时间序列预测是时间序列分析中最重要的任务之一。随着深度学习模型的快速发展,这一领域的研究工作显著增加。深度学习模型不仅在预测任务中表现出色,还在表示学习中展现了卓越的性能,通过提取抽象表示,这些模型可以迁移到分类和异常检测等下游任务中,达到最先进的性能。
在众多深度学习模型中,Transformer在自然语言处理(NLP)、计算机视觉(CV)、语音处理等应用领域取得了巨大成功。最近,Transformer也被成功应用于时间序列数据,其注意力机制可以自动学习序列元素之间的连接,因此非常适合顺序建模任务。尽管具有复杂设计的Transformer模型在时间序列预测中取得了显著成果(如Informer、Autoformer和FEDformer),但最近的研究表明,简单的线性模型在多种常见基准测试中可以超越之前所有的Transformer模型,这对Transformer在时间序列预测中的有效性提出了质疑。
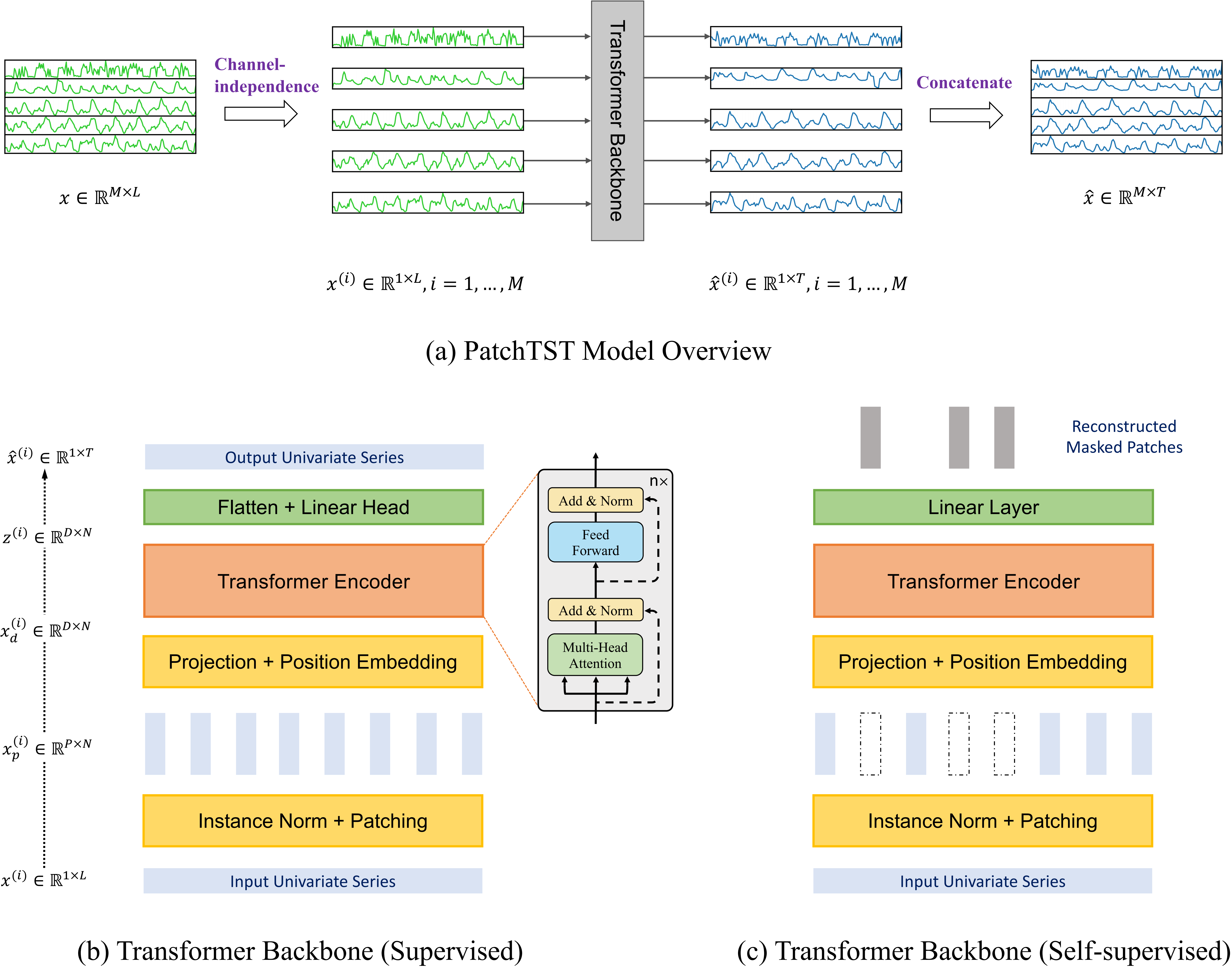
本文提出了一种高效的Transformer模型设计,旨在解决多变量时间序列预测和自监督表示学习问题。该模型由两个关键组件构成:
(i) 将时间序列分割成子序列级别的patch,并作为输入token传递给Transformer;
(ii) 通道独立性,每个通道包含单一的单变量时间序列,并在所有序列中共享相同的嵌入和Transformer权重。patching设计自然具有三重好处:保留嵌入中的局部语义信息;在相同的回溯窗口下,注意力图的计算和内存使用量成平方降低;模型可以关注更长的历史数据。
我们的通道独立patch时间序列Transformer(PatchTST)与现有的最先进的Transformer模型相比,显著提高了长期预测的准确性。此外,我们还将该模型应用于自监督预训练任务,并在微调性能上取得了优异表现,超越了在大型数据集上的监督训练。将一个数据集上的掩码预训练表示迁移到其他数据集上也产生了最先进的预测准确性。
关键设计:
🌟 补丁:将时间序列分割成子系列级别的补丁,这些补丁作为 Transformer 的输入token。
🌟 通道独立性:每个通道都包含一个单变量时间序列,该时间序列在所有序列中共享相同的嵌入和 Transformer 权重。
本项目使用MindTorch将PyTorch训练脚本高效迁移至MindSpore框架执行。
MindTorch介绍:
目的是在不改变原有PyTorch用户的使用习惯情况下,使得PyTorch代码能在昇腾上获得高效性能。

- PyTorch接口支持: MindTorch目前支持大部分PyTorch常用接口适配。用户接口使用方式不变,基于MindSpore动态图或静态图模式下执行在昇腾算力平台上。可以在torch接口支持列表中查看接口支持情况。
- TorchVision接口支持: MindTorch TorchVision是迁移自PyTorch官方实现的计算机视觉工具库,延用PyTorch官方API设计与使用习惯,内部计算调用MindSpore算子,实现与torchvision原始库同等功能。可以在TorchVision接口支持列表中查看接口支持情况。
版本:2.3.0-rc2
硬件平台:Ascend
操作系统:Linux-x86_64
Python版本:Python 3.9
安装方式:
Pip
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.3.0rc2/MindSpore/unified/x86_64/mindspore-2.3.0rc2-cp39-cp39-linux_x86_64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simpleconda
conda install mindspore=2.3.0rc2 -c mindspore -c conda-forge验证是否安装成功:
python -c "import mindspore;mindspore.set_context(device_target='Ascend');mindspore.run_check()"如果输出:
MindSpore version: 版本号
