find the previous version of this document at crankshaft/gc.md
Table of Contents generated with DocToc
- Goals, Techniques
- Cost of Allocating Memory
- How objects are determined to be dead
- Two Generations
- Heap Organization in Detail
- Young Generation
- Orinoco Garbage Collector
- Old Generation Garbage Collector Deep Dive
- Resources
- ensures fast object allocation, short garbage collection pauses and no memory fragmentation
- stop-the-world, generational precise garbage collector
- stops program execution when performing steps of young generation garbage collections cycle that can only run synchronously
- many steps are performed in parallel, see Orinoco Garbage Collector and only part of the object heap is processed in most garbage collection cycles to minimize impact on main thread execution
- mark compact is performed incrementally and therefore not stop-the-world
- wraps objects in
Handles in order to track objects in memory even if they get moved (i.e. due to being promoted) - identifies dead sections of memory
- GC can quickly scan tagged words
- follows pointers and ignores Smis and data only types like strings
- cheap to allocate memory
- expensive to collect when memory pool is exhausted
an object is live if it is reachable through some chain of pointers from an object which is live by definition, everything else is garbage
- considered dead when object is unreachable from a root node
- i.e. not referenced by a root node or another live object
- global objects are roots (always accessible)
- objects pointed to by local variables are roots (stack is scanned for roots)
- DOM element's liveliness is determined via cross-component tracing by tracing from JavaScript to the C++ implementation of the DOM and back
- object heap segmented into two parts, Young Generation and Old Generation
- Young Generation consists of New Space in which new objects are allocated
- Old Generation is divided into multiple parts like Old Space, Map Space, Large Object Space
- Old Space stores objects that survived enough GC cycles to be promoted to the Old Generation
- for more details see below
- two garbage collectors are implemented, each focusing on young and old generation respectively
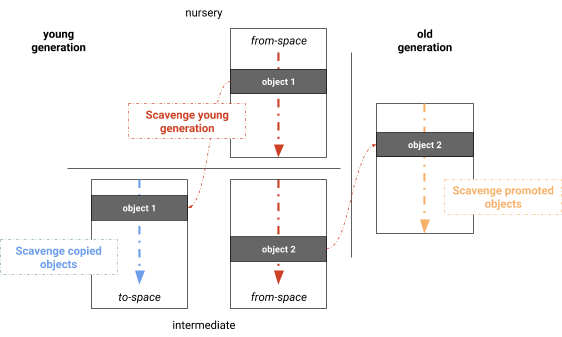
- young generation evacuation (more details)
- objects initially allocated in nursery of the young generation
- objects surviving one GC are copied into intermediate space of the young generation
- objects surviving two GCs are moved into old generation
young generation | old generation
|
nursery | intermediate |
| |
+--------+ | +--------+ | +--------+
| object |---GC--->| object |---GC--->| object |
+--------+ | +--------+ | +--------+
| |
- most objects allocated here
- executable
Codesare always allocated in Old Space
- executable
- fast allocation
- simply increase allocation pointer to reserve space for new object
- fast garbage collection
- independent of other spaces
- between 1 and 8 MB
- immortal, immovable and immutable objects
- objects surviving New Space long enough are moved here
- may contain pointers to New Space
- promoted large objects (exceeding size limits of other spaces)
- each object gets its own
mmapd region of memory - these objects are never moved by GC
- contains executable code and therefore is marked executable
- no pointers to New Space
- contains map objects only
- each space divided into set of pages
- page is contiguous chunk of memory allocated via
mmap - page is 512KB in size and 512KB aligned
- exception Large Object Space where page can be larger
- page size will most likely decrease in the future
- page contains header
- flags and meta-data
- marking bitmap to indicate which objects are alive
- page has slots buffer
- allocated in separate memory
- forms list of objects which may point to objects stored on the page aka remembered set
most performance problems related to young generation collections
- fast allocation
- fast collection performed frequently via stop and copy - two-space collector
- however some copy operations can run in parallel due to techniques like page isolation, see Orinoco Garbage Collector
- ToSpace is used to allocate values i.e.
new - FromSpace is used by GC when collection is triggered
- ToSpace and FromSpace have exact same size
- large space overhead (need ToSpace and FromSpace) and therefore only suitable for small New Space
- when New Space allocation pointer reaches end of New Space V8 triggers minor garbage collection cycle called scavenge or copying garbage collection
- scavenge algorithm similar to the Halstead semispace copying collector
to support parallel processing
- in the past scavenge used to implement Cheney's algorithm which is synchronous
- more details Generational collection section
ToSpace starts as unallocated memory.
- alloc A, B, C, D
| A | B | C | D | unallocated |
- alloc E (not enough space - exhausted Young Generation memory)
- triggers collection which partially blocks the main thread
- swap labels of FromSpace and ToSpace
- as a result the empty (previous) FromSpace is now the ToSpace
- objects on FromSpace are determined to be live or dead
- dead ones are collected
- live ones are marked and copied (expensive) out of From Space and either
- moved to ToSpace, compacted in the process to improve cache locality and considered intermediates since they survived one GC
- promoted to OldSpace if they were considered intermediates
- assuming B and D were dead
| A | C | unallocated |
- now we can allocate E
- every allocation brings us closer to GC pause
- even though as many steps of collection are performed in parallel and thus average GC pauses are small (1ms - 10ms) on average
- however every collection pauses our app
- avoid referencing short-lived objects longer than necessary, since as long as they die on the next Scavenge they incurr almost no cost to the GC, but if they need to be copied, they do
- try to pre-alloc values ahead of time if the are known when your application initializes and don't change after that, however don't go overboard, i.e. don't sacrifice code quality
watch orinoco overview | jank and concurrent GC | read
The Orinioco garbage collector was created in an attempt to lessen the time that our application stops due to garbage collection by performing as many steps as possible in parallel.
