![]()
Semantic search for headlines and story text
tldrstory is a semantic search application for headlines and text content related to stories. tldrstory applies zero-shot labeling over text, which allows dynamically categorizing content. This framework also builds a txtai index that enables text similarity search. A customizable Streamlit application and FastAPI backend service allows users to review and analyze the data processed.
tldrstory has a corresponding Medium article that covers the concepts in this README and more. Check it out!
The following links are example applications built with tldrstory.
The easiest way to install is via pip and PyPI
pip install tldrstory
You can also install tldrstory directly from GitHub. Using a Python Virtual Environment is recommended.
pip install git+https://github.com/neuml/tldrstory
Python 3.8+ is supported
See this link to help resolve environment-specific install issues.
Once installed, an application must be configured to run. A tldrstory application consists of three separate processes:
- Indexing
- API backend
- Streamlit application
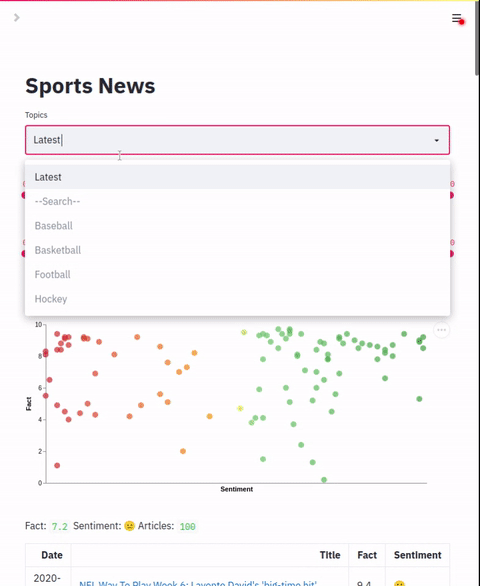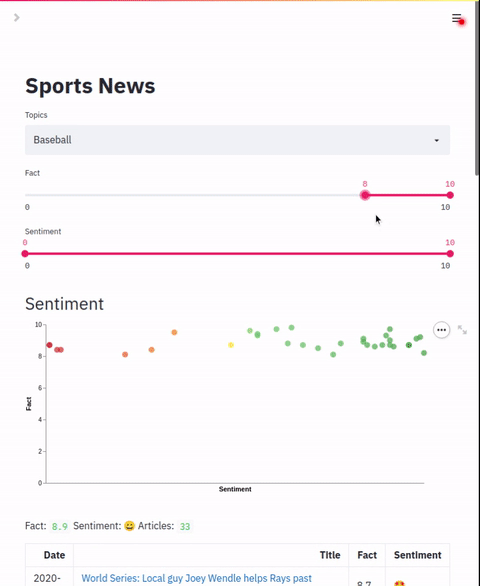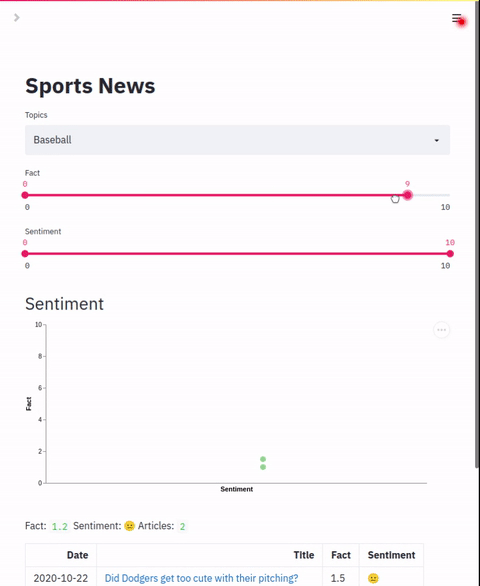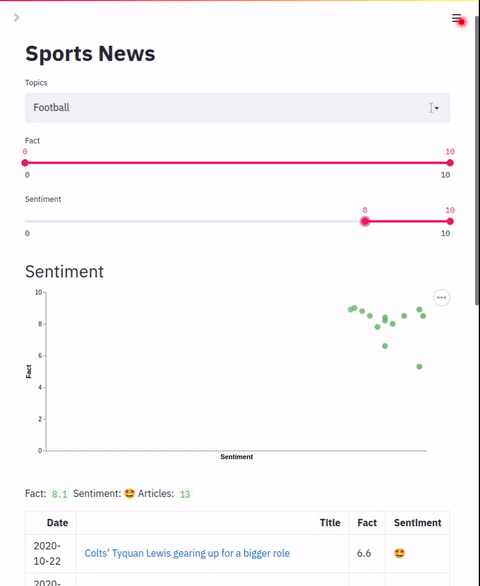
This section will show how to start the "Sports News" application.
