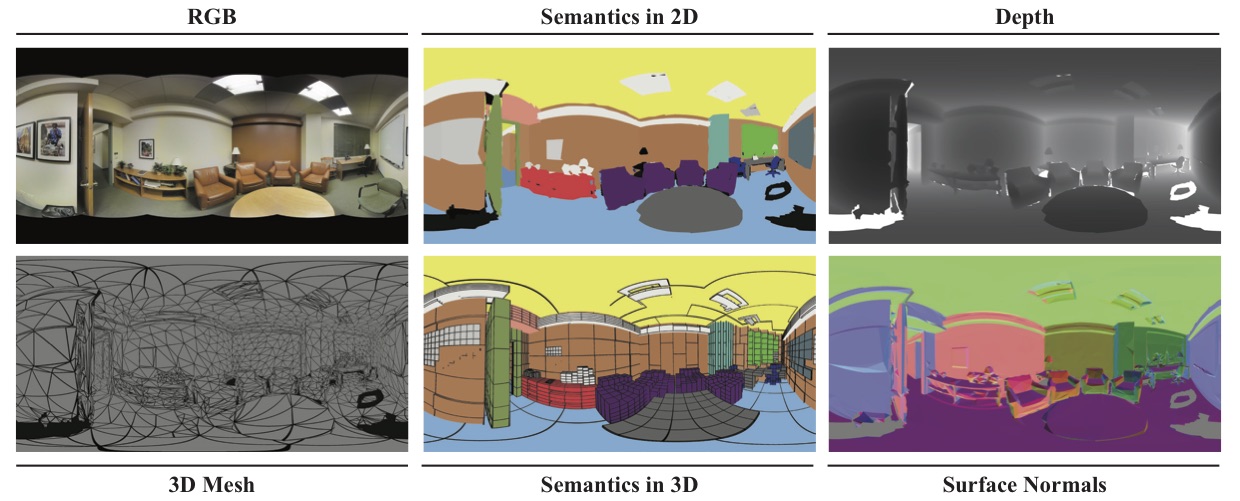
The 2D-3D-S dataset provides a variety of mutually registered modalities from 2D, 2.5D and 3D domains, with instance-level semantic and geometric annotations. It covers over 6,000 m2 collected in 6 large-scale indoor areas that originate from 3 different buildings. It contains over 70,000 RGB images, along with the corresponding depths, surface normals, semantic annotations, global XYZ images (all in forms of both regular and 360° equirectangular images) as well as camera information. It also includes registered raw and semantically annotated 3D meshes and point clouds. The dataset enables development of joint and cross-modal learning models and potentially unsupervised approaches utilizing the regularities present in large-scale indoor spaces.
This repo provides a set of tools for interacting with the dataset as well as technical information not necessarily included on the project site. For more information on the dataset, visit the [project site] or the [dataset wiki].
The link will first take you to a license agreement, and then to the data.
The full dataset is very large at 766G. Therefore, we have split the data by area to accomodate a la carte data selection. The dataset also comes in two flavors: with global_xyz images (766G) and without (110G). Once you click on the download link and accept the license agreement, the variants are accessible from in the withXYZ and noXYZ folders, respectively.
License Note: The dataset license is included in the above link. The license in this repository covers only the provided software.
If you use this dataset please cite:
@article{armeni2017joint,
title={Joint 2d-3d-semantic data for indoor scene understanding},
author={Armeni, Iro and Sax, Sasha and Zamir, Amir R and Savarese, Silvio},
journal={arXiv preprint arXiv:1702.01105},
year={2017}
}
Each physical area in the dataset has its own folder in the dataset. All the modalities and metadata for each area are contained in that folder. In addition, /assets contains some global metadata and utilities in Python. The utilities are in /assets/utils.py and contain functions for reading EXRs and parsing labels.
README.md
/assets
semantic_labels.json
utils.py
/area_1
/3d
pointcloud.mat
rgb.obj # The raw 3d mesh with rgb textures
rgb.mtl # The textures for the raw 3d mesh
semantic.obj # Semantically-tagged 3d mesh
semantic.mtl # Tectures for semantic.obj
/rgb_textures
{uuid_{i}}.jpg # Texture images for the rgb 3d mesh
/data # all of the generated data
/pose
camera_{uuid}__{room}_{i}_frame_{j}_domain__pose.json
/rgb
camera_{uuid}__{room}_{i}_frame_{j}_domain__rgb.png
/depth
/global_xyz
/normal
/semantic
/semantic_pretty
/pano # equirectangular projections
/pose
camera_{uuid}__{room}_{i}_frame_equirectangular_domain__pose.json
/rgb
/depth
/global_xyz
/normal
/semantic
/semantic_pretty
/raw # Raw data from Matterport
{uuid}_pose_{pitch_level}_{yaw_position}.txt # RT matrix for raw sensor
{uuid}_intrinsics_{pitch_level}.txt # Camera calibration for sensor at {pitch_level}
{uuid}_i{pitch_level}_{yaw_position}.jpg # Raw RGB image from sensor
{uuid}_d{pitch_level}_{yaw_position}.jpg # Raw depth image form sensor
/area_2
/area_3
/area_4
/area_5a
/area_5b
/area_6
The dataset contains colored point clouds and textured meshes for each scanned area.
3D Point Cloud: The raw colored 3D point clouds along with both object and scene instance-level annotations per point, (tightest) axis-aligned bounding boxes and voxels with binary occupancy and point correpsondence are stored in the Area_#_PointCloud.mat file. The variables are stored in the form of nested structs:
- Area: --> name: the area name as: Area_#
--> Disjoint-Space: struct with information on the individual spaces in the buidling.
