''The 2nd Shandong Province Data Application Innovation and Entrepreneurship Competition-Main Arena-Inspection Report Recognition''
The title only gives the data set for local testing, not the data used for training, and encourages the use of open data sets. Therefore, this repo uses open source models and parameters to reason and complete the task of the competition. I divided the question into two parts:
- Text recognition (position + content)
- Extraction of effective information (information filtering and combination)
- First use the public model and weights and models to detect the text position and text content recognition.
Here I provide the URLs of several public OCR tasks for reference:
- [EasyOCR] (https://github.com/JaidedAI/EasyOCR)
( Ready-to-use OCR with 80+ supported languages and all popular writing scripts including Latin, Chinese, Arabic, Devanagari, Cyrillic and etc.)
- [tensorflow] (https://github.com/xiaofengShi/CHINESE-OCR)
( Use tf to achieve natural scene text detection, keras/pytorch to achieve ctpn+crnn+ctc to achieve variable length scene text OCR recognition)
- [chineseocr] (https://github.com/chineseocr/chineseocr)
( This project is based on yolo3 and crnn to realize Chinese natural scene text detection and recognition)
- [PaddleOCR] (https://github.com/PaddlePaddle/PaddleOCR)
( Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
- [chineseocr_lite] (https://github.com/ouyanghuiyu/chineseocr_lite)
- [PytorchOCR] (https://github.com/WenmuZhou/PytorchOCR)
This repo uses PaddleOCR as the detection and recognition part
