API
OnlineStats.ADADELTA — TypeOnlineStats.ADAGRAD — TypeADAGRAD()A variation of SGD with element-wise weights generated by the average of the squared gradients.
- Reference: https://ruder.io/optimizing-gradient-descent/
- Note: ADAGRAD uses a learning rate in OnlineStats, which differs from how it is typically presented. See https://www.seqstat.com/post/adagrad/ for details.
OnlineStats.ADAM — TypeADAM(β1 = .99, β2 = .999)A variant of SGD with element-wise learning rates generated by exponentially weighted first and second moments of the gradient.
- Reference: https://ruder.io/optimizing-gradient-descent/
OnlineStats.ADAMAX — TypeADAMAX(η, β1 = .9, β2 = .999)ADAMAX with momentum parameters β1, β2. ADAMAX is an extension of ADAM.
- Reference: https://ruder.io/optimizing-gradient-descent/
OnlineStats.Ash — TypeAsh(h::Union{KHist, Hist, ExpandingHist})
+Ash(h::Union{KHist, Hist, ExpandingHist}, m::Int, kernel::Function)Create an Average Shifted Histogram using h as the base histogram with smoothing parameter m and kernel function kernel. Built-in kernels are available in the OnlineStats.Kernels module.
Example
using OnlineStats, Plots
+
+o = fit!(Ash(ExpandingHist(1000)), randn(10^6))
+
+plot(o)
+plot(o, 20)
+plot(o, OnlineStats.Kernels.epanechnikov, 4)OnlineStats.AutoCov — TypeAutoCov(b, T = Float64; weight=EqualWeight())Calculate the auto-covariance/correlation for lags 0 to b for a data stream of type T.
Example
y = cumsum(randn(100))
+o = AutoCov(5)
+fit!(o, y)
+autocov(o)
+autocor(o)OnlineStats.BiasVec — TypeBiasVec(x)Lightweight wrapper of a vector which adds a bias/intercept term at the end.
Example
BiasVec(rand(5))OnlineStats.Bootstrap — TypeBootstrap(o::OnlineStat, nreps = 100, d = [0, 2])Calculate an online statistical bootstrap of nreps replicates of o. For each call to fit!, any given replicate will be updated rand(d) times (default is double or nothing).
Example
o = Bootstrap(Variance())
+fit!(o, randn(1000))
+confint(o, .95)OnlineStats.CCIPCA — TypeCCIPCA(outdim::Int, indim; l::Int)Online PCA with the CCIPCA (Candid Covariance-free Incremental PCA) algorithm, where indim is the length of incoming vectors, outdim is the number of dimension to project to, and l is the level of amnesia. Give values of l in the range 2-4 if you want old vectors to be gradually less important, i.e. latest vectors added get more weight.
If no indim is specified it will be set later, on first call to fit. After that it is fixed and cannot change.
The CCIPCA is a very fast, simple, and online approximation of PCA. It can be used for Dimensionality Reduction to project high-dimensional vectors into a low-dimensional (typically 2D or 3D) space. This algorithm has shown very good properties in comparative studies; it is both fast and give a good approximation to (batch) PCA.
Example
o = CCIPCA(2, 10) # Project 10-dimensional vectors into 2D
+u1 = rand(10)
+fit!(o, u1) # Fit to u1
+u2 = rand(10)
+fit!(o, u2) # Fit to u2
+u3 = rand(10)
+OnlineStats.transform(o, u3) # Project u3 into PCA space fitted to u1 and u2 but don't change the projection
+u4 = rand(10)
+OnlineStats.fittransform!(o, u4) # Fit u4 and then project u4 into the space
+sort!(o) # Sort from high to low eigenvalues
+o[1] # Get primary (1st) eigenvector
+OnlineStats.relativevariances(o) # Get the variation (explained) "by" each eigenvectorOnlineStats.CallFun — TypeCallFun(o::OnlineStat, f::Function)Call f(o) every time the OnlineStat o gets updated.
Example
o = CallFun(Mean(), println)
+fit!(o, [0,0,1,1])OnlineStats.Cluster — TypeCluster center and the number of observations
OnlineStats.CountMinSketch — TypeCountMinSketch(T = Number; nhash=50, hashlength=1000, storagetype=Int)Create a Count-Min Sketch with nhash hash functions of width hashlength. Counts in the sketch will be stored as storagetype.
This lets you calculate an upper bound on the number of occurrences of some value x in a data stream via value(count_min_sketch, x). For details and error bounds, please see the references section.
Example
o = CountMinSketch()
+
+y = rand(1:100, 10^6)
+
+fit!(o, y)
+
+value(o, 1)
+
+sum(y .== 1)References
- https://florian.github.io/count-min-sketch/
OnlineStats.DPMM — TypeDPMM(comp_mu::Real,
+ comp_lambda::Real,
+ comp_alpha::Real,
+ comp_beta::Real,
+ dirichlet_alpha::Real;
+ comp_birth_thres=1e-2,
+ comp_death_thres=1e-2,
+ n_comp_max=10)Online univariate dirichlet process Gaussian mixture model algorithm.
Mathematical Description
The model is described as
G ~ DP(dirchlet_alpha, Normal-Gamma)
+(μₖ, τₖ) ~ G
+x ~ N(μ, 1/sqrt(τ))where the base measure is defined as
τₖ ~ Gamma(comp_alpha, 1/comp_beta)
+μₖ ~ N(comp_mu, 1/sqrt(comp_lambda*τₖ)).The variational distribution is the mean-field family defined as
q(μₖ | τₖ; mₖ, lₖ) q(τₖ; aₖ, bₖ) = N(μₖ; mₖ, 1/(lₖ*τₖ)) Gamma(τₖ; aₖ, 1/bₖ).Since the model is nonparametric, mixture components are added depending on the birth threshold comp_birth_thres (higher means less frequen births) and existing components are pruned depending on the death threshold comp_death_thres.
