[paper] [online demo]
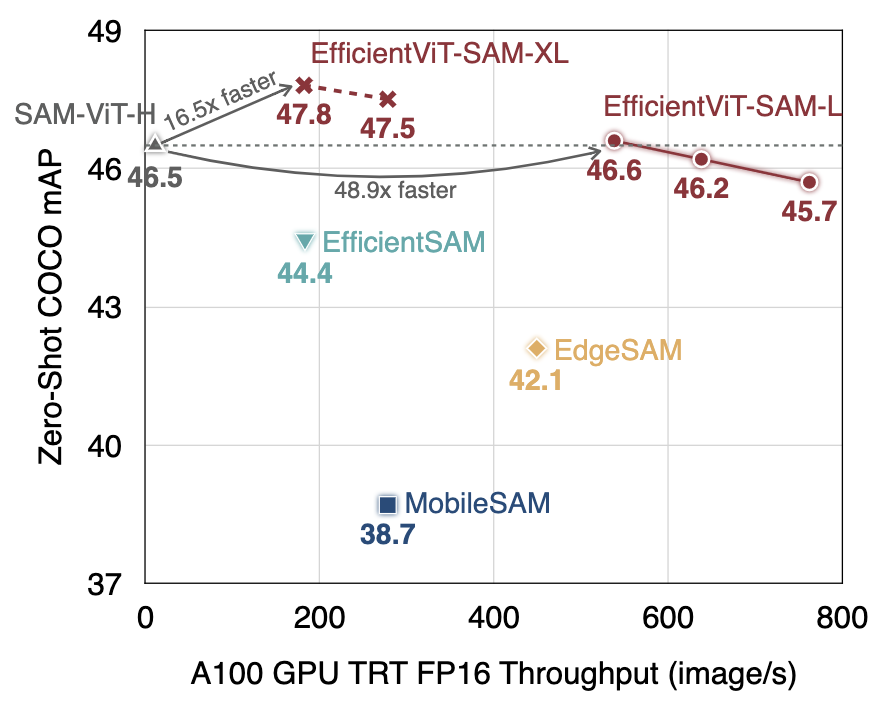
We present EfficientViT-SAM, a new family of accelerated segment anything models. We retain SAM's lightweight prompt encoder and mask decoder while replacing the heavy image encoder with EfficientViT. For the training, we begin with the knowledge distillation from the SAM-ViT-H image encoder to EfficientViT. Subsequently, we conduct end-to-end training on the SA-1B dataset. Benefiting from EfficientViT's efficiency and capacity, EfficientViT-SAM delivers 48.9x measured TensorRT speedup on A100 GPU over SAM-ViT-H without sacrificing performance.
SA-1B, COCO2017, and LVIS annotations.
To conduct box-prompted instance segmentation, you must first obtain the source_json_file of detected bounding boxes. Follow the instructions of ViTDet, YOLOv8, and GroundingDINO to get the source_json_file. You can also download our pre-generated files.