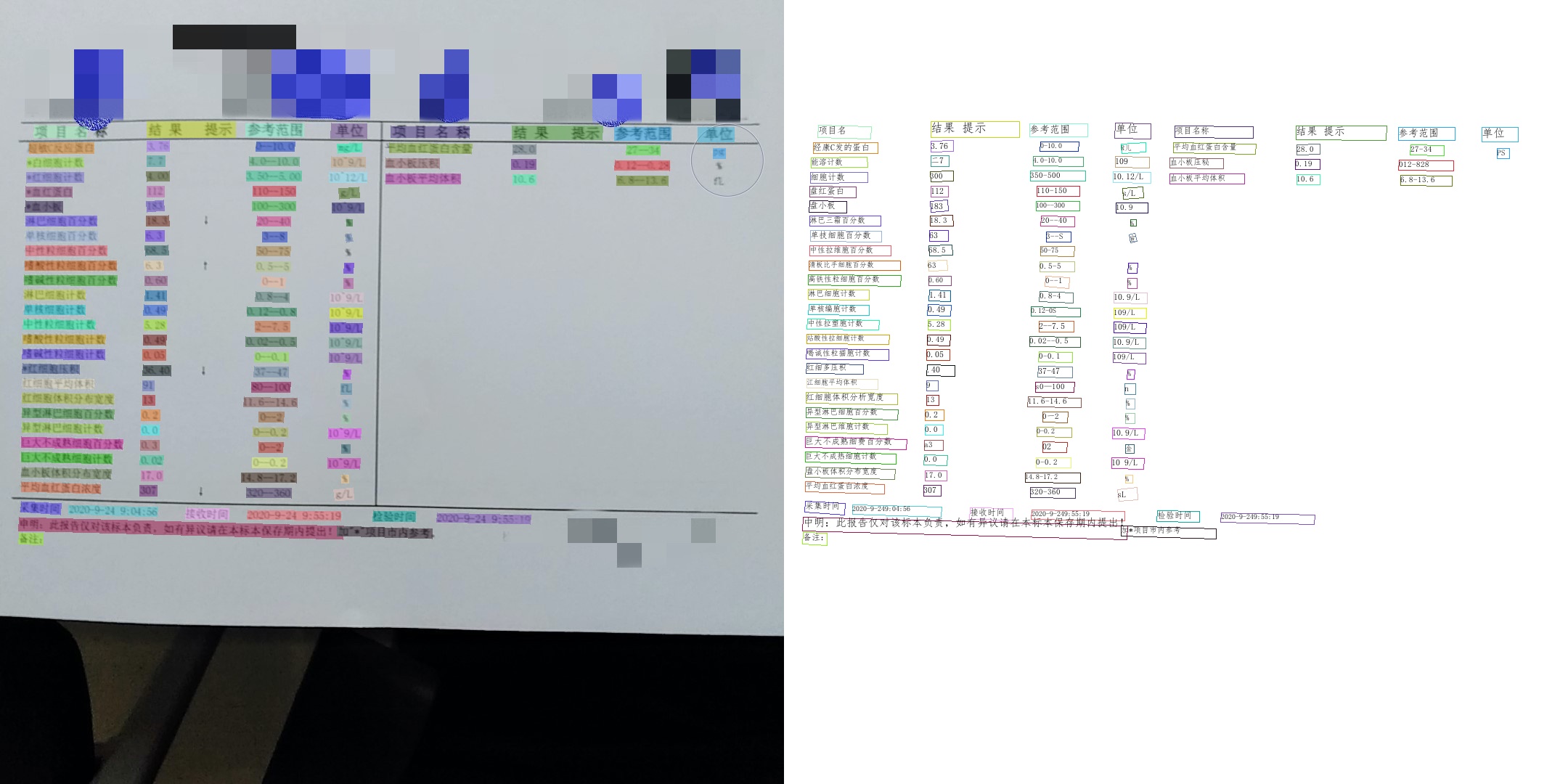
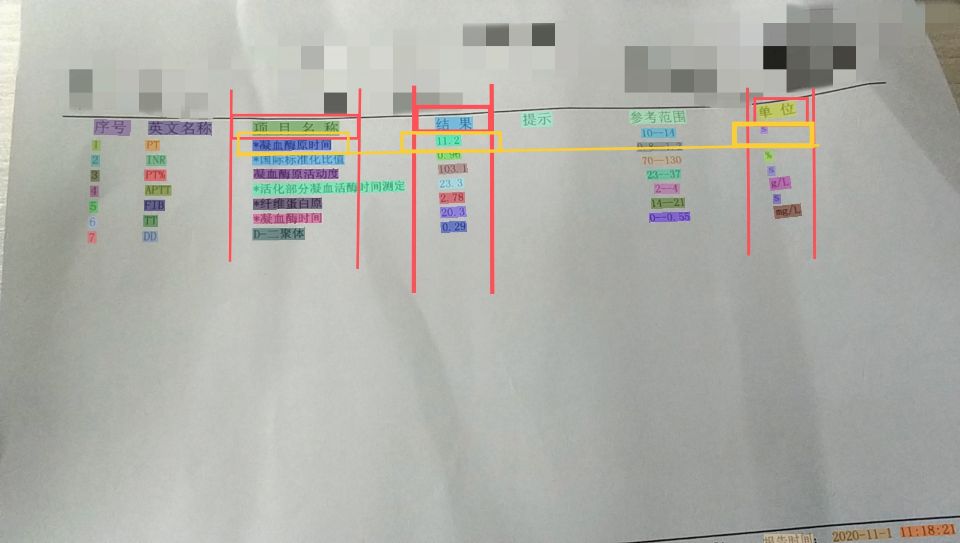
- Filtering and combining;Regarding the extraction of effective information, everyone can take a variety of different methods and play freely. Here I offer two simple ideas.
-
Find the dividing line, and then use the up and down translation method to extract effective information:

You can detection by open-cv:
cv2.Canny
-
Find the heading keyword directly first, and extract the information according to the coordinate position of the keyword.
-
This repo temporarily provides the second method as a baseline.
Configuration
-
Ubuntu 18.04 Cuda 10.1 cudnn 7.6.5+ Python 3.6.12
-
Clone this repo:
git clone https://github.com/Complicateddd/PaddlePL.git
-
Install library (GPU):
cd PaddlePL/ pip install -r requirements.txt
Not support gpu you can Install library (CPU):
cd PaddlePL/ pip install -r requirements_cpu.txt
-
Download Test Data
Then put it to path ''./data/img''
[ TestData] (http://data.sd.gov.cn/cmpt/competion/shandong.html)
-
Inference Demo: (GPU)
python run.py ./data/img/ submit.csv
(CPU version) set ./hyper_config.py self.use_gpu=False
./hyper_config.py --> self.use_gpu=False python run.py ./data/img/ submit.csv
-
Eval (ROUGE-L)
python rouge.py
| Image Number | ROUGE-L | |
|---|---|---|
| Offline | 100 | ~0.78 |
| Online | unknown | ~0.74 |

Note:
Here I just provide a simple process, more need you to explore , welcom to communicate with me ! If this repo 'PaddlePL' is helpful for you, star or fork will be my motivation.