PDF Manuscripts
PDF Upload support landed through the tickets in the epic for PDF and \latex support. The benefit is that authors using \latex can submit their manuscript looking just the way they want for the initial phase.
To achieve this support, we employ PDF.JS (Section PDF.JS and
pdf.js-viewer) to render the document on the client. There are also
feature flags and interactions with Attachments workflow that changed
for this addition.
The following sections touch on the high-level points of using PDFs in Aperta. The discussion of the back-end models and settings will set the stage illustrating how to upload a PDF manuscript. The front end will focus on display and some screenshots of the specific user interactions when the journal enables PDF uploads.
Starting at the top of Figure pdfmanuscripterd ,
Journal appears first. Each Journal has it's own setting enabling a
PDF upload. Listing journalschema shows an abbreviated
schema for Journal with the pdf_allowed boolean. Any given journal
also can hold custom css for pdf display. The default is to not allow
a PDF submission. New journals will need to set this appropriately.
create_table "journals", force: :cascade do |t|
# <snip>
t.text "pdf_css"
# <snip>
t.boolean "pdf_allowed", default: false
endMoving to the next model in Figure pdfmanuscripterd ,
we arrive at Paper. It is the parent, or owner, of any attachments. A
manuscript is such an attachment being of the type
ManuscriptAttachment. Paper comes into play by updating the body
text correctly when an author uploads a new manuscript. In the case of
PDF, this blanks out the body for versioning.
Finally, there is Attachment. This class is the parent of the
sub-classes ManuscriptAttachment and SourcefileAttachment. The first
is where any type (.doc, .docx, .pdf) of manuscript lives.
ManuscriptAttachment uses
CarrierWave for
storage to S3. There is nothing unique about this class for PDFs as the
manuscripts themselves are just files. It does store type in the
.file attribute.
If the staff accept a manuscript for publication, they will require the
source document of the PDF. This is where SourcefileAttachment comes
into play. Aperta's current behavior requires any submission 1.0 and
beyond to have an associated source file for export.
One final class caring about a PDF manuscript is ExportPackager. The
source file requirements exists just for export. The packager adds all
of the files (PDF and source) to the exported zip file.
Aperta has pieces in place to convert documents into PDFs. The
PaperConverters module handles these transformations. Table
conversions shows the main transformations available.
| Source Type | Output Requested | Converter |
|---|---|---|
IdentityPaperConverter |
||
| docx/doc | docx/doc | IdentityPaperConverter |
| docx/doc | docx/doc (sourcefile) | SourcePaperConverter |
| docx/doc | pdf (with attachments) | PdfPaperConverter |
| pdf with attachments | PdfWithAttachmentsPaperConverter |
|
| docx/doc | pdf for export (router) | AutoGeneratedDocxToPdfConverter |
| pdf for export (router) | AutoGeneratedDocxToPdfConverter |
The first three entries make sure that we can generate the right URL for to directly link to the files requested. The only complexitiy is for a docx listed as a source file. It has a separate converter.
In the second group, the generated PDFs have any attachments appended into the PDF. This is true for Microsoft Word sources or PDF sources.
Finally, the last section converts the source materials into a PDF for the router. This is the export PDF which gets packaged up for Apex.
This is a manual step taken on by a developer. There is no setting on the administration section of Aperta to turn this on, so someone must use the console. The following command in Listing pdfallowed will make the necessary journal setting.
Journal.find(id).update(pdf_allowed: true)Allowing PDF uploads changes the client-side interactions. The following sections discuss these additions to the submission workflow.
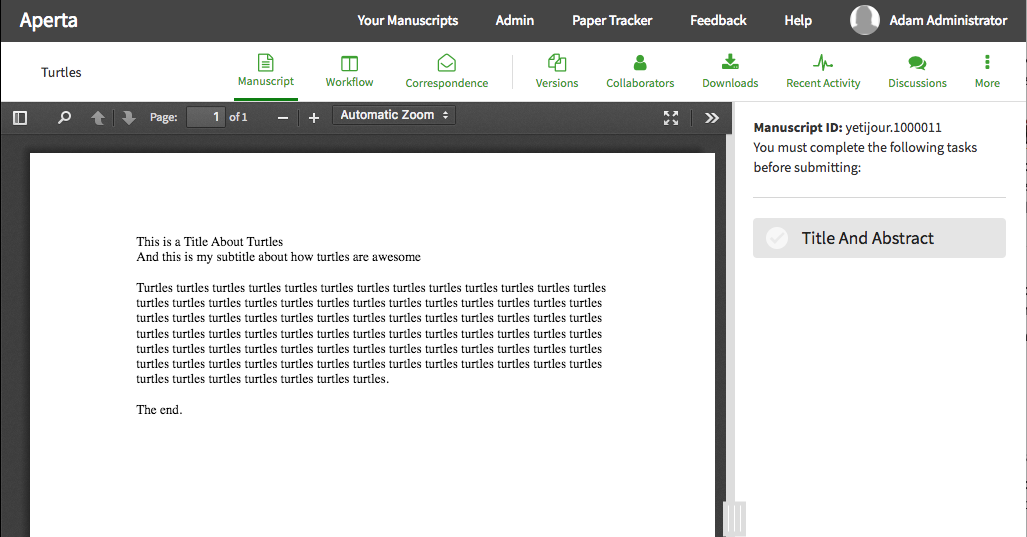
For the client side, Aperta shows an HTML representation of the body if
the uploaded manuscript is a docx file. For a PDF, Aperta makes use of
the PDF.JS library from the good
people at Mozilla.
However, the main drawback of this library is that it lacks an embeddable viewer. It ships with an example of a full-page implementation that looks exactly like the PDF viewer in Firefox. They ask that if you use this then your version should not look the same as the reference.
This is where
pdf.js-viewer comes into
play. It is an implementation of an embeddable PDF viewer based on
PDF.JS. However, customization is always a snag. This library modifies
the PDF.JS reference to get the job done. For Aperta, the
pdf.js-viewer needed editing to meet the system needs.
This means we have the following installation, implementation and upgrade path:
- Get latest
PDF.JS - Appy
pdf.js-viewerpatches- Fix any broken patches
- Apply Aperta patches
- Fix any broken patches
- Update build script
The path vendor/assets/pdfjs-viewer/ contains all of the files related
to these assets. There is a README.md explaining the steps and an
update.sh script automating the upgrade steps. Although these helpers
exist, the upgrade is still intensly manual.
The first reason that Aperta hosts it's own version of these files is due to customization. The other is that the library is only included on pages that need PDF support. In this way, the system minimizes the extra libraries for the client.
For submissions to journals with PDF upload enabled, an author sees the intial prompt in Figure uploadpdf . The text under the button changes to only list the Microsoft Word formats if PDF upload is disabled.

