
트위터에서 만든 한국어 처리기
Scala/Java library to process Korean text with a Java wrapper. twitter-korean-text currently provides Korean normalization and tokenization. Please join our community at Google Forum. The intent of this text processor is not limited to short tweet texts.
스칼라로 쓰여진 한국어 처리기입니다. 현재 텍스트 정규화와 형태소 분석, 스테밍을 지원하고 있습니다. 짧은 트윗은 물론이고 긴 글도 처리할 수 있습니다. 개발에 참여하시고 싶은 분은 Google Forum에 가입해 주세요. 사용법을 알고자 하시는 초보부터 코드에 참여하고 싶으신 분들까지 모두 환영합니다.
twitter-korean-text의 목표는 빅데이터 등에서 간단한 한국어 처리를 통해 색인어를 추출하는 데에 있습니다. 완전한 수준의 형태소 분석을 지향하지는 않습니다.
twitter-korean-text는 normalization, tokenization, stemming, phrase extraction 이렇게 네가지 기능을 지원합니다.
정규화 normalization (입니닼ㅋㅋ -> 입니다 ㅋㅋ, 샤릉해 -> 사랑해)
- 한국어를 처리하는 예시입니닼ㅋㅋㅋㅋㅋ -> 한국어를 처리하는 예시입니다 ㅋㅋ
토큰화 tokenization
- 한국어를 처리하는 예시입니다 ㅋㅋ -> 한국어Noun, 를Josa, 처리Noun, 하는Verb, 예시Noun, 입Adjective, 니다Eomi ㅋㅋKoreanParticle
어근화 stemming (입니다 -> 이다)
- 한국어를 처리하는 예시입니다 ㅋㅋ -> 한국어Noun, 를Josa, 처리Noun, 하다Verb, 예시Noun, 이다Adjective, ㅋㅋKoreanParticle
어구 추출 phrase extraction
- 한국어를 처리하는 예시입니다 ㅋㅋ -> 한국어, 처리, 예시, 처리하는 예시
Introductory Presentation: Google Slides
Gunja Agrawal kindly created a test API webpage for this project: http://gunjaagrawal.com/langhack/
Gunja Agrawal님이 만들어주신 테스트 웹 페이지 입니다. http://gunjaagrawal.com/langhack/
Opensourced here: twitter-korean-tokenizer-api
To include this in your Maven-based JVM project, add the following lines to your pom.xml:
Maven을 이용할 경우 pom.xml에 다음의 내용을 추가하시면 됩니다:
<dependency>
<groupId>com.twitter.penguin</groupId>
<artifactId>korean-text</artifactId>
<version>4.4</version>
</dependency>The maven site is available here http://twitter.github.io/twitter-korean-text/ and scaladocs are here http://twitter.github.io/twitter-korean-text/scaladocs/
modamoda kindly offered a .net wrapper: https://github.com/modamoda/TwitterKoreanProcessorCS
Ch0p kindly offered a node.js wrapper: twtkrjs
Jaepil Jeong kindly offered a Python wrapper: https://github.com/jaepil/twkorean
- Python Korean NLP project KoNLPy now includes twitter-korean-text. 파이썬에서 쉬운 활용이 가능한 KoNLPy 패키지에 포함되었습니다.
jun85664396 kindly offered a Ruby wrapper: twkorean-ruby
Clone the git repo and build using maven.
Git 전체를 클론하고 Maven을 이용하여 빌드합니다.
git clone https://github.com/twitter/twitter-korean-text.git
cd twitter-korean-text
mvn compileOpen 'pom.xml' from your favorite IDE.
You can find these examples in examples folder.
examples 폴더에 사용 방법 예제 파일이 있습니다.