The result of multiplication calculation is correct, MindSpore has been installed on platform [Ascend] successfully!说明MindSpore安装成功了。
升级MindSpore版本
从MindSpore 1.x升级到MindSpore 2.x版本时,需要先手动卸载旧版本:
conda remove mindspore-ascend
# 然后安装新版本:
conda install mindspore -c mindspore -c conda-forge
#从MindSpore 2.x版本升级时,执行如下命令:
conda update mindspore -c mindspore -c conda-forge
# 注意:升级MindSpore Ascend版本conda安装包后请重新安装昇腾AI处理器配套软件包提供的whl包。首先卸载旧版本:
pip uninstall te topi hccl -y
# 然后重新安装:
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/te-*-py3-none-any.whl
pip install /usr/local/Ascend/ascend-toolkit/latest/lib64/hccl-*-py3-none-any.whl其他可参考:MindSpore官网
- 通过pip安装
# (MindSpore版本 >= 2.2.1)
pip install mindtorch
# (MindSpore版本 == 2.0.0)
pip install msadapter- 通过源码安装
git clone https://git.openi.org.cn/OpenI/MSAdapter.git
cd MSAdapter
python setup.py install如果出现权限不足的提示,请按照如下方式安装:
python setup.py install --user || exit 1使用MindTorch迁移PyTorch网络前,第一步是替换导入模块路径。
方法一:一行代码自动替换
在PyTorch源代码主入口调用torch系列相关的包导入部分之前调用from mindtorch.tools import mstorch_enable ,代码执行时torch同名的导入模块会自动被转换为mindtorch相应的模块。
如本项目的主入口程序是:run_longExp.py,那么在文件最开头加入以下代码:
from mindtorch.tools import mstorch_enable # 需要在主入口文件导入torch相关模块的前面使用方法二:工具手动预先替换
替换代码中导入torch相关包的代码,可以利用mindtorch/tools下提供的replace_import_package工具可快速完成工程代码中torch及torchvision相关导入包的替换。
bash replace_import_package.sh [Project Path]Project Path为需要进行替换的工程路经,默认为"./"。
文件位置:https://openi.pcl.ac.cn/OpenI/MSAdapter/src/branch/master/mindtorch/tools/replace_import_package.sh
直接在项目根目录下进行执行该命令,即可自动替换所有代码。
也可以逐文件手动的替换文件中的导入包部分代码,示例代码如下:
# 替换前
# import torch
# import torch.nn as nn
# import torch.nn.functional as F
# from torchvision import datasets, transforms
# 替换后
import mindtorch.torch as torch
import mindtorch.torch.nn as nn
import mindtorch.torch.nn.functional as F
