Neural Networks
There are a whole bunch of different types of neural networks that are popularized for different reasons in deep learning. The basic equation for a neural network is as follows:

Here we deal with only two layers. The layer with nodes a serves as input for the layer with nodes o. We multiply the weights i of each input node a by a weight w and add a bias b. These are then summed and passed to an activation function f.
For hidden layers, this activation function is typically ReLU [R Hahnloser et. al, 2000, R Hahnloser & H.S. Seung, 2001] and for binary classification the output activation function is almost always sigmoid [Han, Jun; Morag, Claudio, 1995].
Weights are calculated by first initializing them randomly and then updating and tweaking them iteratively via backpropagation. This is done via minimizing a loss function with an optimizer.
The optimizers we will most often use are the Adam optimizer [Kingma et al., 2014] and RMSProp [Tieleman & Hinton, 2012].
The loss function we will almost always be using is cross-entropy, more specifically binary cross-entropy.
Here's a great chart showing the main types of neural networks.
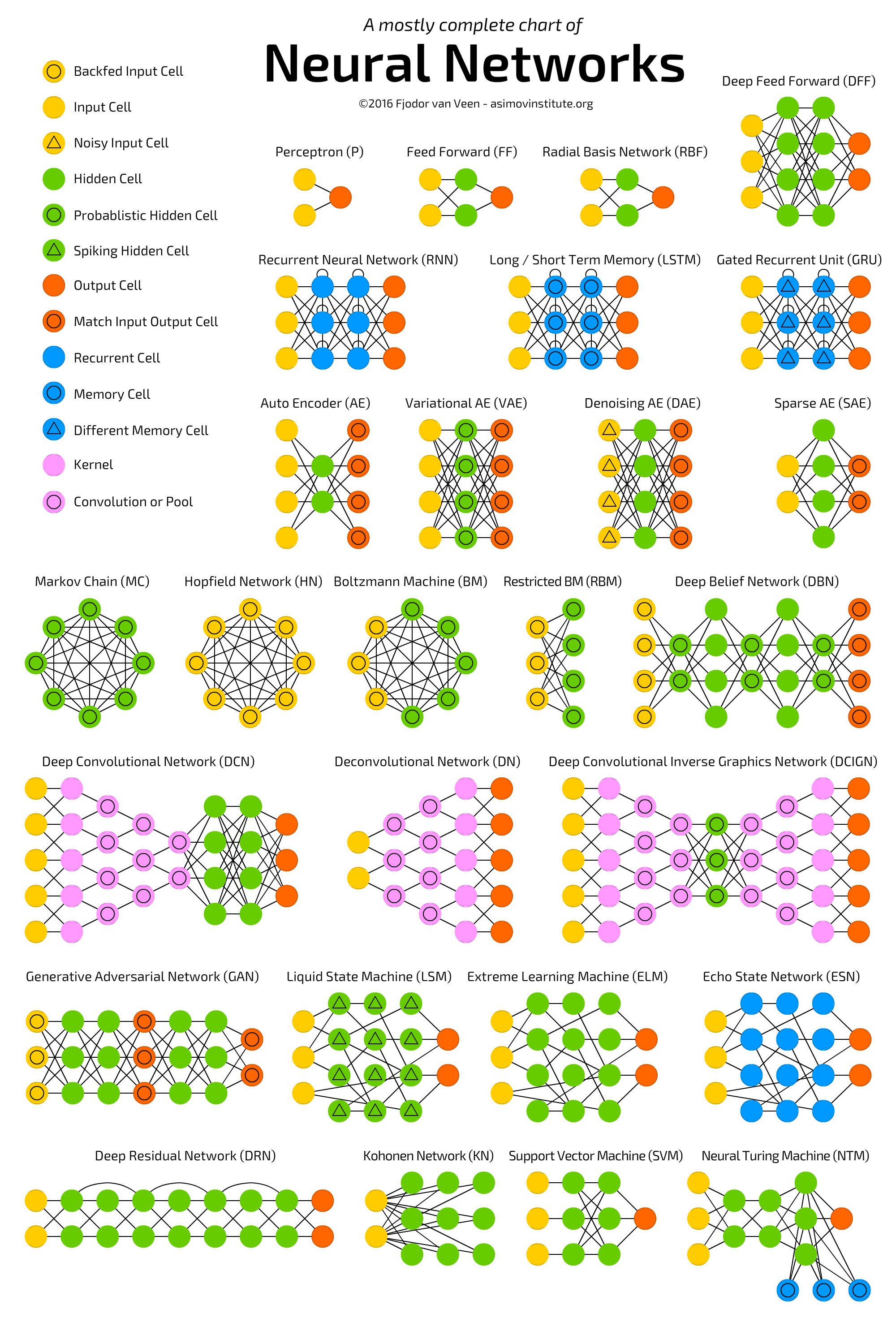
Here is a comprehensive explanation of the ones we are interested in:
The first type we will be setting up and experimenting with is the fully connected FF network. This is simply a perceptron with some more layers, and is usually trained using backpropagation. It is called fully-connected because every node is connected to every other node and feedforward because data only flows from the input layer to the output, with no loops. There is a form called the RBF which instead of the logistic (sigmoid) function to generate a result (between 0 and 1), uses the radial basis function to figure out how far we are from our target. More than one connected hidden layer turns this into a Deep Feed-Forward network (DFF).
The next type we will be trying are Recurrent Neural Networks. These are used when context is important, which is definitely the case for us. These differ from the previous type by the addition of 'recurrent' cells, where a cell receives it's output with a delay. A type we will look at is known as the Long short-term memory network (LSTM), which adds in a 'memory' cell, comprised of gates (input, output and forget gates) which have their own weights and activation functions. They can decide what data is kept, forgotten, and passed on at every step. Another one we can look at are Gated Recurrent Units (GRU's), which are extremely similar to LSTM networks but with different types of gating.
Another type of network very popular these days, convolutional neural networks (CNNs) use a mixture of convolutional cells (pooling layers, which simplify data) and kernels (which process input data). They operate as a sliding window, taking small subsets of the data and passing them to convolutional layers, which act as a funnel that compress the features. A deconvolutional network (DN) is the opposite.
The focus of our hypothesis, Generative Adversarial Networks (GANs), is a name given to a huge family of double-networks that are composed of a generator and discriminator network. They try to fool each other in a zero-sum game. The generator attempts to produce data and the discriminator, being fed sample data, tries to tell generated from sample.
Overfitting occurs when a statistical model or machine learning algorithm captures the noise of the data. Intuitively, overfitting occurs when the model or the algorithm fits the data too well. Specifically, overfitting occurs if the model or algorithm shows low bias but high variance. The high variance means the model is modelling the random noise. Overfitting is often a result of an excessively complicated model, and it can be prevented by fitting multiple models and using validation or cross-validation to compare their predictive accuracies on test data.
Underfitting occurs when a statistical model or machine learning algorithm cannot capture the underlying trend of the data. Intuitively, underfitting occurs when the model or the algorithm does not fit the data well enough. Specifically, underfitting occurs if the model or algorithm shows low variance but high bias. High bias means the model is missing relevant relationships between features and outputs. Underfitting is often a result of an excessively simple model.