but needs repair. The hope is that by predicting the functional status of a well, access to water could be improved across Tanzania.
The data used for this project is from the Data Driven website where, at the time of completing this project, it is an active competition. The dataset contains nearly 60,000 records of water wells across Tanzania. Each record has information that includes various location data, technical specifications of the well, information about the water, etc. The website provides a list of the features contained and a brief description of each. The link to the website to obtain the data for yourself is: https://www.drivendata.org/competitions/7/pump-it-up-data-mining-the-water-table/
You can also get the .csv files from the "Data" folder of this repository.
The approach for this project was to create many different model types to see what performs the best and to compare and contrast the different types of models. The way the data was preprocessed with feature engineering, filling missing values, and scaling was done with the goal of increasing accuracy of the models. The OSEMiN process is the overarching structure of this project.
To account for the class imbalance, SMOTENC was used to oversample the "needs repair" and "nonfunctiona" classes. Originally, the class weight parameter was used in training of the models but it was found that SMOTENC performed better.
For each type of model, a model was first trained and fitted with default parameters as a base. Then, key parameters were chosen to tune using sklearn GridSearchCV and the best parameters were used to run the model. Performance was compared to the base model of each type, as well as between different model types. Micro recall was used as the scoring metric for optimization for tuning. Models were evaluated using a classification report, a confusion matrix, ROC plots with AUC scores, and feature importances where applicable.
For the final model, various methods for understanding the important features from the model were analyzed before making recommendations.
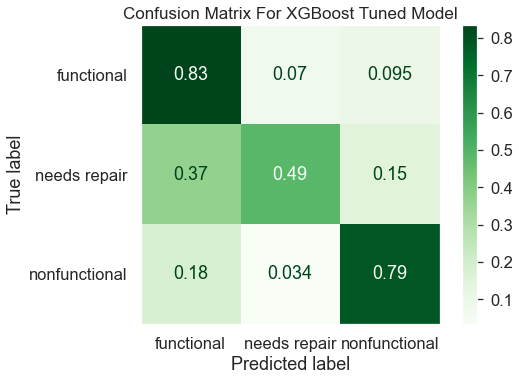
Confusion matrix results of the XGBoost model
-
Wells that are known to be dry should be considered for looking at most closely as that would make a well most likely to be non functional. Dry wells were the most important feature for the best model.
-
The construction year is an important modeling feature with older wells being more likely to be non functional or need repair. With further analysis an ideal time frame of when to service wells could be found that would balance cost and prevention of wells being out of service.
-
The population around the well was another important modeling feature. Wells with a lower surrounding population should be checked for maintenance as the median population was lower for wells in the needs repair and non functional classes.
-
Having so many of the models use location data like latitude, longitude, region, and LGA as important features for prediction means that where the well is located is a big factor of whether it is working or not. This matter should be investigated to try to bridge any disparity gaps and bring more reliable water wells to the regions with the most non functioning wells.
-
The features that were added of distance to the nearest city and servicing water lab came up often as important features so they should be added to the data collection process of the wells.
-
To get better results, especially on the needs repair class, more features will need to be added during the data collection process. Adding information in the reporting of wells such as when the well was last serviced, what kind of repairs have been done on the wells, or if any parts have been replaced in the reporting of wells could prove to be useful for better predictions.
-
Try more model types - For example, Catboost is a model that is supposed to work well on data with many categorical features. This dataset has more categorical features than numerical so it may be worth testing.
-
Further tuning - It's possible that more fine tuning of models could bring more accuracy. For example, there is plenty of opportunity to try more parameters or meta classifiers with the stacking classifier.
-
More feature engineering - More research could possibly bring up more features to add to the dataset like were found with the servicing water labs. Or if there was some manipulating of certain features in the dataset to bring out more meaningful features.