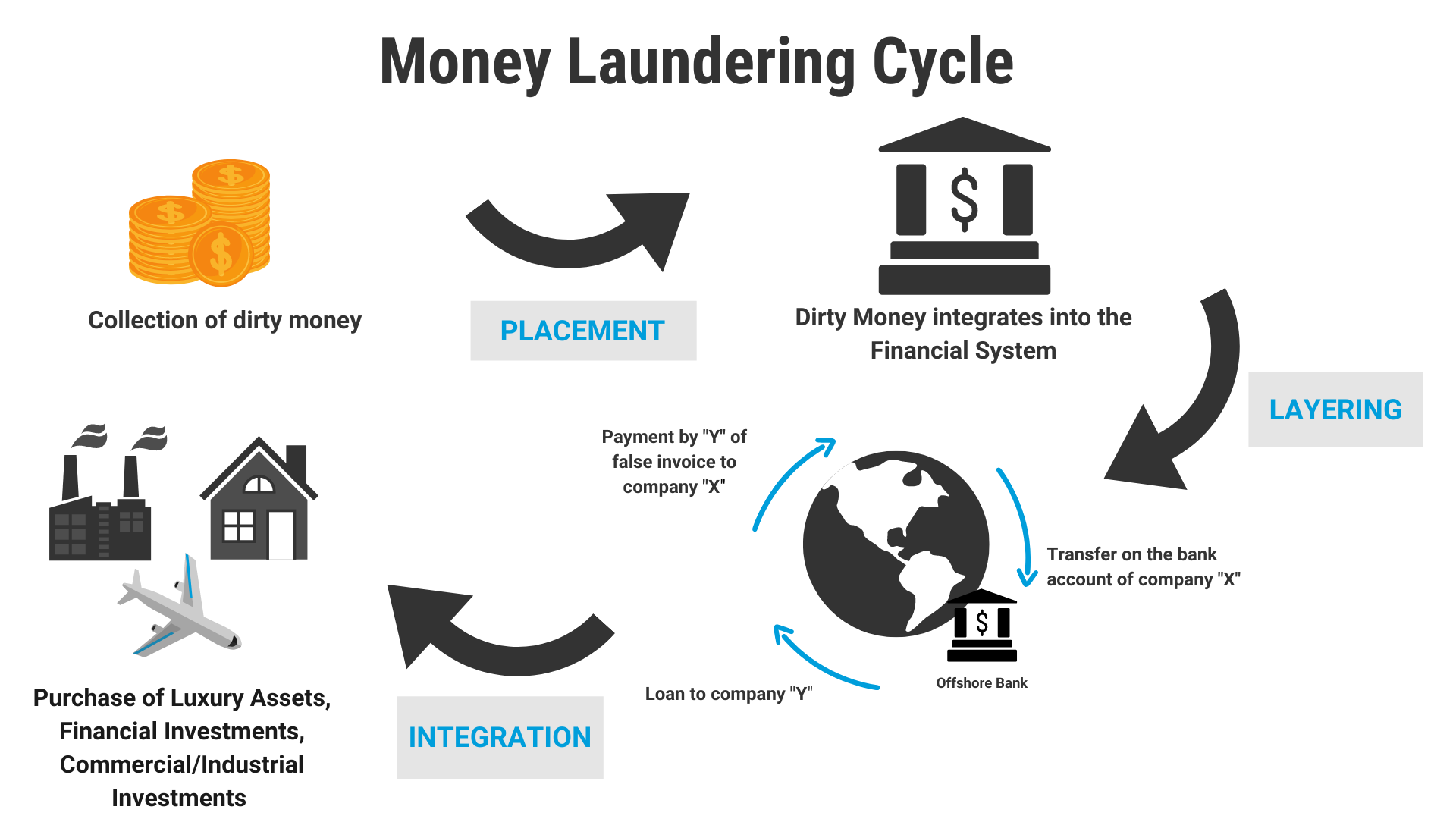
To create an AI solution for Money Laundering which reduces review operation costs by lowering the number of False Positive alerts generated by current static rule based Anti Money Laundering Alert Systems.
The solution proposed here is to create a Machine Learning model which is able to take the data from static rule based AML systems and further classify them as Fraud or Not Fraud to reduce the False Positives.
This solution can able to find:
- Currently Invisible Transaction Behaviour
- Aberrations in Transactions
- Reduce overall review Operation Costs and False Positives of AML systems.
Dataset available in kaggle: PaySim
We used PaySim synthetic dataset to train our ML model. It is based on a sample of real transactions extracted from one month of financial logs from a mobile money service implemented in an African country.
The original logs were provided by a multinational company, who is the provider of the mobile financial service which is currently running in more than 14 countries all around the world. This synthetic dataset is scaled down 1/4 of the original dataset.
This dataset contains 6362620 Transaction records with 11 features.
.
├── catboost_info
├── logs
│ ├── model_development.txt
├── predictions
│ ├── Outputs.csv
├── reports
│ ├── feature_importances.csv
│ ├── missing_values.csv
│ ├── performance.json
│ └── silhoutte_scores.csv
├── saved_models
│ ├── model.pkl
├── src
│ ├── data_preprocessing_1.py
│ ├── data_preprocessing_2.py
│ ├── data_preprocessing_3.py
│ ├── feature_selection.py
│ ├── segmentGenerator.py
│ └── model_creation.py
├── templates
│ ├── index.html
├── Procfile
├── app.py
├── requirements.txt
└── README.md
Python programming language and frameworks such as NumPy, Pandas, Scikit-learn and Catboost are used to build the whole model.

- Visual Studio Code is used as an IDE.
- For visualization of the plots, Matplotlib and Seaborn are used.
- Heroku Cloud Platform is used for deployment of the model.
- Front end development is done using HTML/CSS
- Flask framework is used for backend development
- GitHub is used as a version control system.

Our Web App Link: https://money-laundering-detection.herokuapp.com
In this web app, you just need to enter the path of your data. The model will start prediction and it will upload the outputs to the google drive folder.
In the result box, you can see the google drive folder link and output filename.