- Download the “Sports News” application configuration.
mkdir sports
wget https://raw.githubusercontent.com/neuml/tldrstory/master/apps/sports/app.yml -O sports/app.yml
wget https://raw.githubusercontent.com/neuml/tldrstory/master/apps/sports/api.yml -O sports/api.yml
wget https://raw.githubusercontent.com/neuml/tldrstory/master/apps/sports/index-simple.yml -O sports/index.yml
wget https://raw.githubusercontent.com/neuml/tldrstory/master/src/python/tldrstory/app.py -O sports/app.py- Start the indexing process.
python -m tldrstory.index sports/index.yml- Start the API process.
CONFIG=sports/api.yml API_CLASS=tldrstory.api.API uvicorn "txtai.api:app" &- Start Streamlit.
streamlit run sports/app.py sports/app.yml "Sports" "🏆"- Open a web browser and go to http://localhost:8501
Out of the box, tldrstory supports reading data from RSS and the Reddit API. Additional data sources can be defined and configured.
The following shows an example custom data source definition. neuspo is a real-time sports event and news application. This data source loads 4 pre-defined entries into the articles database.
from tldrstory.source.source import Source
class Neuspo(Source):
"""
Articles have the following schema:
uid - unique id
source - source name
date - article date
title - article title
url - reference url for data
entry - entry date
"""
def run(self):
# List of articles created
articles = []
articles.append(self.article("0", "Neuspo", self.now(), "Eagles defeat the Giants 22 - 21",
"https://neuspo.com/stream/34952e3919d685982c17735018b0197f", self.now()))
articles.append(self.article("1", "Neuspo", self.now(), "Giants lose to the Eagles 22 - 21",
"https://t.co/e9FFgo0wgR?amp=1", self.now()))
articles.append(self.article("2", "Neuspo", self.now(), "Rays beat Dodgers 6 to 4",
"https://neuspo.com/stream/6cb820b3ebadc086aa36b5cc4a0f575d", self.now()))
articles.append(self.article("3", "Neuspo", self.now(), "Dodgers drop Game 2, 6-4",
"https://t.co/1hEQAShVnP?amp=1", self.now()))
return articlesLet’s re-run the steps above using neuspo as the data source. First remove the sports/data directory, to ensure we create a fresh database. We can then download the gist above into the sports directory.
# Delete the sports/data directory before running
wget https://gist.githubusercontent.com/davidmezzetti/9a6064d9a741acb89bd46eba9f906c26/raw/7058e97da82571005b2654b4ab908f25b9a04fe2/neuspo.py -O sports/neuspo.pyEdit sports/index.yml and remove the rss section. Replace it with the following.
# Custom data source for neuspo
source: sports.neuspo.NeuspoNow re-run steps 2–4 from the instructions above.
The following sections define configuration parameters for each process that is part of a tldrstory application.
Configures the indexing of content. Currently supports pulling data via the Reddit API, RSS and custom user-defined sources.
name: stringApplication name
schedule: stringCron-style string that enables scheduled running of the indexing job. See this link for more information on cron strings.
Data source configuration.
reddit.subreddit: name of subreddit to pull from
reddit.sort: sort type
reddit.time: time range
reddit.queries: list of text queries to runRuns a series of Reddit API queries. A Reddit API key will need to be created and configured for this method to work. Authentication parameters can be set within the enviroment or in a praw.ini file. See this link for more information on setting up a Reddit API account, read-only access is all that is needed.
See PRAW documentation for more details on how to configure the query settings.
rss: list of RSS urlsReads a series of RSS feeds and builds articles for each article link found.
source: stringConfigures a custom source. This parameter takes a full class path as a string, for example "tldrstory.source.rss.RSS"
Custom sources can be use any data that has a date, text string and reference url. See the documentation in source.py for information on how to create a custom source. rss.py and reddit.py are example implementations.
ignore: list of url patternsList of url patterns to ignore. Supports strings and regular expressions.
labels: dictLabel configuration for zero-shot classifier. This configuration sets a category along with a list of topic values.
Example:
labels:
topic:
values: [Label 1, Label 2]The example above configures the category "Topic" with two possible labels, "Label 1" and "Label 2". Any label can be set here and a large-scale NLP model will be used to categorize input text into those labels.
path: stringWhere to store model output, path will be created if it doesn't already exist.
embeddings: dictConfigures a txtai index used for searching topics. See txtai configuration for more details on this.
Configures a FastAPI backed interface for pulling indexed data.
path: stringPath to a model index.
