
2023-05-03: We have launched the ongoing version of this challenge. You can start submitting your test results at this new link. If you have not applied for the dataset yet, you need to send an application email to both of [email protected] and [email protected].
2023-02-15: The annotation format in readme is fixed:
- e.g: Train/spoof/2D-Display-Phone/000001/000001.txt
192 148 (bbox left top)
234 203 (bbox right bottom)
216 171 (landmark left eye)
230 168 (landmark right eye)
231 180 (landmark nose)
218 190 (landmark left mouth )
229 188 (landmark right mouth )
We host the WILD track of Face Anti-spoofing Workshop and Challenge@CVPR2023 here. The challenge will officially start together with 4th Face Anti-spoofing Workshop.
Registration is now open on codalab.
Our competition encompasses over 800K spoof photos and over 500K live photos. In the spoof photos, there are three major categories and 17 subcategories.
-
Any extra data or pretrained model trained from extra data cannot be used in this challenge.
-
Only one DL model can be used, we can not accept the fusion results from many DL models. The computational cost of a single DL model should be less than 5G FLOPs. (FLOPs can be calculated using
ptflopspython library) -
The top-3 winners are required to submit the code for the entire method, ensuring reproducibility of the results and compliance with all contest rules, otherwise the score will be disqualified.
| Phase | Start Date | End Date | Intro |
|---|---|---|---|
| Dev | 2023-02-13 | 2023-03-15 | evaluate the accuracy on dev set |
| Test | 2023-03-15 | 2023-03-28 23:59:59 | evaluate the accuracy on test set, using the threshold from dev set |
| Rank | Prize |
|---|---|
| 1st place | $ 3,000 |
| 2nd place | $ 1,500 |
| 3rd place | $ 500 |
Sponsors: Moredian Technology
For the performance evaluation, we selected the recently standardized ISO/IEC 30107-3 metrics: Attack Presentation Classification Error Rate (APCER), Normal/Bona Fide Presentation Classification Error Rate (NPCER/BPCER) and Average Classification Error Rate (ACER) as the evaluation metric, in which APCER and BPCER/NPCER are used to measure the error rate of fake or live samples, respectively. The ACER value is used as the final evaluation criterion.
Phase1: training dataset is used to train the model (Label: live=1, fake=0). Then the trained model is used to predict the sample scores in dev.txt. Participants can directly submit the predicted score file in codalab system. Note that the order of the samples in dev.txt cannot be changed. The final submitted file contains a total of 140,058 lines. Each line in the file contains two parts separated by a space. The first part is the path of each image in dev.txt and must contain the set name(dev/), and the second part is the prediction score given by the model (representing the probability that the sample belongs to the live face, which must be in the range of [0.0, 1.0]). Such as:
dev/000001.jpg 0.15361 #Note: line 1- the first row of dev.txt
......
dev/140058.jpg 0.23394 #Note: line 140,058 the last row of dev.txt
The predicted file should be a .txt file and compressed into a ZIP file (do not add any folder in the ZIP).
Phase2: In order to submit results at one time, participants need to combine the dev and test predictions into one file before result submission via codalab system. Note that the order of the samples cannot be changed and the dev sample list needs to be written before the test samples.
The final submission file contains a total of 895,237 lines. Each line in the file contains two parts separated by a space. Such as:
dev/000001.jpg 0.15361 #Note: line 1- the first row of dev.txt
......
dev/140058.jpg 0.23394 #Note: line 140,058 the last row of dev.txt
test/000001.jpg 0.15361 #Note: line 140,059 the first row of test.txt
......
test/755179.jpg 0.23394 #Note: line 895,237 the last row of test.txt
The predicted file should be a .txt file and compressed into a ZIP file (do not add any folder in the ZIP).
- The dataset and its subsets can only be used for academic research purposes.
- The user is not allowed to use the dataset or its subsets for any type of commercial purpose.
- Any form of usage of the dataset in defamatory, pornographic, or any other unlawful manner, or violation of any applicable regulations or laws is forbidden. We are not responsible for any consequences caused by the above behaviors.