Hyperparameters
DPMMs tend to be very sensitive to its hyperparameters. Therefore, it is important to monitor the fitted result and tweak the hyperparameters accordingly. Here are the implications of each hyperparameter:
comp_mu: Prior mean of the componentscomp_lambda: Prior precision of the components. This affects the dispersion of the components relative to the scale of each component. (Smaller the more dispersed.) (comp_lambda> 0)comp_alpha: Gamma shape parameter of the scale (inverse of the variance) of each component. (comp_alpha> 0)comp_beta: Gamma scale parameter of the scale (inverse of the variance) of each component. (comp_beta> 0)dirichlet_alpha: Initial weight of a newly added component. Larger values result in more components being created. (dirichlet_alpha> 0)comp_birth_thres: Threshold for adding a new component (highly affected bydirichlet_alpha)comp_death_thres: Threshold for prunning (or killing) an existing component.
A mechanical procedure for setting the component hyperparameters is to first set comp_alpha > 2. This ensures the variance to be finite. Then, solve comp_beta such that the Gamma distribution concentrates most of the probability density on the expected range of 1/τₖ, the variance of each component. Finally, solve for comp_lambda such that the marginal density of μₖ, which is a Student-T distribution
p(μₖ | λ₀, α₀, β₀)
+ = ∫ p(μₖ | τₖ, μ₀, λ₀) p(τₖ | α₀, β₀) dτₖ
+ = ∫ N(μₖ; μ₀, 1/sqrt(λ₀*τₖ)) Gamma(τₖ; αₖ, βₖ) dτₖ
+ = TDist( 2*α₀, μ₀, sqrt(β₀/(λ₀*α₀)),has its probability density concentrated on the expected range of the component means.
Below is a implementing the prior elicitation procedure described above:
using Roots
+
+prob_τₖ = 0.8
+τₖ_max = 0.5
+μ₀ = 0.0
+α₀ = 2.1
+prob_μₖ = 0.8
+μₖ_min = -2
+μₖ_max = 2
+
+β₀ = find_zero(β₀ -> cdf(InverseGamma(α₀, β₀), τₖ_max) - prob_τₖ, (1e-4, Inf))
+λ₀ = find_zero(λ₀ -> begin
+ p_μ = TDist(2*α₀)*sqrt(β₀/(λ₀*α₀)) + μ₀
+ cdf(p_μ, μₖ_max) - cdf(p_μ, μₖ_min) - prob_τₖ
+end, (1e-4, 1e+2))prob_* sets the amount of density on the desired range. τₖ_max, μₖ_min, μₖ_max is the expected range of each parameters. Since we leave 1 - prob_* density on the tails, these are soft contraints.
Unfortunately, dirichlet_alpha, comp_birth_thres, comp_death_thres can be tuned only through trial and error. However, dirichlet_alpha is best set 0.5 ~ 1e-2 depending on the desired number of components.
Example
n = 1024
+μ = 0.0
+λ = 0.1
+α = 2.1
+β = 0.5
+α_dp = 1.0
+o = DPMM(μ, λ, α, β, α_dp; comp_birth_thres=0.5,
+ comp_death_thres=1e-2, n_comp_max=10)
+p = MixtureModel([ Normal(-2.0, 0.5), Normal(3.0, 1.0) ], [0.7, 0.3])
+o = fit!(o, rand(p, 1000))OnlineStats.DWDLoss — TypeDWDLoss(q)(y, xβ)Distance-weighted discrimination loss function (smoothed l1hingeloss) with smoothing parameter q. Loss is calculated between a boolean response y ∈ {-1, 1} and linear predictor xβ.
OnlineStats.Diff — TypeDiff(T::Type = Float64)Track the difference and the last value.
Example
o = Diff()
+fit!(o, [1.0, 2.0])
+last(o)
+diff(o)OnlineStats.ElasticNet — TypeElasticNet(α)Weighted average of Ridge (abs) and LASSO (abs2) penalty functions.
$(1 - α) * Ridge + α * LASSO$
OnlineStats.ExpandingHist — TypeExpandingHist(nbins)An adaptive histogram where the bin edges keep doubling in size in order to contain every observation. nbins must be an even number. Bins are left-closed and the rightmost bin is closed, e.g.
[a, b),[b, c),[c, d]
Example
o = fit!(ExpandingHist(200), randn(10^6))
+
+using Plots
+plot(o)Details
How ExpandingHist works is best understood through example. Suppose we start with a histogram of edges/counts as follows:
|1|2|5|3|2|- Now we observe a data point that is not contained in the bin edges:
|1|2|5|3|2| *- In order to contain the point, the range of the edges doubles in the direction of the new data point and adjacent bins merge their counts:
|1|2|5|3|2| *
+ \ / \ / \ / ↓
+ ↓ ↓ ↓ ↓
+| 3 | 8 | 2 | 0 | 1 |- Note that multiple iterations of bin-doubling may occur until the new point is contained by the bin edges.
OnlineStats.FastForest — TypeFastForest(p, nkeys=2; stat=FitNormal(), kw...)Calculate a random forest where each variable is summarized by stat.
Keyword Arguments
nt=100): Number of trees in the forestb=floor(Int, sqrt(p)): Number of random features for each tree to receivemaxsize=1000: Maximum size for any tree in the forestsplitsize=5000: Number of observations in any given node before splittingλ = .05: Probability that each tree is updated on a new observation
Example
x, y = randn(10^5, 10), rand(1:2, 10^5)
+
+o = fit!(FastForest(10), zip(eachrow(x),y))
+
+classify(o, x[1,:])OnlineStats.FastTree — TypeFastTree(p::Int, nclasses=2; stat=FitNormal(), maxsize=5000, splitsize=1000)Calculate a decision tree of p predictors variables and classes 1, 2, …, nclasses. Nodes split when they reach splitsize observations until maxsize nodes are in the tree. Each variable is summarized by stat, which can be FitNormal() or Hist(nbins).
Example
x = randn(10^5, 10)
+y = rand([1,2], 10^5)
+
+o = fit!(FastTree(10), zip(eachrow(x),y))
+
+xi = randn(10)
+classify(o, xi)OnlineStats.FitBeta — TypeFitBeta(; weight)Online parameter estimate of a Beta distribution (Method of Moments).
Example
o = fit!(FitBeta(), rand(1000))OnlineStats.FitCauchy — TypeFitCauchy(b=500)Approximate parameter estimation of a Cauchy distribution. Estimates are based on approximated quantiles. See Quantile and ExpandingHist for details on how the distribution is estimated.