Numerous techniques like smart paging and use of concurrency friendly algorithms have been used to both partially parallelize the Old Generation and Young Generation garbage collectors.
- mostly parallel and concurrent garbage collector without strict generational boundaries
- most parts of GC taken off the main thread (56% less GC on main thread)
- optimized weak global handles
- unified heap for full garbage collection
- optimized V8's black allocation additions
- reduced peak memory consumption of on-heap peak memory by up to 40% and off-heap peak memory by 20% for low-memory devices by tuning several GC heuristics
- introduced with V8 v6.2 which is part of Node.js V8
- older V8 versions used Cheney semispace copying garbage collector that divides young
generation in two equal halves and performed moving/copying of objects that survived GC
synchronously
- single threaded scavenger made sense on single-core environments, but at this point Chrome, Node.js and thus V8 runs in many multicore scenarios
- new algorithm similar to the Halstead semispace copying collector except that V8 uses dynamic instead of static work stealing across multiple threads
As with the previous algorithm scavenge happens in four phases. All phases are performed in parallel and interleaved on each task, thus maximizing utilization of worker tasks.
- scan for roots
- majority of root set are the references from the old generation to the young generation
- remembered sets are maintained per page and thus naturally distributes the root sets among garbage collection threads
- copy objects within the young generation
- promote objects to the old generation
- objects are processed in parallel
- newly found objects are added to a global work list from which garbage collection threads can steal
- update pointers

- just a little slower than the optimized Cheney algorithm on very small heaps
- provides high throughput when heap gets larger with lots of life objects
- time spent on main thread by the scavenger was reduced by 20%-50%
- heap memory is partitioned into fixed-size chunks, called pages
- young generation evacuation is achieved in parallel by copying memory based on pages
- memory compaction parallelized on page-level
- young generation and old generation compaction phases don't depend on each other and thus are parallelized
- resulted in 75% reduction of compaction time
- GC tracks pointers to objects which have to be updated whenever an object is moved
- all pointers to old location need to be updated to object's new location
- V8 uses a rembered set of interesting pointers on the heap
- an object is interesting if it may move during garbage collection or if it lives in heavily fragmented pages and thus will be moved during compaction
- remembered sets are organized to simplify parallelization and ensure that threads get disjoint sets of pointers to update
- each page stores offsets to interesting pointers originating from that page
- assumption: objects recently allocated in the old generation should at least survive the next old generation garbage collection and thus are colored black
- black objects are allocated on black pages which aren't swept
- speeds up incremental marking process and results in less garbage collection
- Getting Garbage Collection for Free maybe outdated except the scheduling part at the beginning?
- Jank Busters Part One outdated?
- Jank Busters Part Two: Orinoco outdated except for paging, pointer tracking and black allocation?
- V8 Release 5.3
- V8 Release 5.4
- Optimizing V8 memory consumption
- Orinoco: young generation garbage collection
- fast alloc
- slow collection performed infrequently and thus in most cases doesn't affect application performance as much as the more frequently performed scavenge
~20%of objects survive into Old Generation
- parts of collection run concurrent with mutator, i.e. runs on same thread our JavaScript is executed on
- incremental marking/collection
- mark-sweep: return memory to system
- mark-compact: move values
read Mark-sweep and Mark-compact
- used to collect Old Space which may contain +100 MB of data
- scavenge impractical for more than a few MBs
- two phases
- Mark
- Sweep or Compact
- all objects on heap are discovered and marked
- objects can start at any word aligned offset in page and are at least two words long
- each page contains marking bitmap (one bit per allocatable word)
- results in memory overhead
3.1% on 32-bit, 1.6% on 64-bit systems - when marking completes all objects are either considered dead white or alive black
- that info is used during sweeping or compacting phase
- pairs of bits represent object's marking state
- white: not yet discovered by GC
- grey: discovered, but not all of its neighbors were processed yet
- black: discovered and all of its neighbors were processed
- marking deque: separately allocated buffer used to store objects being processed
- starts with clear marking bitmap and all white objects
- objects reachable from roots become grey and pushed onto marking deque
- at each step GC pops object from marking deque, marks it black
- then marks it's neighboring white objects grey and pushes them onto marking deque
- exit condition: marking deque is empty and all discovered objects are black
- large objects i.e. long arrays may be processed in pieces to avoid deque overflow
- if deque overflows, objects are still marked grey, but not pushed onto it
- when deque is empty again GC scans heap for grey objects, pushes them back onto deque and resumes marking
- both work at V8 page level == 1MB contiguous chunks (different from virtual memory pages)
- iterates across page's marking bitmap to find ranges of unmarked objects
- scans for contiguous ranges of dead objects
- converts them to free spaces
- adds them to free list
- each page maintains separate free lists
- for small regions
< 256 words - for medium regions
< 2048 words - for large regions
< 16384 words - used by scavenge algorithm for promoting surviving objects to Old Space
- used by compacting algorithm to relocate objects
- for small regions
read Mark-sweep and Mark-compact last paragraph
- reduces actual memory usage by migrating objects from fragmented pages to free spaces on other pages
- new pages may be allocated
- evacuated pages are released back to OS
read Incremental marking and lazy sweeping
- algorithm similar to regular marking
- allows heap to be marked in series of small pauses
5-10mseach (vs.500-1000msbefore) - activates when heap reaches certain threshold size
- when active an incremental marking step is performed on each memory allocation
- occurs after each incremental marking
- at this point heap knows exactly how much memory could be freed
- may be ok to delay sweeping, so actual page sweeps happen on as-needed basis
- GC cycle is complete when all pages have been swept at which point incremental marking starts again