- The User is not allowed to distribute, broadcast, or reproduce the dataset or its subsets in any way without official permission.
- The user is not allowed to share, transfer, sell or resell the dataset or its subsets to any third party for any purpose. HOWEVER, providing the dataset access to user’s research associates, colleagues or team member is allowed if user’s research associates, colleagues or team member agree to be bound by these usage rules.
- All images in this dataset can be used for academic research purposes, BUT, only the approved images of the dataset can be exhibited on user’s publications(including but not limited to research paper, presentations for conferences or educational purposes). The approved images have special marks and are listed in a appendix.
- We reserve the right to interpret and amend these rules.
- please cite us if the InsightFace Wild Anti-Spoofing Dataset or its subset is used in your research:
@misc{wang2023wild,
title={Wild Face Anti-Spoofing Challenge 2023: Benchmark and Results},
author={Dong Wang and Jia Guo and Qiqi Shao and Haochi He and Zhian Chen and Chuanbao Xiao and Ajian Liu and Sergio Escalera and Hugo Jair Escalante and Lei Zhen and Jun Wan and Jiankang Deng},
year={2023},
eprint={2304.05753},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
All users can obtain and use this dataset and its subsets only after signing the Agreement and sending it to the official e-mail insightface.challenge#gmail.com.
Please refer to the following table for detailed information on the number of labeled data and examples in the dataset:
Training Subset, live/spoof labels and categorization information are given:

Dev and Test Subsets, where dev set is used to select the threshold.
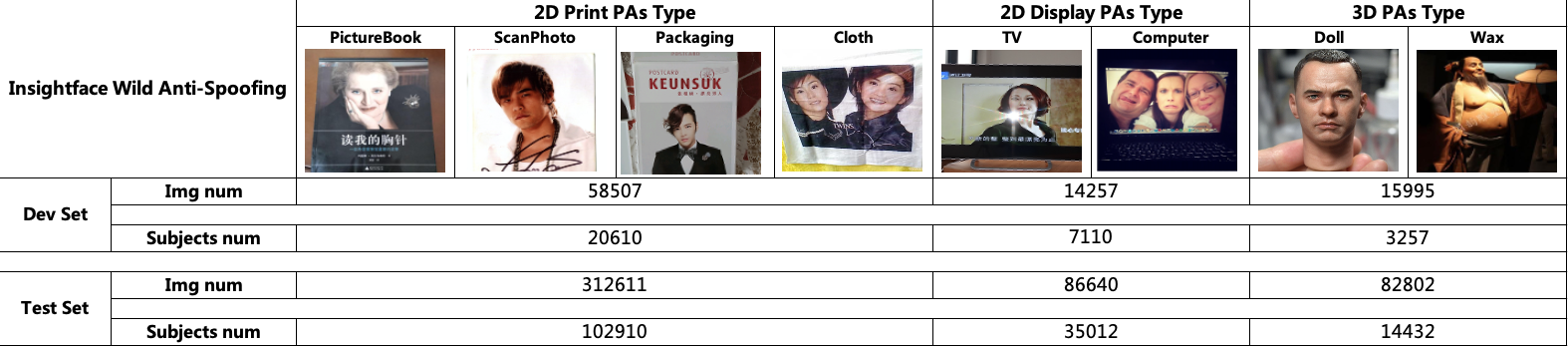
There're 205,146 live images in training set, and 51,299/273,126 images in dev and test sets respectively.
| Backbone | Input Crop | FLOPs | APCER | BPCER | ACER |
|---|---|---|---|---|---|
| ResNet18 | 224x224 | 1.8G | 4.244% | 4.245% | 4.245% |
| Backbone | Input Crop | FLOPs | APCER | BPCER | ACER |
|---|---|---|---|---|---|
| ResNet18 | 224x224 | 1.8G | 6.145% | 8.874% | 7.509% |
- If you have any questions regarding the challenge, kindly open an issue on insightface github. (recommended)
- Or you can send an e-mail to
insightface.challenge#gmail.com