Example
o = fit!(FitCauchy(), randn(1000))OnlineStats.FitGamma — TypeFitGamma(; weight)Online parameter estimate of a Gamma distribution (Method of Moments).
Example
using Random
+o = fit!(FitGamma(), randexp(10^5))OnlineStats.FitLogNormal — TypeFitLogNormal()Online parameter estimate of a LogNormal distribution (MLE).
Example
o = fit!(FitLogNormal(), exp.(randn(10^5)))OnlineStats.FitMultinomial — TypeFitMultinomial(p)Online parameter estimate of a Multinomial distribution. The sum of counts does not need to be consistent across observations. Therefore, the n parameter of the Multinomial distribution is returned as 1.
Example
x = [1 2 3; 4 8 12]
+fit!(FitMultinomial(3), x)OnlineStats.FitMvNormal — TypeFitMvNormal(d)Online parameter estimate of a d-dimensional MvNormal distribution (MLE).
Example
y = randn(100, 2)
+o = fit!(FitMvNormal(2), eachrow(y))OnlineStats.FitNormal — TypeFitNormal()Calculate the parameters of a normal distribution via maximum likelihood.
Example
o = fit!(FitNormal(), randn(1000))OnlineStats.GeometricMean — TypeGeometricMean(T = Float64)Calculate the geometric mean of a data stream, stored as type T.
Example
o = fit!(GeometricMean(), 1:100)OnlineStats.HeatMap — TypeHeatmap(xedges, yedges; left = true, closed = true)
+Heatmap(itr; left = true, closed = true)Create a two dimensional histogram with the bin partition created by xedges and yedges. When fitting a new observation, the first value will be associated with X, the second with Y.
- If
left, the bins will be left-closed. - If
closed, the bins on the ends will be closed. SeeHist.
Example
using Plots
+
+xy = zip(randn(10^6), randn(10^6))
+o = fit!(HeatMap(-5:.1:5, -5:.1:5), xy)
+plot(o)
+
+xy = zip(1 .+ randn(10^6) ./ 10, randn(10^6))
+o = HeatMap(xy)
+plot(o, marginals=false)
+plot(o)OnlineStats.Hist — TypeHist(edges; left = true, closed = true)Create a histogram with bin partition defined by edges.
- If
left, the bins will be left-closed. - If
closed, the bin on the end will be closed.- E.g. for a two bin histogram $[a, b), [b, c)$ vs. $[a, b), [b, c]$
Example
o = fit!(Hist(-5:.1:5), randn(10^6))
+
+# approximate statistics
+using Statistics
+
+mean(o)
+var(o)
+std(o)
+quantile(o)
+median(o)
+extrema(o)OnlineStats.HyperLogLog — TypeHyperLogLog(T = Number)
+HyperLogLog{P}(T = Number)Approximate count of distinct elements of a data stream of type T, using 2 ^ P "registers". P must be an integer between 4 and 16 (default).
By default it returns the improved HyperLogLog cardinality estimator as defined by [1].
The original HyperLogLog estimator [2] can be retrieved with the option original_estimator=true.
Example
o = HyperLogLog()
+fit!(o, rand(1:100, 10^6))
+
+using Random
+o2 = HyperLogLog(String)
+fit!(o2, [randstring(20) for i in 1:1000])
+
+# by default the improved estimator is returned:
+value(o)
+# the original HyperLogLog estimator can be retrieved via:
+value(o; original_estimator=true)References
[1] Improved estimator: Otmar Ertl. New cardinality estimation algorithms for HyperLogLog sketches. https://arxiv.org/abs/1702.01284
[2] Original estimator: P. Flajolet, Éric Fusy, O. Gandouet, and F. Meunier. Hyperloglog: The analysis of a near-optimal cardinality estimation algorithm. In Analysis of Algorithms (AOFA), pages 127–146, 2007.
OnlineStats.IndexedPartition — TypeIndexedPartition(T, stat, b=100)Summarize data with stat over a partition of size b where the data is indexed by a variable of type T.
Example
x, y = randn(10^5), randn(10^6)
+o = IndexedPartition(Float64, KHist(10))
+fit!(o, zip(x, y))
+
+using Plots
+plot(o)OnlineStats.KHist — TypeKHist(k::Int)Estimate the probability density of a univariate distribution at k approximately equally-spaced points.
Ref: https://www.jmlr.org/papers/volume11/ben-haim10a/ben-haim10a.pdf
A difference from the above reference is that the minimum and maximum values are not allowed to merge into another bin.
Example
o = fit!(KHist(25), randn(10^6))
+
+# Approximate statistics
+using Statistics
+mean(o)
+var(o)
+std(o)
+quantile(o)
+median(o)
+
+using Plots
+plot(o)OnlineStats.KHist2D — TypeKHist2D(b=300)Approximate scatterplot of b centers. This implementation is slow! See IndexedPartition and KIndexedPartition instead.
Example
x = randn(10^4)
+y = x + randn(10^4)
+plot(fit!(KHist2D(), zip(x, y)))OnlineStats.KIndexedPartition — TypeKIndexedPartition(T, stat_init, k=100)Similar to IndexedPartition, but indexes the first variable by centroids (like KHist) rather than intervals.
- Note:
stat_initmust be a function e.g.() -> Mean()
Example
using Plots
+
+o = KIndexedPartition(Float64, () -> KHist(10))
+
+fit!(o, zip(randn(10^6), randn(10^6)))
+
+plot(o)OnlineStats.KMeans — TypeKMeans(k; rate=LearningRate(.6))Approximate K-Means clustering of k clusters.
Example
x = [randn() + 5i for i in rand(Bool, 10^6), j in 1:2]
+
+o = fit!(KMeans(2, 2), eachrow(x))
+
+sort!(o; rev=true) # Order clusters by number of observations
+
+classify(o, x[1]) # returns index of cluster closest to x[1]OnlineStats.KahanMean — TypeKahanMean(; T=Float64, weight=EqualWeight())Track a univariate mean. Uses a compensation term for the update.
#Note
This should be more accurate as Mean in most cases but the guarantees of KahanSum do not apply. merge! can have some accuracy issues.
Update
$μ = (1 - γ) * μ + γ * x$
Example
@time fit!(KahanMean(), randn(10^6))OnlineStats.KahanSum — TypeKahanSum(T::Type = Float64)Track the overall sum. Includes a compensation term that effectively doubles precision, see Wikipedia for details.
