{kind=link}
In this project, I used using computer vision and AI to recognize the ASL alphabet and translate it into text, helping the deaf and hard-of-hearing community communicate more easily. This system now recognizes ASL gestures in real time, making communication smoother across various settings for ASL users.
I collected data for ASL hand gestures through a webcam, extracting hand landmarks and classifying gestures using machine learning. The model recognizes letters from "a" to "z," with specific adaptations for letters like "J" and "Z"—for "Z," I applied modifications to handle the required hand movement accurately. Additional gestures enable users to delete last character, clear all text in the textbox, and add spaces, creating a more comprehensive and user-friendly experience.
Sign Language Alphabet (a-z)

––––––––––––––––––––––––––––––––––––––––––––
Demo Video
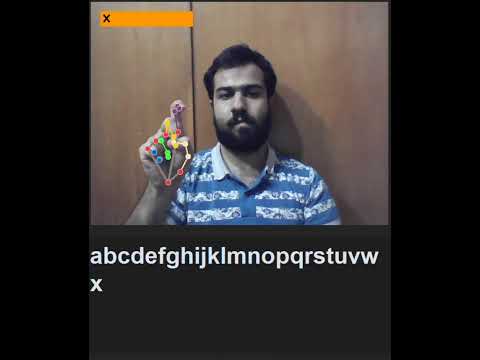
To get started, ensure the following dependencies are installed:
- Mediapipe:
0.10.14 - OpenCV (cv2):
4.10.0 - Scikit-learn:
1.5.2 - customtkinter: 5.2.1
Install them using pip:
pip install mediapipe==0.10.14 opencv-python==4.10.0.84 scikit-learn==1.5.2 customtkinter==5.2.1I utilized Mediapipe to detect hand landmarks for each ASL gesture. The x and y coordinates of these landmarks were extracted and then fed into the machine learning model, allowing for precise feature extraction and reliable, real-time predictions. This step ensures that each gesture is accurately represented, even with slight variations in hand positioning.
The desktop interface for this application was built using customtkinter, which provides a modern, user-friendly design. This package was used to create a dark-themed interface where users can view the webcam feed, see recognized letters in real time, and use special gestures for actions like deleting and clearing text. The interface also allows users to customize the speed of ASL-to-text conversion with a delay setting.
The dataset was self-collected with approximately 1000 images per ASL letter. Using the collect_images.py module, hand gestures were captured and labeled according to each letter. Since certain letters (e.g., "J" and "Z") require motion, static representations were chosen for these gestures to accommodate the model’s one-frame-at-a-time recognition limitation.
Using the create_dataset.py module, x and y coordinates of each hand landmark were extracted from the images and labeled for training. This structure helps achieve robustness against variations in hand positioning.
The project also includes custom gestures for:
- Backspace: Deletes the last word typed
- Clear All: Clears the entire text
- Space: Inserts a space between words
- Unknown Gesture: The model disregards any hand position not recognized as a valid ASL letter to minimize false predictions.
The model used in this project is a Random Forest Classifier, a robust and versatile algorithm that builds a collection (or "forest") of decision trees. This approach allows the classifier to make accurate predictions by combining results from multiple trees, thereby reducing the chances of overfitting and improving generalization. Below is a breakdown of how this model is applied to ASL gesture recognition:
-
Feature Extraction:
- The model operates on features extracted from hand landmarks. For each ASL gesture image, we use MediaPipe to identify the x and y coordinates of key hand landmarks.
- These landmarks are normalized, making the model invariant to hand positioning and distance from the camera. This normalization helps ensure that the features accurately represent the gesture, regardless of slight variations in positioning.
-
Data Preparation:
- Each gesture is represented by a unique pattern of landmark coordinates. After extracting these coordinates, we label each set with the corresponding ASL letter.
- Given ASL's requirement for high accuracy in gesture differentiation, we collected approximately 1000 images per letter to create a well-balanced dataset.
-
Model Training:
- Using the
train_classifier.pymodule, we fed the extracted landmark coordinates and their labels into a Random Forest Classifier. - The data is split into training and testing sets to validate the model’s performance. During training, each tree in the forest learns to distinguish between different gesture patterns by making "decisions" based on the landmark positions.
- The trained model achieved an accuracy of over 99%, indicating high reliability in recognizing static ASL gestures.
- Using the
-
Prediction in Real-Time:
- Once trained, the model is saved as a
.pfile, which is loaded by theapplication.pymodule during real-time prediction. - During operation, each frame captured from the webcam is processed to extract landmarks. These landmarks are fed into the model, which predicts the corresponding ASL letter.
- Special gestures (backspace, clear, space) and an "unknown" class (for gestures that don't match any ASL letter) are also handled by the model, allowing for smooth sentence construction and error management.
- Once trained, the model is saved as a
The realtime_detection.py module manages the live detection and display of ASL gestures. It captures video frames from the webcam, processes each frame to extract hand landmarks, and uses the trained model to predict the corresponding ASL character.
- Delay Adjustment with Counter:
- A delay is introduced to control the rate at which detected ASL gestures are converted to text. This delay is managed through a counter.
- You can adjust the counter value to modify the speed of ASL-to-text conversion. Setting a lower counter value will make the conversion faster, displaying letters more quickly. A higher counter value, on the other hand, slows the process down.
- The current speed setting allows users to display ASL characters (a-z) at a comfortable pace, enabling them to spell out names and sentences smoothly without rushing their gestures.
The module provides a smooth real-time experience by handling gestures with additional controls for special actions (backspace, clear, and space) and gracefully managing gestures that don’t match any ASL letter.
To run the ASL recognition system:
- Ensure your webcam is connected.
- Run the
application.pymodule, which initializes the webcam and predicts ASL gestures in real time. - Detected letters are displayed as text on the screen, allowing for live sentence construction.
The module also recognizes special gestures, letting users delete, clear, and add spaces to the typed text for smoother communication.
This project is licensed under the MIT License. You are free to use and adapt this code in your projects.