![]()
![]()
![]()
![]()
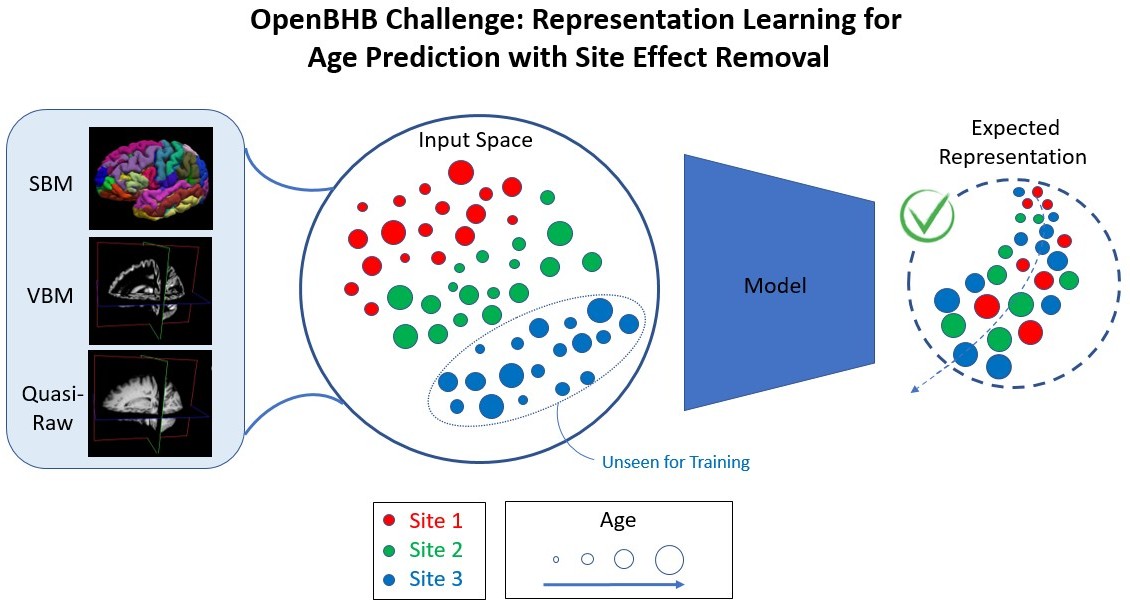
This challenge uses the openBHB dataset and aims to i) predict age from derived data from 3D T1 anatomical MRI while ii) removing site information from the learned representation. Thus, we aim to compare the capacity of proposed models to encode a relevant representation of the data (feature extraction and dimensionality reduction) that preserve the biological variability associated with age while removing the site-specific information. The algorithms submitted must be written in a PyTorch-style and output a low-dimension features vector (p < 10000). Derived data are composed of Quasi-Raw, VBM, and SBM.
You can check out our Jupyter Notebook for a concrete example: https://ramp.studio/problems/brain_age_with_site_removal
OpenBHB has an official train and validation set (available on IEEE Dataport) comprising 3227 training images and 757 validation images. The validation set is decomposed into 2 subsets: internal subset (362 images acquired from same MRI scanners as training images) and external subset (396 images acquired from other scanners/MRI sequences).
Data can also be downloaded in a convenient manner using:
python download_data.py
Warning: this will download all training and validation data (including all modalities) in a data folder, corresponding to ~55GB currently. These data can be used for local testing and debugging of your RAMP submission (see below).
Each new entry must be submitted on RAMP. You will need a RAMP account before entering into the challenge. You can sign up and ask for entering into the challenge using "Join Event".
Once you are registered to the event (Event joined), you can upload your model using Sandbox pannel (in the left pannel). 3 files are required to make your submission:
estimator.pycontaining get_estimator() function. Your PyTorch model should be wrapped into an estimator with fit() and predict() methods, in a scikit-learn fashion.weights.pthcontaining PyTorch weights that will be loaded- (Optional)
metadata.pklcontaining other Python objects (e.g. residualizers or masks) useful for your model.
Important: you will need to use read_pickle() from Pandas library in order to load this file.
Before you submit a new model, we recommend testing it locally. In particular, it allows you:
- To check if your submission will pass on RAMP servers without errors
- To evaluate your model on the public validation set, with all the metrics implemented for this challenge.
In order to debug locally (on your computer) your RAMP submission, you can first clone this repository with:
git clone https://github.com/ramp-kits/brain_age_with_site_removal.git
Then, you can create a new (local) submission by making a new directory in submissions folder:
cd brain_age_with_site_removal
mkdir submissions/my_new_submission
You can now create the 3 files required (estimator.py, weights.pth, metadata.pkl), for instance starting from the ones in the starting_kit:
cp submissions/starting_kit/* submissions/my_new_submission/
You can adapt the input data modality you give to your model using FeatureExtractor object. To debug and test locally, you can run:
ramp-test --submission my_new_submission [--quick-test]
Warning: By default (without --quick-test option) , this will download all training and validation data on your computer. Make sure you have enough space (>50GB). quick-test allows you to quickly test your model only on very small set of random data without having to download everything.
The models submitted to RAMP are ranked on the official leaderboard. They are evaluated on private data including 664 internal images and 720 external images. Participants can only make 2 submissions per week and the leaderboard is daily refreshed.