Example
fit!(KahanSum(Float64), fill(1, 100))OnlineStats.KahanVariance — TypeKahanVariance(; T=Float64, weight=EqualWeight())Track the univariate variance. Uses compensation terms for a higher accuracy.
#Note
This should be more accurate as Variance in most cases but the guarantees of KahanSum do not apply. merge! can have accuracy issues.
Example
o = fit!(KahanVariance(), randn(10^6))
+mean(o)
+var(o)
+std(o)OnlineStats.Lag — TypeLag(T, b::Int)Store the last b values for a data stream of type T. Values are stored as
$v(t), v(t-1), v(t-2), …, v(t-b+1)$
so that value(o::Lag)[1] is the most recent observation and value(o::Lag)[end] is the b-th most recent observation.
Example
o = fit!(Lag(Int, 10), 1:12)
+o[1]
+o[end]OnlineStats.LinReg — TypeLinReg()Linear regression, optionally with element-wise ridge regularization.
Example
x = randn(100, 5)
+y = x * (1:5) + randn(100)
+o = fit!(LinReg(), zip(eachrow(x),y))
+coef(o)
+coef(o, .1)
+coef(o, [0,0,0,0,Inf])OnlineStats.LinRegBuilder — TypeLinRegBuilder(p)Create an object from which any variable can be regressed on any other set of variables, optionally with element-wise ridge regularization. The main function to use with LinRegBuilder is coef:
coef(o::LinRegBuilder, λ = 0; y=1, x=[2,3,...], bias=true, verbose=false)Return the coefficients of a regressing column y on columns x with ridge (abs2 penalty) parameter λ. An intercept (bias) term is added by default.
Examples
x = randn(1000, 10)
+o = fit!(LinRegBuilder(), eachrow(x))
+
+coef(o; y=3, verbose=true)
+
+coef(o; y=7, x=[2,5,4])OnlineStats.LogSumExp — TypeLogSumExp(T::Type = Float64)For positive numbers that can be very small (or very large), it's common to store each log(x) instead of each x itself, to avoid underflow (or overflow). LogSumExp takes values in this representation and adds them, returning the result in the same representation.
Ref: https://www.nowozin.net/sebastian/blog/streaming-log-sum-exp-computation.html
Example
x = randn(1000)
+
+fit!(LogSumExp(), x)
+
+log(sum(exp.(x))) # should be very closeOnlineStats.MSPI — TypeMSPI()Majorized Stochastic Proximal Iteration.
- Reference: https://repository.lib.ncsu.edu/handle/1840.20/34945
OnlineStats.Mosaic — TypeMosaic(T::Type, S::Type)Data structure for generating a mosaic plot, a comparison between two categorical variables.
Example
using OnlineStats, Plots
+x = [rand() > .8 for i in 1:10^5]
+y = rand([1,2,2,3,3,3], 10^5)
+o = fit!(Mosaic(Bool, Int), zip(x, y))
+plot(o)OnlineStats.MovingTimeWindow — TypeMovingTimeWindow{T<:TimeType, S}(window::Dates.Period)
+MovingTimeWindow(window::Dates.Period; valtype=Float64, timetype=Date)Fit a moving window of data based on time stamps. Each observation must be a Tuple, NamedTuple, or Pair where the first item is <: Dates.TimeType. Observations with a timestamp NOT in the range
now() - window ≤ timestamp ≤ now()are discarded on every fit!.
Example
using Dates
+dts = Date(2010):Day(1):Date(2011)
+y = rand(length(dts))
+
+o = MovingTimeWindow(Day(4); timetype=Date, valtype=Float64)
+fit!(o, zip(dts, y))OnlineStats.MovingWindow — TypeMovingWindow(b, T)
+MovingWindow(T, b)Track a moving window of b items of type T. Also known as a circular buffer.
Example
o = MovingWindow(10, Int)
+fit!(o, 1:14)OnlineStats.NBClassifier — TypeNBClassifier(p::Int, T::Type; stat = Hist(15))Calculate a naive bayes classifier for classes of type T and p predictors. For each class K, predictor variables are summarized by the stat.
Example
x, y = randn(10^4, 10), rand(Bool, 10^4)
+
+o = fit!(NBClassifier(10, Bool), zip(eachrow(x),y))
+collect(keys(o))
+probs(o)
+
+xi = randn(10)
+predict(o, xi)
+classify(o, xi)OnlineStats.OMAP — TypeOMAP()Online MM via Averaged Parameter.
- Reference: https://repository.lib.ncsu.edu/handle/1840.20/34945
OnlineStats.OMAS — TypeOMAS()Online MM via Averaged Surrogate.
- Reference: https://repository.lib.ncsu.edu/handle/1840.20/34945
OnlineStats.OrderStats — TypeOrderStats(b::Int, T::Type = Float64; weight=EqualWeight())Average order statistics with batches of size b.
Example
o = fit!(OrderStats(100), randn(10^5))
+quantile(o, [.25, .5, .75])
+
+f = ecdf(o)
+f(0)OnlineStats.P2Quantile — TypeP2Quantile(τ = 0.5)Calculate the approximate quantile via the P^2 algorithm. It is more computationally expensive than the algorithms used by Quantile, but also more exact.
Ref: https://www.cse.wustl.edu/~jain/papers/ftp/psqr.pdf
Example
fit!(P2Quantile(.5), rand(10^5))OnlineStats.Partition — TypePartition(stat)
+Partition(stat, nparts)Split a data stream into nparts (default 100) where each part is summarized by stat.
Example
o = Partition(Extrema())
+fit!(o, cumsum(randn(10^5)))
+
+using Plots
+plot(o)OnlineStats.ProbMap — TypeProbMap(T::Type; weight=EqualWeight())
+ProbMap(A::AbstractDict{T, Float64}; weight=EqualWeight())Track a dictionary that maps unique values to its probability. Similar to CountMap, but uses a weighting mechanism.
Example
o = ProbMap(Int)
+fit!(o, rand(1:10, 1000))
+probs(o)OnlineStats.Quantile — TypeQuantile(q::Vector{Float64} = [0, .25, .5, .75, 1]; b=500)Calculate (approximate) quantiles from a data stream. Internally uses ExpandingHist to estimate the distribution, for which b is the number of histogram bins. Setting b to a larger number will increase accuracy at the cost of speed.