Expected directory structure:
coco
├── train2017
├── val2017
├── annotations
│ ├── instances_val2017.json
│ ├── lvis_v1_val.json
|── source_json_file
│ ├── coco_groundingdino.json
│ ├── coco_vitdet.json
│ ├── coco_yolov8.json
│ ├── lvis_vitdet.json
sam
├── images
├── masks
├── sa_images_ids.txtLatency/Throughput is measured on NVIDIA Jetson AGX Orin, and NVIDIA A100 GPU with TensorRT, fp16. Data transfer time is included. Please put the downloaded checkpoints under ${efficientvit_repo}/assets/checkpoints/efficientvit_sam/
| Model | Resolution | COCO mAP | LVIS mAP | Params | MACs | Jetson Orin Latency (bs1) | A100 Throughput (bs16) | Checkpoint |
|---|---|---|---|---|---|---|---|---|
| EfficientViT-SAM-L0 | 512x512 | 45.7 | 41.8 | 34.8M | 35G | 8.2ms | 762 images/s | link |
| EfficientViT-SAM-L1 | 512x512 | 46.2 | 42.1 | 47.7M | 49G | 10.2ms | 638 images/s | link |
| EfficientViT-SAM-L2 | 512x512 | 46.6 | 42.7 | 61.3M | 69G | 12.9ms | 538 images/s | link |
| EfficientViT-SAM-XL0 | 1024x1024 | 47.5 | 43.9 | 117.0M | 185G | 22.5ms | 278 images/s | link |
| EfficientViT-SAM-XL1 | 1024x1024 | 47.8 | 44.4 | 203.3M | 322G | 37.2ms | 182 images/s | link |
Table1: Summary of All EfficientViT-SAM Variants. COCO mAP and LVIS mAP are measured using ViTDet's predicted bounding boxes as the prompt. End-to-end Jetson Orin latency and A100 throughput are measured with TensorRT and fp16.
# segment anything
from efficientvit.sam_model_zoo import create_efficientvit_sam_model
efficientvit_sam = create_efficientvit_sam_model(name="efficientvit-sam-xl1", pretrained=True)
efficientvit_sam = efficientvit_sam.cuda().eval()from efficientvit.models.efficientvit.sam import EfficientViTSamPredictor
efficientvit_sam_predictor = EfficientViTSamPredictor(efficientvit_sam)from efficientvit.models.efficientvit.sam import EfficientViTSamAutomaticMaskGenerator
efficientvit_mask_generator = EfficientViTSamAutomaticMaskGenerator(efficientvit_sam)# COCO
torchrun --nproc_per_node=8 applications/efficientvit_sam/eval_efficientvit_sam_model.py --dataset coco --image_root ~/dataset/coco/val2017 --annotation_json_file ~/dataset/coco/annotations/instances_val2017.json --model efficientvit-sam-xl1 --prompt_type box
# expected results: all=79.927, large=83.748, medium=82.210, small=75.833# LVIS
torchrun --nproc_per_node=8 applications/efficientvit_sam/eval_efficientvit_sam_model.py --dataset lvis --image_root ~/dataset/coco --annotation_json_file ~/dataset/coco/annotations/lvis_v1_val.json --model efficientvit-sam-xl1 --prompt_type box
# expected results: all=79.886, large=91.577, medium=88.447, small=74.412# COCO
torchrun --nproc_per_node=8 applications/efficientvit_sam/eval_efficientvit_sam_model.py --dataset coco --image_root ~/dataset/coco/val2017 --annotation_json_file ~/dataset/coco/annotations/instances_val2017.json --model efficientvit-sam-xl1 --prompt_type box_from_detector --source_json_file ~/dataset/coco/source_json_file/coco_vitdet.json
# expected results:
# Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.478# LVIS
torchrun --nproc_per_node=8 applications/efficientvit_sam/eval_efficientvit_sam_model.py --dataset lvis --image_root ~/dataset/coco --annotation_json_file ~/dataset/coco/annotations/lvis_v1_val.json --model efficientvit-sam-xl1 --prompt_type box_from_detector --source_json_file ~/dataset/coco/source_json_file/lvis_vitdet.json
# expected results:
# Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=300 catIds=all] = 0.444# COCO
torchrun --nproc_per_node=8 applications/efficientvit_sam/eval_efficientvit_sam_model.py --dataset coco --image_root ~/dataset/coco/val2017 --annotation_json_file ~/dataset/coco/annotations/instances_val2017.json --model efficientvit-sam-xl1 --prompt_type point --num_click 1
# expected results: all=59.757, large=62.132, medium=63.837, small=55.029# LVIS
torchrun --nproc_per_node=8 applications/efficientvit_sam/eval_efficientvit_sam_model.py --dataset lvis --image_root ~/dataset/coco --annotation_json_file ~/dataset/coco/annotations/lvis_v1_val.json --model efficientvit-sam-xl1 --prompt_type point --num_click 1
# expected results: all=56.624, large=72.442, medium=71.796, small=47.750Please run demo_efficientvit_sam_model.py to visualize our segment anything models.