from Scala
import com.twitter.penguin.korean.TwitterKoreanProcessor
import com.twitter.penguin.korean.phrase_extractor.KoreanPhraseExtractor.KoreanPhrase
import com.twitter.penguin.korean.tokenizer.KoreanTokenizer.KoreanToken
object ScalaTwitterKoreanTextExample {
def main(args: Array[String]) {
val text = "한국어를 처리하는 예시입니닼ㅋㅋㅋㅋㅋ #한국어"
// Normalize
val normalized: CharSequence = TwitterKoreanProcessor.normalize(text)
println(normalized)
// 한국어를 처리하는 예시입니다ㅋㅋ #한국어
// Tokenize
val tokens: Seq[KoreanToken] = TwitterKoreanProcessor.tokenize(normalized)
println(tokens)
// List(한국어(Noun: 0, 3), 를(Josa: 3, 1), (Space: 4, 1), 처리(Noun: 5, 2), 하는(Verb: 7, 2), (Space: 9, 1), 예시(Noun: 10, 2), 입니(Adjective: 12, 2), 다(Eomi: 14, 1), ㅋㅋ(KoreanParticle: 15, 2), (Space: 17, 1), #한국어(Hashtag: 18, 4))
// Stemming
val stemmed: Seq[KoreanToken] = TwitterKoreanProcessor.stem(tokens)
println(stemmed)
// List(한국어(Noun: 0, 3), 를(Josa: 3, 1), (Space: 4, 1), 처리(Noun: 5, 2), 하다(Verb: 7, 2), (Space: 9, 1), 예시(Noun: 10, 2), 이다(Adjective: 12, 3), ㅋㅋ(KoreanParticle: 15, 2), (Space: 17, 1), #한국어(Hashtag: 18, 4))
// Phrase extraction
val phrases: Seq[KoreanPhrase] = TwitterKoreanProcessor.extractPhrases(tokens, filterSpam = true, enableHashtags = true)
println(phrases)
// List(한국어(Noun: 0, 3), 처리(Noun: 5, 2), 처리하는 예시(Noun: 5, 7), 예시(Noun: 10, 2), #한국어(Hashtag: 18, 4))
}
}from Java
import java.util.List;
import scala.collection.Seq;
import com.twitter.penguin.korean.TwitterKoreanProcessor;
import com.twitter.penguin.korean.TwitterKoreanProcessorJava;
import com.twitter.penguin.korean.phrase_extractor.KoreanPhraseExtractor;
import com.twitter.penguin.korean.tokenizer.KoreanTokenizer;
public class JavaTwitterKoreanTextExample {
public static void main(String[] args) {
String text = "한국어를 처리하는 예시입니닼ㅋㅋㅋㅋㅋ #한국어";
// Normalize
CharSequence normalized = TwitterKoreanProcessorJava.normalize(text);
System.out.println(normalized);
// 한국어를 처리하는 예시입니다ㅋㅋ #한국어
// Tokenize
Seq<KoreanTokenizer.KoreanToken> tokens = TwitterKoreanProcessorJava.tokenize(normalized);
System.out.println(TwitterKoreanProcessorJava.tokensToJavaStringList(tokens));
// [한국어, 를, 처리, 하는, 예시, 입니, 다, ㅋㅋ, #한국어]
System.out.println(TwitterKoreanProcessorJava.tokensToJavaKoreanTokenList(tokens));
// [한국어(Noun: 0, 3), 를(Josa: 3, 1), (Space: 4, 1), 처리(Noun: 5, 2), 하는(Verb: 7, 2), (Space: 9, 1), 예시(Noun: 10, 2), 입니(Adjective: 12, 2), 다(Eomi: 14, 1), ㅋㅋ(KoreanParticle: 15, 2), (Space: 17, 1), #한국어(Hashtag: 18, 4)]
// Stemming
Seq<KoreanTokenizer.KoreanToken> stemmed = TwitterKoreanProcessorJava.stem(tokens);
System.out.println(TwitterKoreanProcessorJava.tokensToJavaStringList(stemmed));
// [한국어, 를, 처리, 하다, 예시, 이다, ㅋㅋ, #한국어]
System.out.println(TwitterKoreanProcessorJava.tokensToJavaKoreanTokenList(stemmed));
// [한국어(Noun: 0, 3), 를(Josa: 3, 1), (Space: 4, 1), 처리(Noun: 5, 2), 하다(Verb: 7, 2), (Space: 9, 1), 예시(Noun: 10, 2), 이다(Adjective: 12, 3), ㅋㅋ(KoreanParticle: 15, 2), (Space: 17, 1), #한국어(Hashtag: 18, 4)]
// Phrase extraction
List<KoreanPhraseExtractor.KoreanPhrase> phrases = TwitterKoreanProcessorJava.extractPhrases(tokens, true, true);
System.out.println(phrases);
// [한국어(Noun: 0, 3), 처리(Noun: 5, 2), 처리하는 예시(Noun: 5, 7), 예시(Noun: 10, 2), #한국어(Hashtag: 18, 4)]
}
}TwitterKoreanProcessor.scala is the central object that provides the interface for all the features.