Example
q = [.25, .5, .75]
+x = randn(10^6)
+
+o = fit!(Quantile(q, b=1000), randn(10^6))
+value(o)
+
+quantile(x, q)OnlineStats.RMSPROP — TypeRMSPROP(α = .9)A Variation of ADAGRAD that uses element-wise weights generated by an exponentially weighted mean of the squared gradients.
- Reference: https://ruder.io/optimizing-gradient-descent/
OnlineStats.ReservoirSample — TypeReservoirSample(k::Int, T::Type = Float64)Create a sample without replacement of size k. After running through n observations, the probability of an observation being in the sample is 1 / n.
Example
fit!(ReservoirSample(100, Int), 1:1000)OnlineStats.SGD — TypeSGD()Stochastic Gradient Descent.
- Reference: https://ruder.io/optimizing-gradient-descent/
OnlineStats.StatLag — TypeStatLag(stat, b)Track a moving window (previous b copies) of stat.
Example
fit!(StatLag(Mean(), 10), 1:20)OnlineStats.StatLearn — TypeStatLearn(args...; penalty=zero, rate=LearningRate())Fit a model (via stochastic approximation) that is linear in the parameters. The (offline) objective function that StatLearn approximately minimizes is
$(1/n) ∑ᵢ f(yᵢ, xᵢ'β) + ∑ⱼ λⱼ g(βⱼ),$
where $fᵢ$ are loss functions of a response variable and linear predictor, $λⱼ$s are nonnegative regularization parameters, and $g$ is a penalty function.
Use StatLearn with caution, as stochastic approximation algorithms are inherently noisy.
Arguments
loss = OnlineStats.l2regloss: The loss function to be (approximately) minimized.- Regression Losses:
l2regloss: Squared error lossl1regloss: Absolute error loss
- Classification (y ∈ {-1, 1}) Losses:
logisticloss: Logistic regressionl1hingeloss: Loss function used in Support Vector Machines.DWDLoss(q): Generalized Distance Weighted Discrimination (smoothedl1hingeloss)
- Regression Losses:
algorithm = MSPI(): The stochastic approximation method to be used.- Algorithms based on Stochastic gradient:
SGD(): Stochastic Gradient DescentADAGRAD(): AdaGrad (adaptive version of SGD)RMSPROP(): RMSProp (adaptive version of SGD)
- Algorithms based on Majorization-Minimization Principle:
MSPI(): Majorized Stochastic Proximal IterationOMAS(): Online MM via Averaged SurrogateOMAP(): Online MM via Averaged Parameter
- Algorithms based on Stochastic gradient:
λ = 0.0: The hyperparameter(s) used for the penalty function- User can provide elementwise penalty hyperparameters (
Vector{Float64}) or single hyperparameter (Float64).
- User can provide elementwise penalty hyperparameters (
Keyword Arguments
penalty: The regularization function used.zero: no penalty (default)abs: (LASSO) parameters penalized by their absolute valueabs2: (Ridge) parameters penalized by their squared valueElasticNet(α): α * (abs penalty) + (1-α) * (abs2 penalty)
rate = LearningRate(.6)
Example
x = randn(1000, 5)
+y = x * range(-1, stop=1, length=5) + randn(1000)
+
+o = fit!(StatLearn(MSPI()), zip(eachrow(x), y))
+coef(o)
+
+o = fit!(StatLearn(OnlineStats.l1regloss, ADAGRAD()), zip(eachrow(x), y))
+coef(o)OnlineStats.Trace — TypeTrace(stat, b=500, f=value)Wrapper around an OnlineStat that stores b "snapshots" (a fixed copy of the OnlineStat). The snapshots are taken at approximately equally-spaced intervals between 0 and the current nobs. The main use case is visualizing state changes as observations are added.
Example
using OnlineStats, Plots
+
+o = Trace(Mean(), 10)
+
+fit!(o, 1:100)
+
+OnlineStats.snapshots(o)
+
+plot(o)Base.sort! — Methodsort!(o::CCIPCA)Sort eigenvalues and their eigenvectors of o so highest ones come first. Useful before visualising since it ensures most variation is on the first (X) axis.
OnlineStats.eigenvalue — Methodeigenvalue(o::CCIPCA, i::Int)Get the ith eigenvalue of o. Also called principal variance for PCA.
OnlineStats.eigenvector — Methodeigenvector(o::CCIPCA, i::Int)Get the ith eigenvector of o.
OnlineStats.fittransform! — Methodfittransform!(o::CCIPCA, u::Vector{Float64})First fit! and then transform the vector u into the PCA space represented by o.
OnlineStats.l1hingeloss — Methodl1hingeloss(y, xβ)Loss function between boolean response y ∈ {-1, 1} and linear predictor xβ for support vector machines:
$max(1 - y * xβ, 0)$
OnlineStats.l1regloss — Methodl1regloss(y, xβ)Loss function between continuous response y and linear predictor xβ based on the $L_1$ norm:
$|y - xβ|$
OnlineStats.l2regloss — Methodl2regloss(y, xβ)Loss function between continuous response y and linear predictor xβ based on the $L_2$ norm:
$.5 * (y - xβ) ^ 2$
OnlineStats.logisticloss — Methodlogisticloss(y, xβ)Loss function between boolean response y ∈ {-1, 1} and linear predictor xβ for logistic regression:
$log(1 + exp(-y * xβ))$
OnlineStats.principalvar — Methodeigenvalue(o::CCIPCA, i::Int)Get the ith eigenvalue of o. Also called principal variance for PCA.
OnlineStats.reconstruct — Methodreconstruct(o::CCIPCA, uproj::AbstractArray{Float64})Reconstruct the (projected) vector uproj back to the original space from which o has been fitted.
OnlineStats.relativevariances — Methodrelativevariances(o::CCIPCA)Get the relative variance (explained) in the direction of each eigenvector. Returns a vector of zeros if no vectors have yet been fitted. Note that this does not inclue the residual variance that is not captured in the eigenvectors.