from mindtorch.torchvision import datasets, transforms监督学习和自我监督学习的代码分为 2 个文件夹: PatchTST_supervised 和 PatchTST_self_supervised
- 安装依赖包:
pip install -r requirements.txt- 下载数据集:
可以从Autoformer下载所有用到的数据集。在项目根目录下创建文件夹:./dataset,并将所有 csv 文件放在该目录中。

如上图所示,下载完成后得到的数据集。
- 训练:
所有脚本都在目录中 ./scripts/PatchTST 。默认型号为 PatchTST/42。例如,如果要获取天气数据集的多变量预报结果,只需运行以下命令,即可在训练完成后打开 ./result.txt 查看结果:
sh ./scripts/PatchTST/weather.sh-
与2.4前两个步骤一样,安装依赖包并下载数据集。
-
预训练:scirpt patchtst_pretrain.py是训练 PatchTST/64。要在 ettm1 上使用单个 GPU 运行代码,只需运行以下命令。
python patchtst_pretrain.py --dset ettm1 --mask_ratio 0.4模型将保存到下游任务的 saved_model 文件夹中。在patchtst_pretrain.py脚本中还可以设置其他几个参数。
- 微调:脚本patchtst_finetune.py用于微调步骤。可以对整个网络进行linear_probing或微调。
python patchtst_finetune.py --dset ettm1 --pretrained_model <model_name>与基于 Transformer 的型号所能提供的最佳结果相比,PatchTST/64 实现了 MSE 总体减少 21.0% 和 MAE 减少 16.7%,而 PatchTST/42 实现了 MSE 总体减少 20.2% 和 MAE 减少 16.4%。它的性能也优于其他非基于 Transformer 的模型,如 DLinear。

与其他监督和自监督模型进行了比较,自监督 PatchTST 能够优于所有基线。


我们还测试了将预训练模型转移到下游任务的能力。

随着回溯窗口的增加,PatchTST 会持续降低 MSE 分数,这证实了模型能够从更长的感受野中学习。

预训练参数如下所示,其他默认。
| 参数名称 | 值 |
|---|---|
| dset_pretrain | ettm1 |
| context_points | 512 |
| target_points | 96 |
| batch_size | 64 |
| patch_len | 12 |
| stride | 12 |
| n_layers | 3 |
| n_heads | 16 |
| d_model | 128 |
| mask_ratio | 0.4 |
训练日志:
args: Namespace(batch_size=64, context_points=512, d_ff=512, d_model=128, dropout=0.2, dset_pretrain='ettm1', features='M', head_dropout=0.2, lr=0.0001, mask_ratio=0.4, model_type='based_model', n_epochs_pretrain=10, n_heads=16, n_layers=3, num_workers=0, patch_len=12, pretrained_model_id=1, revin=1, scaler='standard', stride=12, target_points=96)
number of patches: 42
number of model params 603404
suggested_lr 0.000298364724028334
number of patches: 42
number of model params 603404
epoch train_loss valid_loss time
Better model found at epoch 0 with valid_loss value: 0.9633879239606127.