Example:
# segment everything
python applications/efficientvit_sam/demo_efficientvit_sam_model.py --model efficientvit-sam-xl1 --mode all
# prompt with points
python applications/efficientvit_sam/demo_efficientvit_sam_model.py --model efficientvit-sam-xl1 --mode point
# prompt with box
python applications/efficientvit_sam/demo_efficientvit_sam_model.py --model efficientvit-sam-xl1 --mode box --box "[150,70,640,400]"
# Export Encoder
python applications/efficientvit_sam/deployment/onnx/export_encoder.py --model efficientvit-sam-xl1 --output assets/export_models/efficientvit_sam/onnx/efficientvit_sam_xl1_encoder.onnx # Export Decoder
python applications/efficientvit_sam/deployment/onnx/export_decoder.py --model efficientvit-sam-xl1 --output assets/export_models/efficientvit_sam/onnx/efficientvit_sam_xl1_decoder.onnx --return-single-mask# ONNX Inference
python applications/efficientvit_sam/run_efficientvit_sam_onnx.py --model efficientvit-sam-xl1 --encoder_model assets/export_models/efficientvit_sam/onnx/efficientvit_sam_xl1_encoder.onnx --decoder_model assets/export_models/efficientvit_sam/onnx/efficientvit_sam_xl1_decoder.onnx --mode pointmkdir -p assets/export_models/efficientvit_sam/tensorrt/
# Export Encoder
trtexec --onnx=assets/export_models/efficientvit_sam/onnx/efficientvit_sam_xl1_encoder.onnx --minShapes=input_image:1x3x1024x1024 --optShapes=input_image:4x3x1024x1024 --maxShapes=input_image:4x3x1024x1024 --saveEngine=assets/export_models/efficientvit_sam/tensorrt/efficientvit_sam_xl1_encoder.engine# Export Decoder
trtexec --onnx=assets/export_models/efficientvit_sam/onnx/efficientvit_sam_xl1_decoder.onnx --minShapes=point_coords:1x1x2,point_labels:1x1 --optShapes=point_coords:16x2x2,point_labels:16x2 --maxShapes=point_coords:16x2x2,point_labels:16x2 --fp16 --saveEngine=assets/export_models/efficientvit_sam/tensorrt/efficientvit_sam_xl1_decoder.engine# TensorRT Inference
python applications/efficientvit_sam/run_efficientvit_sam_trt.py --model efficientvit-sam-xl1 --encoder_engine assets/export_models/efficientvit_sam/tensorrt/efficientvit_sam_xl1_encoder.engine --decoder_engine assets/export_models/efficientvit_sam/tensorrt/efficientvit_sam_xl1_decoder.engine --mode pointDownload the distilled models and place them under assets/checkpoints/efficientvit_sam/distilled_model/.
torchrun --nproc_per_node=8 applications/efficientvit_sam/train_efficientvit_sam_model.py applications/efficientvit_sam/configs/efficientvit_sam_xl1.yaml --data_provider.root ~/dataset/sam/ --path .exp/efficientvit_sam/efficientvit_sam_xl1 --resumeIf EfficientViT or EfficientViT-SAM is useful or relevant to your research, please kindly recognize our contributions by citing our papers:
@inproceedings{cai2023efficientvit,
title={Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction},
author={Cai, Han and Li, Junyan and Hu, Muyan and Gan, Chuang and Han, Song},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={17302--17313},
year={2023}
}
@article{zhang2024efficientvit,
title={EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss},
author={Zhang, Zhuoyang and Cai, Han and Han, Song},
journal={arXiv preprint arXiv:2402.05008},
year={2024}
}