OnlineStatsBase.value — Methodvalue(o::DPMM)Realize the mixture model where each component is the marginal predictive distribution obtained as
q(x; mₖ, lₖ, aₖ, bₖ)
+ = ∫ N(x; μₖ, sqrt(1/τₖ)) q(μₖ | τₖ; mₖ, lₖ) q(τₖ; aₖ, bₖ) dμₖ dτₖ
+ = ∫ N(x; mₖ, sqrt(1/τₖ + 1/(lₖ*τₖ))) Gamma(τₖ; aₖ, bₖ) dμₖ dτₖ
+ = TDist( 2*aₖ, mₖ, sqrt(bₖ/aₖ*(lₖ+1)/lₖ) )StatsAPI.confint — Functionconfint(b::Bootstrap, coverageprob = .95)Return a confidence interval for a Bootstrap b.
StatsBase.transform — Methodtransform(o::CCIPCA, u::AbstractArray{Float64})Transform (i.e. project) the vector u into the PCA space represented by o.
OnlineStatsBase.CircBuff — TypeCircBuff(T, b; rev=false)Create a fixed-length circular buffer of b items of type T.
rev=false:o[1]is the oldest.rev=true:o[end]is the oldest.
Example
a = CircBuff(Int, 5)
+b = CircBuff(Int, 5, rev=true)
+
+fit!(a, 1:10)
+fit!(b, 1:10)
+
+a[1] == b[end] == 1
+a[end] == b[1] == 10
+
+value(o; ordered=false) # Retrieve values (no copy) without orderingOnlineStatsBase.CountMap — TypeCountMap(T::Type)
+CountMap(dict::AbstractDict{T, Int})Track a dictionary that maps unique values to its number of occurrences. Similar to StatsBase.countmap.
Counts can be incremented by values other than one (and decremented) using the fit!(::CountMap{T}, ::Pair{T,Int}) method, e.g.
o = fit!(CountMap(String), ["A", "B"])
+fit!(o, "A" => 5)
+fit!(o, "A" => -1)Example
o = fit!(CountMap(Int), rand(1:10, 1000))
+value(o)
+OnlineStatsBase.probs(o)
+OnlineStats.pdf(o, 1)
+collect(keys(o))
+sort!(o)
+delete!(o, 1)OnlineStatsBase.CountMissing — TypeCountMissing(stat)Calculate a stat along with the count of missing values.
Example
o = CountMissing(Mean())
+fit!(o, [1, missing, 3])OnlineStatsBase.Counter — TypeCounter(T=Number)Count the number of items in a data stream with elements of type T.
Example
fit!(Counter(Int), 1:100)OnlineStatsBase.CovMatrix — TypeCovMatrix(p=0; weight=EqualWeight())
+CovMatrix(::Type{T}, p=0; weight=EqualWeight())Calculate a covariance/correlation matrix of p variables. If the number of variables is unknown, leave the default p=0.
Example
o = fit!(CovMatrix(), randn(100, 4) |> eachrow)
+cor(o)
+cov(o)
+mean(o)
+var(o)OnlineStatsBase.Extrema — TypeExtrema(T::Type = Float64)
+Extrema(min_init::T, max_init::T)Maximum and minimum (and number of occurrences for each) for a data stream of type T.
Example
Extrema(Float64) == Extrema(Inf, -Inf)
+
+o = fit!(Extrema(), rand(10^5))
+extrema(o)
+maximum(o)
+minimum(o)OnlineStatsBase.ExtremeValues — TypeExtremeValues(T = Float64, b=25)Track the b smallest and largest values of a data stream (as well as how many times that value occurred).
Example
o = ExtremeValues(Int, 3)
+
+fit!(o, 1:100)
+
+value(o).lo # [1 => 1, 2 => 1, 3 => 1]
+
+value(o).hi # [98 => 1, 99 => 1, 100 => 1]OnlineStatsBase.FilterTransform — TypeFilterTransform(stat::OnlineStat{S}, T = S; filter = x->true, transform = identity)
+FilterTransform(T => filter => transform => stat)Wrapper around an OnlineStat that the filters and transforms its input. Note that, depending on your transformation, you may need to specify the type of a single observation (T).
Examples
o = FilterTransform(Mean(), Union{Missing,Number}, filter=!ismissing)
+fit!(o, [1, missing, 3])
+
+o = FilterTransform(String => (x->true) => (x->parse(Int,x)) => Mean())
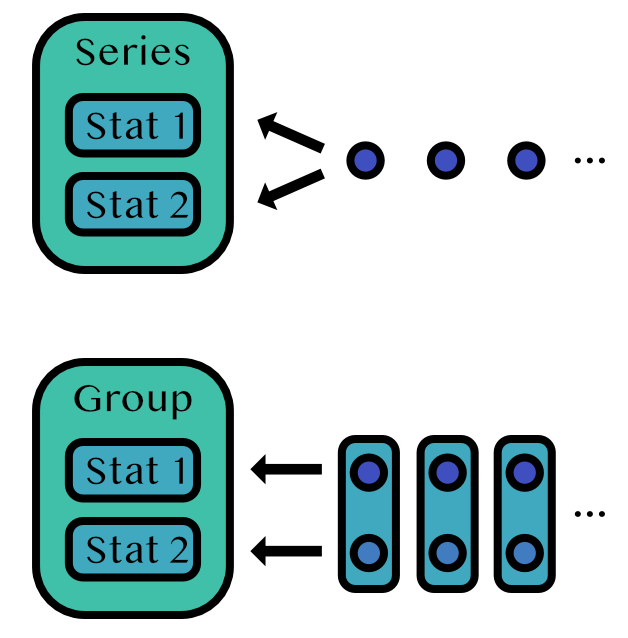
+fit!(o, "1")OnlineStatsBase.Group — TypeGroup(stats::OnlineStat...)
+Group(; stats...)
+Group(collection)Create a vector-input stat from several scalar-input stats. For a new observation y, y[i] is sent to stats[i].
Examples
x = randn(100, 2)
+
+fit!(Group(Mean(), Mean()), eachrow(x))
+fit!(Group(Mean(), Variance()), eachrow(x))
+
+o = fit!(Group(m1 = Mean(), m2 = Mean()), eachrow(x))
+o.stats.m1
+o.stats.m2OnlineStatsBase.GroupBy — TypeGroupBy(T, stat)Update stat for each group (of type T). A single observation is either a (named) tuple with two elements or a Pair.
