- Python3
pip install -r requirements.txt
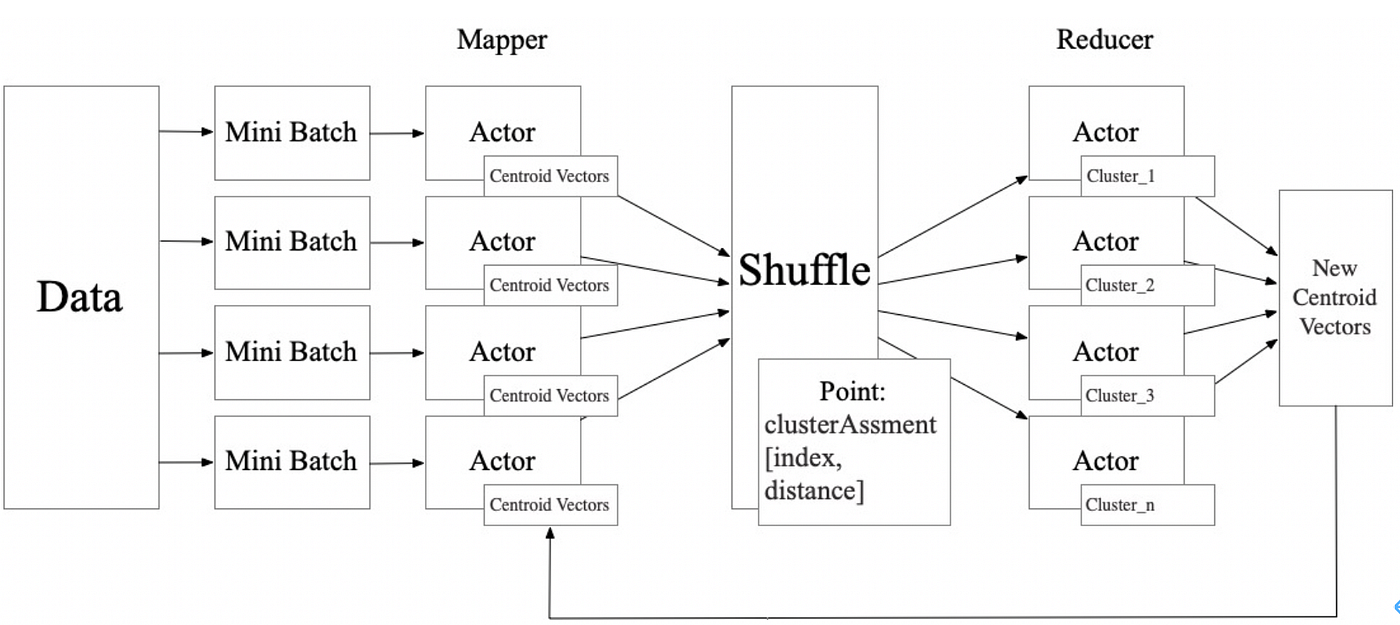
python3 main.py -d working-dir -f input-file -s number-of-sample -k number-of-clusters -n number-of-iteration -m number-of-mappers -t number-of-tasks
working-dir: working directory(also directory of check-in dataset)input-file: file name of datasetnumber-of-sample: number of samples you want to clusternumber-of-clusters: number of clustersnumber-of-iteration: max iteration for clusteringnumber-of-mappers: mappers in MapReducenumber-of-tasks: tasks in MapReduce
python3 main.py -d /Users/evan-mac/checkin -f loc-gowalla_totalCheckins.txt -s 50000 -k 20 -n 10 -m 5 -t 2
👤 Evan
Contributions, issues and feature requests are welcome! Feel free to check issues page.
Give a ⭐️ if this project helped you!
| PayPal | Patron |
|---|---|
 |
|
- Lloyd, Stuart P. (1957). "Least square quantization in PCM". IEEE Transactions on Information Theory, VOL. IT-28, NO. 2, March 1982, pp. 129–137.
- Arthur, D.; Vassilvitskii, S. (2007). "k-means++: the advantages of careful seeding". Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. Society for Industrial and Applied Mathematics Philadelphia, PA, USA. pp. 1027–1035.
- B. Bahmani, B. Moseley, A. Vattani, R. Kumar, S. Vassilvitskii "Scalable K-means++" 2012 Proceedings of the VLDB Endowment.
- Elkan, Charles (2003). "Using the triangle inequality to accelerate kmeans" (PDF). Proceedings of the Twentieth International Conference on Machine Learning (ICML).
- "MapReduce Tutorial". Apache Hadoop. Retrieved 3 July 2019.
- Marozzo, F.; Talia, D.; Trunfio, P. (2012). "P2P-MapReduce: Parallel data processing in dynamic Cloud environments" (PDF). Journal of Computer and System Sciences. 78 (5): 13821402.
- "Example: Count word occurrences". Google Research. Retrieved September 18, 2013.
- Berlińska, Joanna; Drozdowski, Maciej (2010-12-01). "Scheduling divisible MapReduce computations". Journal of Parallel and Distributed Computing. 71 (3): 450–459.
- Philipp Moritz et al. 2018. Ray: A Distributed Framework for Emerging AI Applications. In 13th USENIX Symposium on OSDI '18. 561-577.
- M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica. Spark: cluster computing with working sets. In Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, HotCloud'10, pages 10--10, Berkeley, CA, USA, 2010. USENIX Association.
- Ray Community
Copyright © 2020 Evan. This project is MIT licensed.