0 0.987340 0.963388 00:23
1 0.969473 0.964801 00:23
Better model found at epoch 2 with valid_loss value: 0.7999917088347921.
2 0.942842 0.799992 00:23
Better model found at epoch 3 with valid_loss value: 0.4354643907275711.
3 0.682230 0.435464 00:23
Better model found at epoch 4 with valid_loss value: 0.3089567876435996.
4 0.509751 0.308957 00:23
Better model found at epoch 5 with valid_loss value: 0.2819502188183807.
5 0.403407 0.281950 00:23
Better model found at epoch 6 with valid_loss value: 0.2734085450287199.
6 0.368505 0.273409 00:23
Better model found at epoch 7 with valid_loss value: 0.26829308841630195.
7 0.354000 0.268293 00:23
Better model found at epoch 8 with valid_loss value: 0.2661328766069475.
8 0.347698 0.266133 00:23
Better model found at epoch 9 with valid_loss value: 0.26483733930525166.
9 0.344991 0.264837 00:23
pretraining completed
这里以监督学习为例,利用PatchTST/42获取天气数据集的多变量预报结果。
sh ./scripts/PatchTST/weather.sh当预测长度pre_len参数为96时,训练日志如下:
Args in experiment:
Namespace(activation='gelu', affine=0, batch_size=128, c_out=7, checkpoints='./checkpoints/', d_ff=256, d_layers=1, d_model=128, data='custom', data_path='weather.csv', dec_in=7, decomposition=0, des='Exp', devices='0,1,2,3', distil=True, do_predict=False, dropout=0.2, e_layers=3, embed='timeF', embed_type=0, enc_in=21, factor=1, fc_dropout=0.2, features='M', freq='h', gpu=0, head_dropout=0.0, individual=0, is_training=1, itr=1, kernel_size=25, label_len=48, learning_rate=0.0001, loss='mse', lradj='type3', model='PatchTST', model_id='336_96', moving_avg=25, n_heads=16, num_workers=10, output_attention=False, padding_patch='end', patch_len=16, patience=20, pct_start=0.3, pred_len=96, random_seed=2021, revin=1, root_path='./dataset/', seq_len=336, stride=8, subtract_last=0, target='OT', test_flop=False, train_epochs=100, use_amp=False, use_gpu=True, use_multi_gpu=False)
Use GPU: cuda:0
>>>>>>>start training : 336_96_PatchTST_custom_ftM_sl336_ll48_pl96_dm128_nh16_el3_dl1_df256_fc1_ebtimeF_dtTrue_Exp_0>>>>>>>>>>>>>>>>>>>>>>>>>>
train 36456
val 5175
test 10444
iters: 100, epoch: 1 | loss: 0.7078106
speed: 0.2415s/iter; left time: 6835.8982s
iters: 200, epoch: 1 | loss: 0.7264591
speed: 0.2388s/iter; left time: 6733.1824s
Epoch: 1 cost time: 68.15874147415161
Epoch: 1, Steps: 284 | Train Loss: 0.7472540 Vali Loss: 0.5415610 Test Loss: 0.2214899
Validation loss decreased (inf --> 0.541561). Saving model ...
Updating learning rate to 0.0001
iters: 100, epoch: 2 | loss: 0.3509977
speed: 0.5582s/iter; left time: 15640.3718s
iters: 200, epoch: 2 | loss: 0.4071708
speed: 0.2387s/iter; left time: 6662.4881s
Epoch: 2 cost time: 68.16583466529846
Epoch: 2, Steps: 284 | Train Loss: 0.4904773 Vali Loss: 0.4162776 Test Loss: 0.1690703
Validation loss decreased (0.541561 --> 0.416278). Saving model ...