Example
x = rand(Bool, 10^5)
+y = x .+ randn(10^5)
+fit!(GroupBy(Bool, Series(Mean(), Extrema())), zip(x,y))OnlineStatsBase.Mean — TypeMean(T = Float64; weight=EqualWeight())Track a univariate mean, stored as type T.
Example
@time fit!(Mean(), randn(10^6))OnlineStatsBase.Moments — TypeMoments(; weight=EqualWeight())First four non-central moments.
Example
o = fit!(Moments(), randn(1000))
+mean(o)
+var(o)
+std(o)
+skewness(o)
+kurtosis(o)OnlineStatsBase.RepeatingRange — TypeRepeatingRange(rng)Range that repeats forever. e.g.
r = OnlineStatsBase.RepeatingRange(1:2)
+r[1:5] == [1, 2, 1, 2, 1]OnlineStatsBase.Series — TypeSeries(stats)
+Series(stats...)
+Series(; stats...)Track a collection stats for one data stream.
Example
s = Series(Mean(), Variance())
+fit!(s, randn(1000))OnlineStatsBase.SkipMissing — TypeSkipMissing(stat)Wrapper around an OnlineStat that will skip over missing values.
Example
o = SkipMissing(Mean())
+
+fit!(o, [1, missing, 3])OnlineStatsBase.Sum — TypeSum(T::Type = Float64)Track the overall sum.
Example
fit!(Sum(Int), fill(1, 100))OnlineStatsBase.TryCatch — TypeTryCatch(stat; error_limit=1000, error_message_limit=90)Wrap each call to fit! in a try-catch block and track the errors encountered (via CountMap). Only error_limit unique errors will be included in the CountMap. If a new error occurs after error_limit has been reached, it will be included in the CountMap as "Other". Only the first error_message_limit characters of each error message will be recorded.
Example
o = TryCatch(Mean())
+
+fit!(o, [1, missing, 3])
+
+OnlineStatsBase.errors(o)OnlineStatsBase.Variance — TypeVariance(T = Float64; weight=EqualWeight())Univariate variance, tracked as type T.
Example
o = fit!(Variance(), randn(10^6))
+mean(o)
+var(o)
+std(o)Base.merge! — Methodmerge!(a, b)Merge OnlineStat b into a (supported by most OnlineStat types).
Example
a = fit!(Mean(), 1:10)
+b = fit!(Mean(), 11:20)
+merge!(a, b)OnlineStatsBase.smooth! — Methodsmooth!(a, b, γ)Update a in place by applying the smooth function elementwise with b.
OnlineStatsBase.smooth — Methodsmooth(a, b, γ)Weighted average of a and b with weight γ.
$(1 - γ) * a + γ * b$
OnlineStatsBase.smooth_syr! — Methodsmooth_syr!(A::AbstractMatrix, x, γ::Number)Weighted average of symmetric rank-1 update. Updates the upper triangle of:
A = (1 - γ) * A + γ * x * x'
OnlineStatsBase.value — Methodvalue(stat::OnlineStat)Calculate the value of stat from its "sufficient statistics".
StatsAPI.fit! — Methodfit!(stat1::OnlineStat, stat2::OnlineStat)Alias for merge!. Merges stat2 into stat1.
Useful for reductions of OnlineStats using fit!.
Example
julia> v = [reduce(fit!, [1, 2, 3], init=Mean()) for _ in 1:3]
+3-element Vector{Mean{Float64, EqualWeight}}:
+Mean: n=3 | value=2.0
+Mean: n=3 | value=2.0
+Mean: n=3 | value=2.0
+
+julia> reduce(fit!, v, init=Mean())
+Mean: n=9 | value=2.0StatsAPI.fit! — Methodfit!(stat::OnlineStat, data)Update the "sufficient statistics" of a stat with more data. If typeof(data) is not the type of a single observation for the provided stat, fit! will attempt to iterate through and fit! each item in data. Therefore, fit!(Mean(), 1:10) translates roughly to:
o = Mean()
+
+for x in 1:10
+ fit!(o, x)
+end
 ","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"using OnlineStats","category":"page"},{"location":"howfitworks/#Details-of-Updating-(fit!)","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"","category":"section"},{"location":"howfitworks/#Core-Principles","page":"Details of Updating (fit!)","title":"Core Principles","text":"","category":"section"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"Stats are subtypes of OnlineStat{T} where T is the type of a single observation.\nE.g. Mean <: OnlineStat{Number}\nfit!(o::OnlineStat{T}, data::T)\nUpdate o with the single observation data.\nfit!(o::OnlineStat{T}, data::S)\nIterate through data and fit! each item.","category":"page"},{"location":"howfitworks/#Why-is-Fitting-Based-on-Iteration?","page":"Details of Updating (fit!)","title":"Why is Fitting Based on Iteration?","text":"","category":"section"},{"location":"howfitworks/#Reason-1:-OnlineStats-doesn't-make-assumptions-on-the-shape-of-your-data","page":"Details of Updating (fit!)","title":"Reason 1: OnlineStats doesn't make assumptions on the shape of your data","text":"","category":"section"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"Consider CovMatrix, for which a single observation is an AbstractVector, Tuple, or NamedTuple. If I try to fit! it with a Matrix, it's ambiguous whether I want rows or columns of the matrix to be treated as individual observations.","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"note: Note\nSee eachrow and eachcol (after typing using LinearAlgebra).","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"x = randn(1000, 2)\n\nfit!(CovMatrix(), eachrow(x))\n\nfit!(CovMatrix(), eachcol(x'))","category":"page"},{"location":"howfitworks/#Reason-2:-OnlineStats-works-out-of-the-box-with-many-data-structures","page":"Details of Updating (fit!)","title":"Reason 2: OnlineStats works out-of-the-box with many data structures","text":"","category":"section"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"Tabular data structures such as those in JuliaDB iterate over named tuples of rows, so things like this just work:","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"using JuliaDB\n\nt = table(randn(100), randn(100))\n\nfit!(2Mean(), t)","category":"page"},{"location":"howfitworks/#A-Common-Error","page":"Details of Updating (fit!)","title":"A Common Error","text":"","category":"section"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"Consider the following example:","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"fit!