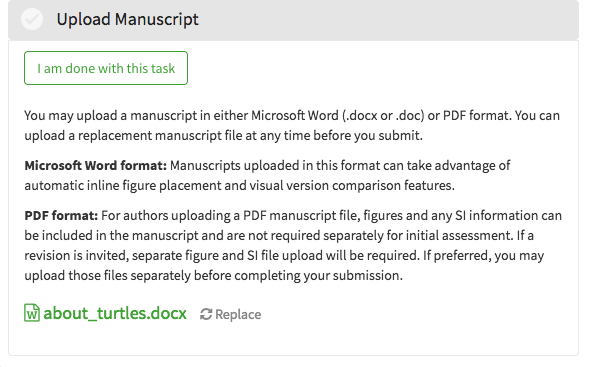
After the inital upload, every subsequent submission requires the author to complete the Upload Manuscript task. Figure upload shows the task for PDF submissions. There is the normal file uploaded for the manuscript and then a secondary one for the source file.

Contrast Figure upload with Figure uploaddocx . In the latter, there is no extra uploader for a source file. We can tell PDFs are permissable by the upload instructions. If the authors swaps out the manuscript for a PDF version, the task will again ask for the source.
The source files can be .docx, .doc or .zip. The zip files are
intended to package up all of the assets for a \LaTeX submission.
The attached source file is enforced by task validation. If an author tries to finish the task without uploading all relevant files it will show some errors for the user to fix. Figure uploadfail has an example of these failures.

When using PDFs, Aperta does not provide the ability to see differences in the body between versions. Figure pdfdiff illustrates the warning displayed for the user.

The meta-data associated with a manuscript will still show any changes in the right pane. Notice too that the files in Figure pdfdiff indicate that they are PDFs.
For the manuscript downloads, PDF files are generated from submitted
.docx files. However, when a user submits a PDF, the uploaded PDF can
be provided directly. This is what happens in the Downloads section
of the interface in Figure downloads .

Each submission in Figure downloads has a PDF version. It's easy to see that the 0.0 version had only a PDF since no Word format is listed.
In journals without PDF support, a user would still see the PDF links, but those versions would be generated from the Word files and not the original author submissions.
I know that you thought that the PDF support was perfect, but... Surprise! There are areas to improve. Two main suggestions are to provide some level of manuscript diffing and maybe craft Aperta's own viewer.
Showing manuscript body differences is not possible when the source is PDF. Aperta lacks the ability to show changes between two different PDF submissions. If this becomes a need for reviewers and staff, then APERTA-6472 and APERTA-7296 may provide a starting point.
The initial integration of pdfjs-viewer successfully displays PDFs,
but has proven to be difficult to maintain going forward.
APERTA-11040 outlines
using PDF.JS to create an Aperta-specific PDF viewer.
Implementing this will be non-trivial, but provide the ability to more
closely track PDF.JS releases and customize the display look, feel,
and function.
It may also be possible to build this with the base PDF.JS in such a
way as to pull down a CDN version of that library. This avoids hosting
it with Aperta and may be kinder to those far away from the servers
(provided they have a CDN nearby).
No browsers were harmed in the collection of screenshots. All computes generating the diagrams are not certified organic. Do not iron printed materials. The following sections explain all diagramming tools and techniques used in this document.
Listing papererd shows the code to generate the ERD diagram. Note that this requires the installation of the rails-erd gem.
rake erd only="Journal,Paper,Attachment,ManuscriptAttachment,SourcefileAttachment" filename="pdfmanuscripterd" filetype="pdf" title=false inheritance=true attributes=false- Library Links
- Jira Links
- https://jira.plos.org/jira/browse/APERTA-11040 (Aperta pdfjs viewer)
- https://jira.plos.org/jira/browse/APERTA-6472 (Diff PDF)
- https://jira.plos.org/jira/browse/APERTA-7296 (\Tex to HTML)
pdfmanuscripterd.pdf (application/pdf)
pdfviewer.png (image/png)
uploadpdf.png (image/png)
upload.png (image/png)
uploaddocx.png (image/png)
uploadfail.png (image/png)
downloads.png (image/png)
pdfdiff.png (image/png)