Implementing YOLOV3 on google colab using PyTorch
YOLOv3 is the third object detection algorithm in YOLO (You Only Look Once) family. It improved the accuracy with many tricks and is more capable of detecting small objects.

The improvements of YOLO V3:
-
Bounding Box Predictions : YOLOv3 just like YOLOv2 uses dimension clusters to generate Anchor Boxes. Now as YOLOv3 is a single network the loss for objectiveness and classification needs to be calculated separately but from the same network. YOLOv3 predicts the objectiveness score using logistic regression where 1 means complete overlap of bounding box prior over the ground truth object. It will predict only 1 bonding box prior for one ground truth object( unlike Faster RCNN) and any error in this would incur for both classification as well as detection (objectiveness) loss. There would also be other bounding box priors which would have objectiveness score more than the threshold but less than the best one, for these error will only incur for the detection loss and not for the classification loss.
-
Class Predictions : YOLOv3 uses independent logistic classifiers for each class instead of a regular softmax layer. This is done to make the classification multi-label classification. What it means and how it adds value? Take an example, where a woman is shown in the picture and the model is trained on both person and woman, having a softmax here will lead to the class probabilities been divided between these 2 classes with say 0.4 and 0.45 probabilities. But independent classifiers solves this issue and gives a yes vs no probability for each class, like what’s the probability that there is a woman in the picture would give 0.8 and what’s the probability that there is a person in the picture would give 0.9 and we can label the object as both person and woman.
-
Predictions across scales : To support detection an varying scales YOLOv3 predicts boxes at 3 different scales.
-
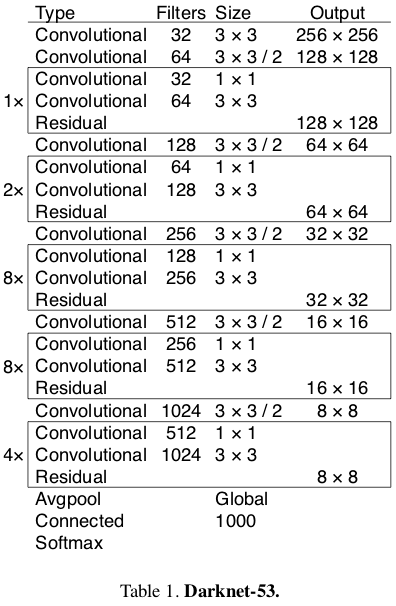
Feature Extractor : YOLOv2 used Darknet-19 as its backbone feature extractor, YOLOv3 uses a new network- Darknet-53! Darknet-53 has 53 convolutional layers, its deeper than YOLOv2 and it also has residuals or shortcut connections. Its powerful than Darknet -19 and more efficient than ResNet-101 or ResNet-152.
- Don't forgrt to change the Runtime type to GPU, it will save you some time. To do so you need to go to the head of the screen press on "Runtime" ---> "Change Runtime Type" ---> "Hardware" and select GPU option.
- Don't forget to set the parameters in the "Setting parameters" section before you run the code.
detect_imageis flag, whendetect_image = Truethe model will detect on image inputdetect_image = Falsethe model will detect on video input. - Test images automatically been dowloaded. If you want to use other images you can paste download URL in "Get test images" section or just upload manually to
'/content/Images'directory.
- Write train file to able traning on other dataset than Microsoft's COCO.
- I have modified the detection script so now you can save the detected video!
- You don't have to load anything but the image/video you want to apply the detection on.