TwitterKoreanProcessor.scala에 지원하는 모든 기능을 모아 두었습니다.
mvn test will run our unit tests
모든 유닛 테스트를 실행하려면 mvn test를 이용해 주세요.
We provide tools for quality assurance and test resources. They can be found under src/main/scala/com/twitter/penguin/korean/qa and src/main/scala/com/twitter/penguin/korean/tools.
Refer to the general contribution guide. We will add this project-specific contribution guide later.
Tested on Intel i7 2.3 Ghz
Initial loading time (초기 로딩 시간): 2~4 sec
Average time per parsing a chunk (평균 어절 처리 시간): 0.12 ms
Tweets (Avg length ~50 chars)
| Tweets | 100K | 200K | 300K | 400K | 500K | 600K | 700K | 800K | 900K | 1M |
|---|---|---|---|---|---|---|---|---|---|---|
| Time in Seconds | 57.59 | 112.09 | 165.05 | 218.11 | 270.54 | 328.52 | 381.09 | 439.71 | 492.94 | 542.12 |
| Average per tweet: 0.54212 ms |
Benchmark test by KoNLPy
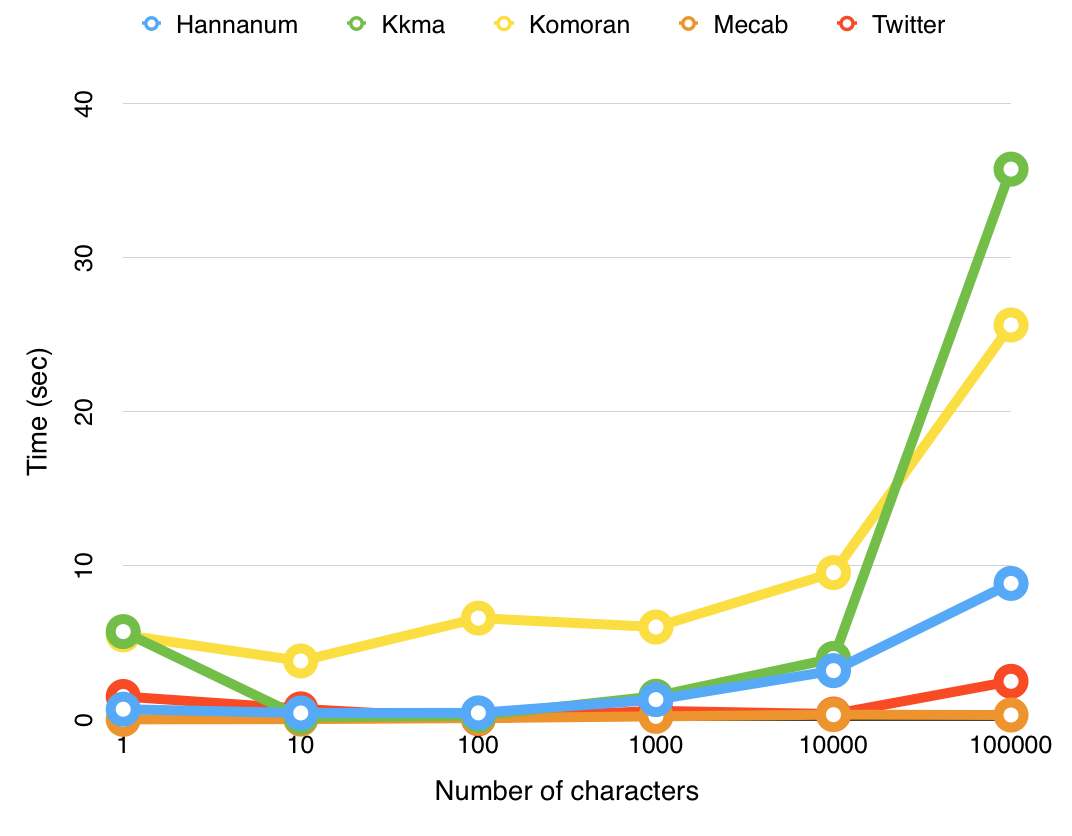
From http://konlpy.org/ko/v0.4.2/morph/
- Will Hohyon Ryu (유호현): https://github.com/nlpenguin | https://twitter.com/NLPenguin
Copyright 2014 Twitter, Inc.
Licensed under the Apache License, Version 2.0: http://www.apache.org/licenses/LICENSE-2.0