The default application is powered by Streamlit and driven by a YAML configuration file. The configuration file sets the application name, API endpoint for pulling content, and component configuration. A custom Streamlit application or any other application can be used in place of this to pull content from the API endpoint directly.
name: stringApplication name
api: urlAPI endpoint for pulling content.
description: stringMarkdown string that is used to build a sidebar description.
queries.name: Queries drop down header
queries.values: List of values to use for queries drop downConfigures the query drop down box. This should be a list of pre-canned queries to use. If a value of "Latest" is present, it will query for the last N articles. If a value of "--Search--" is present, it will present another text box to allow entering custom queries.
filters: listList of slider filters. This should map to the zero-shot labels configured in the indexing section.
chart.name: Chart name
chart.x: Chart x-axis column
chart.y: Chart y-axis column
chart.scale: Color scale for list of colors
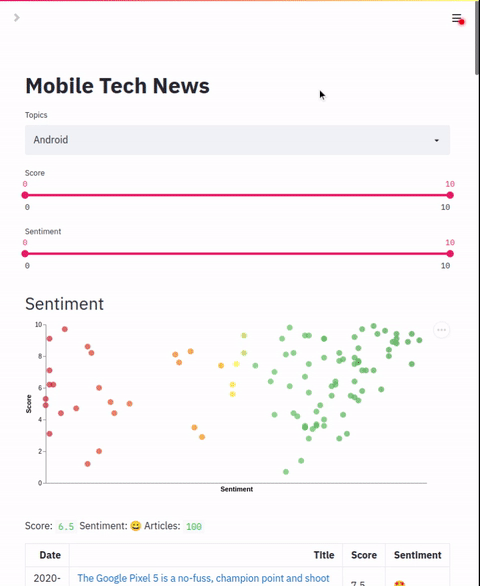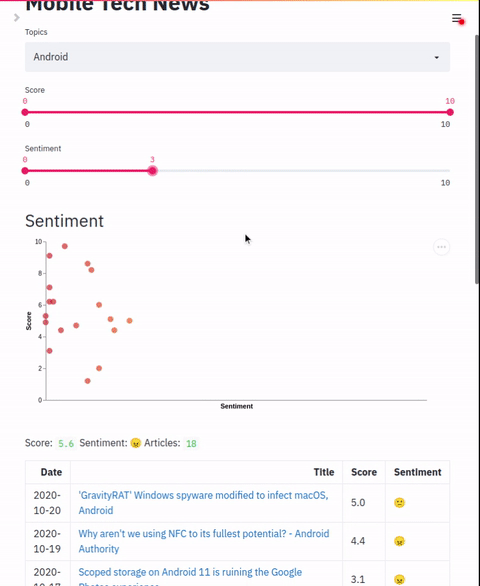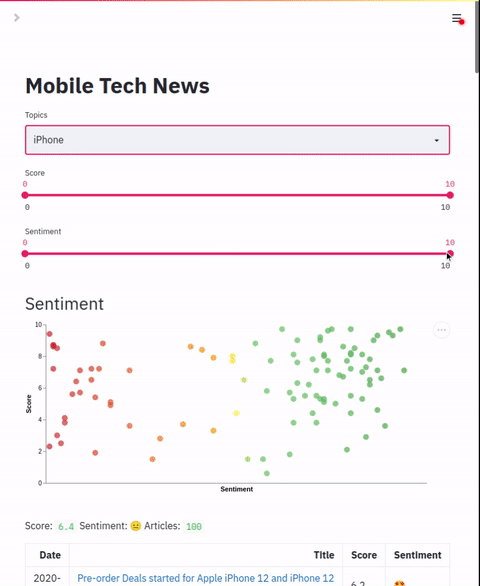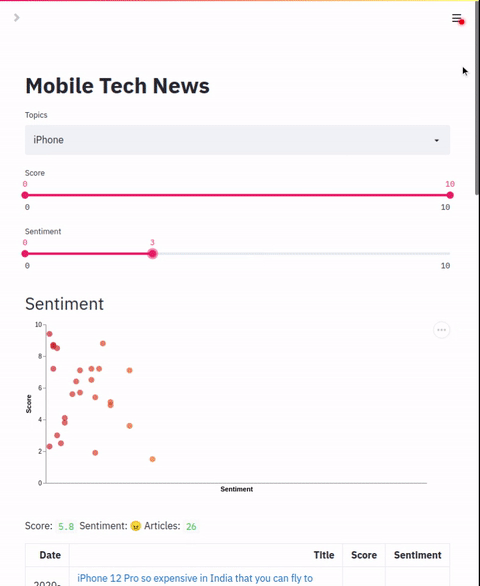
chart.colors: List of colorsAllows configuration of a scatter plot that graphs two label points. This chart can be used to plot and apply coloring to applied labels.
"column name": dynamic range of coloringData table that shows result details. In addition to default columns, this section allows adding additional columns based on the zero-shot labels applied. The default mode is to show the numeric value of the label but a range of text labels can also be applied.
For example:
- [0, 5.0, Label 1, "color: #F00"]
- [5.0, 10.0, Label 2, "color: #0F0"]
The above would output the text "Label 1" in red for values between 0 and 5. Values between 5 and 10 would output the text "Label 2" in green.