Updating learning rate to 0.0001
iters: 100, epoch: 3 | loss: 0.4483804
speed: 0.5584s/iter; left time: 15487.3502s
iters: 200, epoch: 3 | loss: 0.4230699
speed: 0.2389s/iter; left time: 6602.8151s
...................................................
...................................................
Epoch: 36 cost time: 68.18052196502686
Epoch: 36, Steps: 284 | Train Loss: 0.4094809 Vali Loss: 0.3949354 Test Loss: 0.1505278
EarlyStopping counter: 18 out of 20
Updating learning rate to 3.090315438263264e-06
iters: 100, epoch: 37 | loss: 0.5415239
speed: 0.5584s/iter; left time: 10093.6534s
iters: 200, epoch: 37 | loss: 0.9917629
speed: 0.2388s/iter; left time: 4292.9295s
Epoch: 37 cost time: 68.18944597244263
Epoch: 37, Steps: 284 | Train Loss: 0.4093141 Vali Loss: 0.3935625 Test Loss: 0.1507389
EarlyStopping counter: 19 out of 20
Updating learning rate to 2.7812838944369375e-06
iters: 100, epoch: 38 | loss: 0.5711303
speed: 0.5603s/iter; left time: 9968.9802s
iters: 200, epoch: 38 | loss: 0.5285525
speed: 0.2388s/iter; left time: 4225.5097s
Epoch: 38 cost time: 68.19268894195557
Epoch: 38, Steps: 284 | Train Loss: 0.4089722 Vali Loss: 0.3933101 Test Loss: 0.1504345
EarlyStopping counter: 20 out of 20
Early stopping
>>>>>>>testing : 336_96_PatchTST_custom_ftM_sl336_ll48_pl96_dm128_nh16_el3_dl1_df256_fc1_ebtimeF_dtTrue_Exp_0<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
test 10444
mse:0.15200510621070862, mae:0.20024904608726501, rse:0.513616681098938模型测试结果下,分别是0轮、20轮、40轮、60轮、80轮的结果:

当修改预测长度为:当预测长度pre_len参数为192时,训练日志如下:
Args in experiment:
Namespace(activation='gelu', affine=0, batch_size=128, c_out=7, checkpoints='./checkpoints/', d_ff=256, d_layers=1, d_model=128, data='custom', data_path='weather.csv', dec_in=7, decomposition=0, des='Exp', devices='0,1,2,3', distil=True, do_predict=False, dropout=0.2, e_layers=3, embed='timeF', embed_type=0, enc_in=21, factor=1, fc_dropout=0.2, features='M', freq='h', gpu=0, head_dropout=0.0, individual=0, is_training=1, itr=1, kernel_size=25, label_len=48, learning_rate=0.0001, loss='mse', lradj='type3', model='PatchTST', model_id='336_192', moving_avg=25, n_heads=16, num_workers=10, output_attention=False, padding_patch='end', patch_len=16, patience=20, pct_start=0.3, pred_len=192, random_seed=2021, revin=1, root_path='./dataset/', seq_len=336, stride=8, subtract_last=0, target='OT', test_flop=False, train_epochs=100, use_amp=False, use_gpu=True, use_multi_gpu=False)
Use GPU: cuda:0
>>>>>>>start training : 336_192_PatchTST_custom_ftM_sl336_ll48_pl192_dm128_nh16_el3_dl1_df256_fc1_ebtimeF_dtTrue_Exp_0>>>>>>>>>>>>>>>>>>>>>>>>>>
train 36360
val 5079
test 10348
iters: 100, epoch: 1 | loss: 0.7699601
speed: 0.2443s/iter; left time: 6914.9405s
iters: 200, epoch: 1 | loss: 0.7081208
speed: 0.2400s/iter; left time: 6769.4607s
Epoch: 1 cost time: 68.70572686195374
Epoch: 1, Steps: 284 | Train Loss: 0.7789939 Vali Loss: 0.5972105 Test Loss: 0.2579384
...................................................