In each Disjoint_Space struct:
- Disjoint_Space: --> name: the name of that space, with per area global index (e.g. conferenceRoom_1, offie_13, etc.)
-->AlignmentAngle: rotation angle around Z axis, to align spaces based on the CVPR2016 paper *3D Semantic Parsing of Large-Scale Indoor Spaces*.
--> color: a unique RGB color value [0,1] for that room, mainly for visualization purposes
--> object: a struct that contains all objects in that space.
In each object struct:
- object: --> name: the name of the object, wiith per space indexing* (e.g. chair-1, wall_3, clutter_13, etc.)
--> points: the X,Y,Z coordinates of the 3D points that comprise this object
--> RGB_color: the raw RGB color value [0,255] associated with each point.
--> global_name: the name of the object, with per area global index**
--> Bbox: [Xmin Ymin Zmin Xmax Ymax Zmax] of the object's boudning box
--> Voxels: [Xmin Ymin Zmin Xmax Ymax Zmax] for each voxel in a 6x6x6 grid
--> Voxel_Occupancy: binary occupancy per voxel (0: empty, 1: contains points)
--> Points_per_Voxel: the object points that correspond to each voxel (in XYZ coordinates)
3D Semantic mesh:
The 3D semantic mesh is labeled with instance-level per-face annotations. The mesh is stored in semantic.obj and semantic.mtl where face labels are stored as face's material's name. In Blender, for example, the material label can be retrieved with:
mesh_material_idx = mesh.data.polygons[ face_idx ].material_index
material = mesh.data.materials[ mesh_material_idx ]
label = material.name # final label!The labels follow the convention class_instanceNum_roomType_roomNum_areaNum.
When using the mesh's color, the material's color should be remapped for the task at hand as the default color is designed for visualizations. One way to encode the label in the color is to set
material.diffuse_color = get_color( labels.index( material.name ) )
by using labels from /assets/semantic_labels.json and get_color( color ) from /assets/utils.py.
The dataset contains densely sampled RGB images per scan location. We also provide depth and surface normal images, 2D semantic annotations (instance-level, per-pixel) and 3D coordinate encoded images where each pixel encodes the X, Y, Z location of the point in the world coordinate system. All images in the dataset are stored in full high-definition at 1080x1080 resolution. We provide the camera metadata for each generated image. Last, an equirectangular projection is also provided per scan location and modality.
Pose:
The pose files contain camera metadata for each image and are given in the /pose subdirectories. They have filenames which are globally unique due to the fact that camera uuids are not shared between areas. They are stored in json files, and contain
{
"camera_k_matrix": # The 3x3 camera K matrix. Stored as a list-of-lists,
"field_of_view_rads": # The Camera's field of view, in radians,
"camera_original_rotation": # The camera's initial XYZ-Euler rotation in the .obj,
"rotation_from_original_to_point":
# Apply this to the original rotation in order to orient the camera for the corresponding picture,
"point_uuid": # alias for camera_uuid,
"camera_location": # XYZ location of the camera,
"frame_num": # The frame_num in the filename,
"camera_rt_matrix": # The 4x3 camera RT matrix, stored as a list-of-lists,
"final_camera_rotation": # The camera Euler in the corresponding picture,
"camera_uuid": # The globally unique identifier for the camera location,
"room": # The room that this camera is in. Stored as roomType_roomNum_areaNum
}Note that in equirectangular images the FOV will be 90 degrees, but the image is actually panoramic and therefore a 360-degree view.
RGB:
RGB images are in the /rgb folder and contain synthesized but accurate RGB images of the scene.
Depth: Depth images are stored as 16-bit PNGs and have a maximum depth of 128m and a sensitivity of 1/512m. Missing values are encoded with the value 2^16 - 1. Note that while depth is defined relative to the plane of the camera in the data (z-depth), it is defined as the distance from the point-center of the camera in the panoramics.
Global XYZ:
Global XYZ images contain the ground-truth location of each pixel in the mesh. They are stored as 16-bit 3-channel OpenEXR files and a convenience readin function is provided in /assets/utils.py. These can be used for generating point correspondences, e.g. for optical flow. Missing values are encoded as #000000.
Normal:
Normals are 127.5-centered per-channel surface normal images. For panoramic images, these normals are relative to the global corodinate system. Since the global coordinate system is impossible to determine from a sampled image, the normal images in /data have their normals defined relative to the direction the camera is facing. The normals axis-color convention is the same one used by NYU RGB-D. Areas where the mesh is missing have pixel color #808080.
Semantic:
Semantic images come in two variants, semantic and semantic_pretty. They both include information from the point cloud annotations, but only the semantic version should be used for learning. The semantic images have RGB images which are direct 24-bit base-256 integers which contain an index into /assets/semantic_labels.json. Pixels where the data is missing are encoded with the color #0D0D0D which is larger than the len( labels ).
The raw data from the Matterport sensors is also included in the raw folder. The Matterport camera contains 3 sensors at different pitches, and rotates 60 degrees at a time to complete a 360-degree sweep. We make available both the raw RGB images and also the raw depth images which can be stitched together to make a mesh, or else used independently.
This repository provides some basic tools for interacting with the dataset. Pull requests are welcome!
The tools are located in the assets/ folder and reside in two files.
utils.py (Python) This file contains Python tools, and in general it is useful for working with images. It provides convenience functions for loading semantic labels, and reading the ground-truth label from an image pixel. It also provides a toolkit to work with .exr files.
pcl_utils.h (C++) This file contains C++ tools, and in general it is useful for working with the .obj files and point clouds. It provides convenience functions for loading 6DOF camera poses.