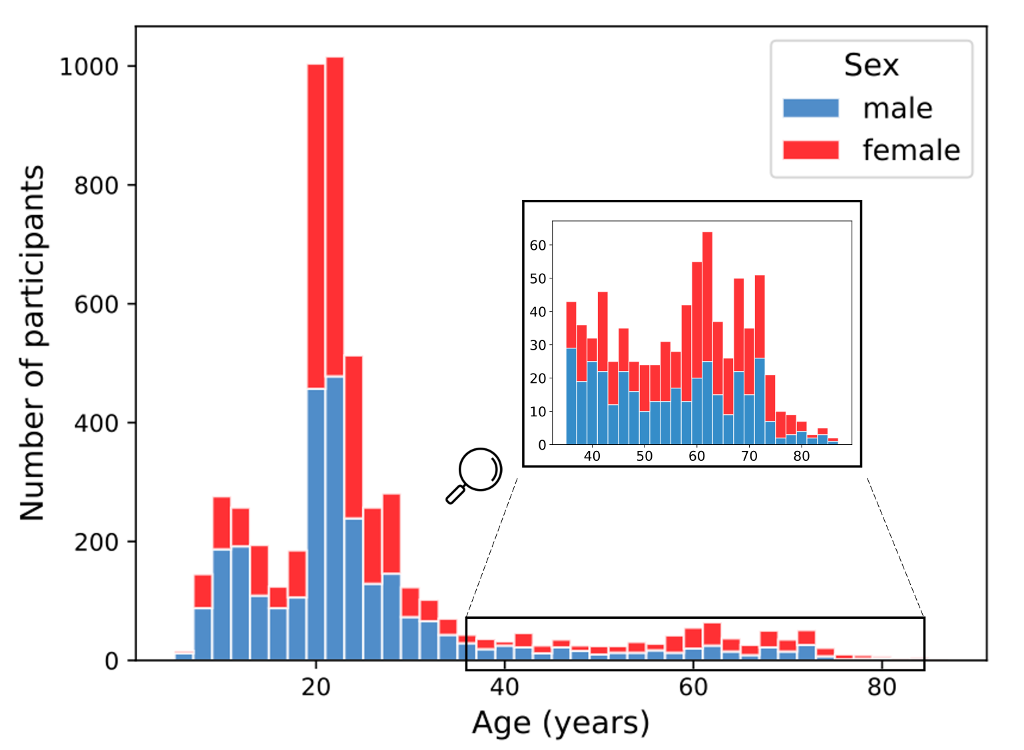
OpenBHB aggregates 10 publicly available datasets. Currently, openBHB is focused only on Healthy Controls (HC) since the main challenge consists in modeling the (normal) brain development by building a robust brain age predictor. OpenBHB contains
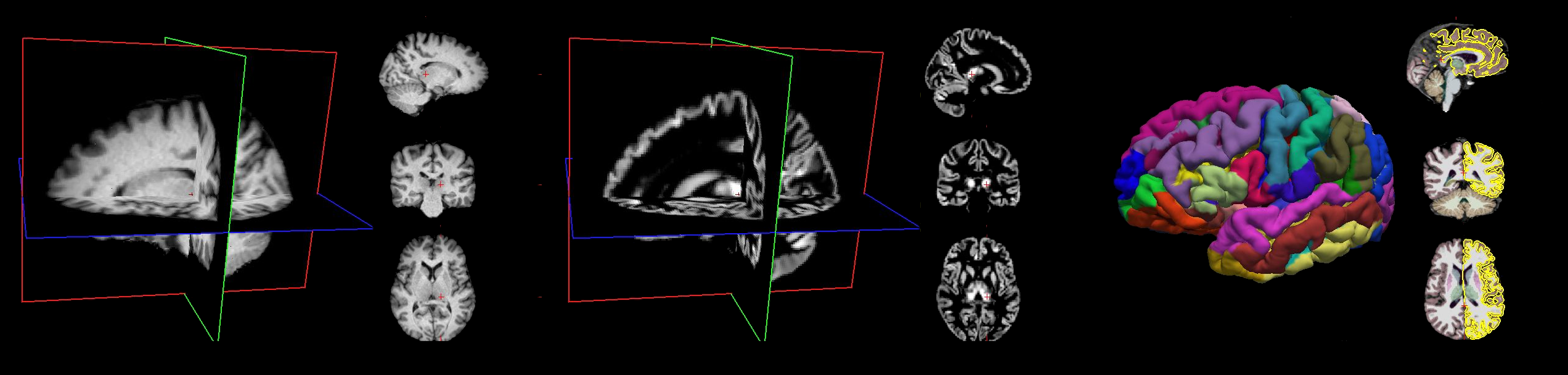
For the moment only features derived from T1w images are available comprising Quasi-Raw, CAT12 VBM, and FreeSurfer. All data are preprocessed uniformly including a semi-automatic Quality Controls (QC) guided with quality metrics.
{kind=link}
The challenge will be carried out on the RAMP platform. It enables competition and collaboration on data-science problems, using the Python language. To start "hacking", a starting kit is available. It provides a simple working example which can be expanded to more advanced solutions.
The behaviour of the code can be controlled from three environment variables:
- RAMP_BRAIN_AGE_SITERM_TEST: set this environment variable to 'on' in order to work on the test dataset. Under the hood, it will select the appropriate target labels and use a KFold cross-validation.
- RAMP_BRAIN_AGE_SITERM_SMALL: set this environment variable to 'on' in order to select a small part of the dataset. This option is usefull when testing the challenge on the server side. A KFold cross-validation is used.
- RAMP_BRAIN_AGE_SITERM_CACHE: set this environment variable to 'on' in order to save some intermediate results in a 'cahcedir' folder that in turn are used as a hard-caching system (be carefull).