...................................................
Epoch: 52, Steps: 284 | Train Loss: 0.4628612 Vali Loss: 0.4596826 Test Loss: 0.1950321
EarlyStopping counter: 14 out of 20
Updating learning rate to 5.726416897022355e-07
iters: 100, epoch: 53 | loss: 0.5660292
speed: 0.5665s/iter; left time: 7666.5226s
iters: 200, epoch: 53 | loss: 0.4055823
speed: 0.2401s/iter; left time: 3225.5280s
Epoch: 53 cost time: 68.69006490707397
Epoch: 53, Steps: 284 | Train Loss: 0.4628603 Vali Loss: 0.4589893 Test Loss: 0.1950957
EarlyStopping counter: 15 out of 20
Updating learning rate to 5.15377520732012e-07
iters: 100, epoch: 54 | loss: 0.4464000
speed: 0.5651s/iter; left time: 7487.2338s
iters: 200, epoch: 54 | loss: 0.4713202
speed: 0.2404s/iter; left time: 3160.9685s
Epoch: 54 cost time: 68.69320154190063
Epoch: 54, Steps: 284 | Train Loss: 0.4628062 Vali Loss: 0.4595098 Test Loss: 0.1950420
EarlyStopping counter: 16 out of 20
Updating learning rate to 4.6383976865881085e-07
iters: 100, epoch: 55 | loss: 0.5797229
speed: 0.5644s/iter; left time: 7316.9253s
iters: 200, epoch: 55 | loss: 0.4732520
speed: 0.2400s/iter; left time: 3087.9587s
Epoch: 55 cost time: 68.70202779769897
Epoch: 55, Steps: 284 | Train Loss: 0.4627469 Vali Loss: 0.4590654 Test Loss: 0.1950581
EarlyStopping counter: 17 out of 20
Updating learning rate to 4.174557917929298e-07
iters: 100, epoch: 56 | loss: 0.4195119
speed: 0.5662s/iter; left time: 7179.4083s
iters: 200, epoch: 56 | loss: 0.4406218
speed: 0.2401s/iter; left time: 3020.8005s
Epoch: 56 cost time: 68.69338417053223
Epoch: 56, Steps: 284 | Train Loss: 0.4628384 Vali Loss: 0.4601701 Test Loss: 0.1950181
EarlyStopping counter: 18 out of 20
Updating learning rate to 3.7571021261363677e-07
iters: 100, epoch: 57 | loss: 0.3315992
speed: 0.5642s/iter; left time: 6993.8902s
iters: 200, epoch: 57 | loss: 0.4004918
speed: 0.2402s/iter; left time: 2953.3031s
Epoch: 57 cost time: 68.68426299095154
Epoch: 57, Steps: 284 | Train Loss: 0.4627628 Vali Loss: 0.4581457 Test Loss: 0.1950388
EarlyStopping counter: 19 out of 20
Updating learning rate to 3.381391913522731e-07
iters: 100, epoch: 58 | loss: 0.3953090
speed: 0.5663s/iter; left time: 6859.4706s
iters: 200, epoch: 58 | loss: 0.4274355
speed: 0.2401s/iter; left time: 2884.2582s
Epoch: 58 cost time: 68.70291900634766
Epoch: 58, Steps: 284 | Train Loss: 0.4623488 Vali Loss: 0.4600674 Test Loss: 0.1950225
EarlyStopping counter: 20 out of 20
Early stopping
>>>>>>>testing : 336_192_PatchTST_custom_ftM_sl336_ll48_pl192_dm128_nh16_el3_dl1_df256_fc1_ebtimeF_dtTrue_Exp_0<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
test 10348
mse:0.1951362043619156, mae:0.2412061244249344, rse:0.5811452269554138模型测试结果下,分别是0轮、20轮、40轮、60轮的结果:

我们同时利用PatchTST/42获取关于电力系统数据集的多变量预报结果。
sh ./scripts/PatchTST/etth1.sh预测长度为96时
当预测长度pre_len参数为96时,训练日志如下:
Args in experiment:
Namespace(activation='gelu', affine=0, batch_size=128, c_out=7, checkpoints='./checkpoints/', d_ff=128, d_layers=1, d_model=16, data='ETTh1', data_path='ETTh1.csv', dec_in=7, decomposition=0, des='Exp', devices='0,1,2,3', distil=True, do_predict=False, dropout=0.3, e_layers=3, embed='timeF', embed_type=0, enc_in=7, factor=1, fc_dropout=0.3, features='M', freq='h', gpu=0, head_dropout=0.0, individual=0, is_training=1, itr=1, kernel_size=25, label_len=48, learning_rate=0.0001, loss='mse', lradj='type3', model='PatchTST', model_id='336_96', moving_avg=25, n_heads=4, num_workers=10, output_attention=False, padding_patch='end', patch_len=16, patience=100, pct_start=0.3, pred_len=96, random_seed=2021, revin=1, root_path='./dataset/', seq_len=336, stride=8, subtract_last=0, target='OT', test_flop=False, train_epochs=100, use_amp=False, use_gpu=True, use_multi_gpu=False)
Use GPU: cuda:0
>>>>>>>start training : 336_96_PatchTST_ETTh1_ftM_sl336_ll48_pl96_dm16_nh4_el3_dl1_df128_fc1_ebtimeF_dtTrue_Exp_0>>>>>>>>>>>>>>>>>>>>>>>>>>
train 8209
val 2785
test 2785
Epoch: 1 cost time: 2.025261878967285
Epoch: 1, Steps: 64 | Train Loss: 0.7408717 Vali Loss: 1.4723629 Test Loss: 0.8135457
Validation loss decreased (inf --> 1.472363). Saving model ...
Updating learning rate to 0.0001
Epoch: 2 cost time: 1.8104093074798584
Epoch: 2, Steps: 64 | Train Loss: 0.5737272 Vali Loss: 0.8931192 Test Loss: 0.4753346
Validation loss decreased (1.472363 --> 0.893119). Saving model ...
Updating learning rate to 0.0001
...................................................
...................................................
Updating learning rate to 5.5533286725436726e-09
Epoch: 97 cost time: 1.821709394454956
Epoch: 97, Steps: 64 | Train Loss: 0.3581489 Vali Loss: 0.6789832 Test Loss: 0.3749545
EarlyStopping counter: 47 out of 100
Updating learning rate to 4.997995805289306e-09
Epoch: 98 cost time: 1.7939820289611816
Epoch: 98, Steps: 64 | Train Loss: 0.3582450 Vali Loss: 0.6800703 Test Loss: 0.3748903
EarlyStopping counter: 48 out of 100
Updating learning rate to 4.498196224760375e-09
Epoch: 99 cost time: 1.8079988956451416
Epoch: 99, Steps: 64 | Train Loss: 0.3588102 Vali Loss: 0.6783884 Test Loss: 0.3749496
EarlyStopping counter: 49 out of 100
Updating learning rate to 4.048376602284338e-09
Epoch: 100 cost time: 1.803722858428955
Epoch: 100, Steps: 64 | Train Loss: 0.3586274 Vali Loss: 0.6786212 Test Loss: 0.3748749
EarlyStopping counter: 50 out of 100
Updating learning rate to 3.643538942055904e-09
>>>>>>>testing : 336_96_PatchTST_ETTh1_ftM_sl336_ll48_pl96_dm16_nh4_el3_dl1_df128_fc1_ebtimeF_dtTrue_Exp_0<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
test 2785
mse:0.37505924701690674, mae:0.39942532777786255, rse:0.5807181000709534此外我们还针对pre_len为192、336、720进行了训练,这里不再详述。
针对ETTH1数据集,分别针对pre_len为96、192、336、720测试结果如下:

[1] PatchTST官方实现
[2] 论文:A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
[3] https://github.com/cure-lab/LTSF-Linear
[4] https://github.com/zhouhaoyi/Informer2020
[5] https://github.com/thuml/Autoformer
[6] https://github.com/MAZiqing/FEDformer
[7] https://github.com/alipay/Pyraformer