Generative Adversarial Networks
This article will attempt to give a reader who knows next to nothing about the mystical and ever-elusive Generative Adversarial Networks a low-down on the intricacies and inner-workings of this strange beast. Some preequisite knowledge on LSTM, RNN and CNN's will come in useful going forward, as well as a general knowledge of neural network architectures and data formatting.
The first important thing to note about GAN's is that they are never a standalone, singular network. GAN's are a large family of ensemble dual-networks comprised of one or more generators and one or more discriminators. The generators task is generally to trick a discriminator network into thinking that the data it generates is real, and the discriminator's task is to determine generated from real.
Although the component networks of GAN's can be any form of neural network architecture, usually the generator will be an RNN, and the discriminator a CNN. Because the generator attempts to learn the underlying structure of the data without a target value, this type of learning is said to be unsupervised.
Most (almost all) GAN's are used for image or video data. This is because image data is continuous when converted to integers (a slight change can be made to pixel RGB values and they can be tweaked), however text data is discrete (if the word 'kangaroo' corresponds to index 119 in a word vocabulary, tweaking it even by 1 may result in the word 'skyscraper'.)
(Side note: Word embeddings may be a way around this, where cosine similarity between word vectors can be measured and then tweaked to look for similar words.)
Ian Goodfellow, a researcher for Google AI and the creator of the GAN, said two years ago in a Reddit thread that GAN's are unsuited to the task of text classification. However, he did note that REINFORCE could be used, although noone had tried it yet.
The generator will start off with a static noise set generated from the input data. (If for example, the input data is black or white pixelled 24x24 sized images of digits, the static noise set will be black or white pixels randomly distributed in a 24x24 sized image.) It will take a sample of the noise set and a sample of the real training set, where the target of the noise is 0 and the target of the real data is 1, and pass them to the discriminator, which makes it's best guess at real or generated. We then calculate the loss for each target and pass back the gradient loss back to the generator.
The generator will use this gradient to adjust its weights to maximize the discriminator's loss (probability that it guesses a generated as real). At the same time, the discriminator's weights are adjusted to maximize the generators loss, so it can always discriminate between real and generated, and to minimize its own loss.
In this fashion, the two networks are trying to optimize opposite loss functions and can be thought of as two agents playing a minimax game.
It will continue to do this until convergence, ie. the generator produces data indistinguishable from the real data.
In the formal sense the objective function of this whole process can be written as:
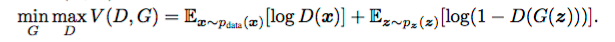
The usual desirable equilibrium point for the above defined GANs is that the Generator should model the real data and Discriminator should output the probability of 0.5 as the generated data is same as the real data -- that is, it is not sure if the new data coming from the generator is real or fake with equal probability.
The intuition behind this and all generative approaches follows a famous quote from Richard Feynman:
What I cannot create, I do not understand.
Once the generator hits this point, it can be thought of as 'understanding' the real data distribution.
Our GAN, for the time being, will be exactly like the one in the FakeGAN paper, until we can replicate the results and discover any low hanging fruit that can be immediately improved, such as a better policy gradient agent, better CNN architecture, better LSTM architecture, etc.
FakeGAN's main components are as follows:
The generator is an RNN. It maps input embeddings s of input tokens S onto hidden states h using the following recursive function.
(image)
Finally, a softmax output layer z with bias vector c and weight matrix V maps the hidden layer neurons into the output token distribution as:
(image)
To deal with the common vanishing and exploding gradient problem of backpropagation through time, LSTM cells are used.
CNN's are used for discriminators due to their effectiveness in text classification tasks.
The sequence matrix is constructed by concatenating the embeddings of sequences S1...SL as:
(image)
Then a kernel w computes a convolutional operation to a window size of l by using a non-linear function π, which results in the feature map:
(image)
Where ⊗ is the inner product of two vectors, and b is a bias term. Kernels that have been successfully used by the community for text classification tasks are used and hyper-tuned. A Max-Over-Time pooling operation is run over the feature maps to allow different kernel outputs to be combined. The highway architecture is used to improve performance. A fully connected layer with sigmoid activation functions is finally used to classify the input sequence.