(Mean(), \"asdf\")","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"This causes an error because:","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"\"asdf\" is not a Number, so OnlineStats attempts to iterate through it\nIterating through \"asdf\" begins with the character 'a'","category":"page"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"ENV[\"GKSwstype\"] = \"100\"\nENV[\"GKS_ENCODING\"]=\"utf8\"","category":"page"},{"location":"stats_and_models/#Statistics-and-Models","page":"Statistics and Models","title":"Statistics and Models","text":"","category":"section"},{"location":"stats_and_models/#Univariate-Statistics","page":"Statistics and Models","title":"Univariate Statistics","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic OnlineStat\nMean Mean\nVariance Variance\nQuantiles Quantile, OrderStats, and P2Quantile\nMaximum/Minimum Extrema\nSkewness and kurtosis Moments\nSum Sum\nGeometric Mean GeometricMean","category":"page"},{"location":"stats_and_models/#Plotting-(See-[Data-Visualization](@ref))","page":"Statistics and Models","title":"Plotting (See Data Visualization)","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"info: Info\nMany OnlineStats have Plot recipes beyond what is listed here.","category":"page"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Plot OnlineStat\nBig Data Viz Partition, IndexedPartition, KIndexedPartition\nMosaic Plot Mosaic\nHeatMap HeatMap","category":"page"},{"location":"stats_and_models/#Time-Series","page":"Statistics and Models","title":"Time Series","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic OnlineStat\nDifference Diff\nLag Lag\nAutocorrelation/autocovariance AutoCov\nTracked history Trace, StatLag","category":"page"},{"location":"stats_and_models/#Multivariate-Analysis","page":"Statistics and Models","title":"Multivariate Analysis","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic/Model OnlineStat\nCovariance/correlation matrix CovMatrix\nPrincipal components analysis CovMatrix, CCIPCA\nK-means clustering KMeans\nMultiple univariate statistics Group","category":"page"},{"location":"stats_and_models/#Nonparametric-Density-Estimation","page":"Statistics and Models","title":"Nonparametric Density Estimation","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic/Model OnlineStat\nHistograms/continuous density Hist, KHist, and ExpandingHist\nASH density (semiparametric, similar to KDE) Ash\nApproximate order statistics OrderStats\nCount for each unique value CountMap\nApproximate CDF OrderStats","category":"page"},{"location":"stats_and_models/#Parametric-Density-Estimation","page":"Statistics and Models","title":"Parametric Density Estimation","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Distribution OnlineStat\nBeta FitBeta\nCauchy FitCauchy\nGamma FitGamma\nLogNormal FitLogNormal\nNormal FitNormal\nMultinomial FitMultinomial\nMvNormal FitMvNormal","category":"page"},{"location":"stats_and_models/#Machine/Statistical-Learning","page":"Statistics and Models","title":"Machine/Statistical Learning","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Model OnlineStat\nLinear (also ridge) regression LinReg, LinRegBuilder\nDecision Trees FastTree\nRandom Forest FastForest\nNaive Bayes Classifier NBClassifier\nML via Stochastic Approximation StatLearn","category":"page"},{"location":"stats_and_models/#Other","page":"Statistics and Models","title":"Other","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic/Model OnlineStat\nHandling Missing Data FilterTransform, CountMissing, SkipMissing\nStatistical Bootstrap Bootstrap\nApprox. count of distinct elements HyperLogLog\nApprox. count of occurrences CountMinSketch\nRandom sample ReservoirSample\nMoving Window MovingWindow, MovingTimeWindow","category":"page"},{"location":"stats_and_models/#Collection-of-Stats","page":"Statistics and Models","title":"Collection of Stats","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic/Model OnlineStat\nUnivariate data stream Series\nMultivariate data streams Group\nGroup by categorical variable GroupBy","category":"page"},{"location":"stats_and_models/#Stochastic-Approximation-with-[StatLearn](@ref)","page":"Statistics and Models","title":"Stochastic Approximation with StatLearn","text":"","category":"section"},{"location":"stats_and_models/#Regression-and-Classification-Losses","page":"Statistics and Models","title":"Regression and Classification Losses","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Loss Function\nL_2 Loss (squared error) OnlineStats.l2regloss\nL_1 Loss (absolute error) OnlineStats.l1regloss\nLogistic Loss OnlineStats.logisticloss\nL_1 Hinge Loss OnlineStats.l1hingeloss\nGeneralized distance weighted discrimination OnlineStats.DWDLoss","category":"page"},{"location":"stats_and_models/#Penalty/regularization-functions","page":"Statistics and Models","title":"Penalty/regularization functions","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Penalty Function\nNone zero\nLASSO (L_1 penalty) abs\nRidge (L_2 penalty) abs2\nElastic Net OnlineStats.ElasticNet","category":"page"},{"location":"stats_and_models/#Optimization-Algorithms","page":"Statistics and Models","title":"Optimization Algorithms","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Algorithm Constructor\nStochastic Gradient Descent SGD\nRMSProp RMSPROP\nAdaGrad ADAGRAD\nAdaDelta ADADELTA\nADAM ADAM\nADAMax ADAMAX\nMSPI (Majorized Stochastic Proximal Iteration) MSPI\nOnline Majorization-Minimization (MM) - averaged surrogate OMAS\nOnline MM - Averaged Parameter OMAP","category":"page"},{"location":"demos/#Demos","page":"Demos","title":"Demos","text":"","category":"section"},{"location":"demos/","page":"Demos","title":"Demos","text":"A collection of jupyter notebooks are hosted at https://github.com/joshday/OnlineStatsDemos. ","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"import Random\nusing Dates\nusing OnlineStats\nusing Plots\ngr(size=(816,400), margin=6Plots.mm)\nRandom.seed!(1234)","category":"page"},{"location":"dataviz/#Data-Visualization","page":"Data Visualization","title":"Data Visualization","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"note: Note\nEach of the following examples plots one million data points, but can scale to infinitely many observations, since only a summary (OnlineStat) of the data is plotted.","category":"page"},{"location":"dataviz/#Partitions","page":"Data Visualization","title":"Partitions","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"The Partition type summarizes sections of a data stream using any OnlineStat, and is therefore extremely useful in visualizing huge datasets, as summaries are plotted rather than every single observation.","category":"page"},{"location":"dataviz/#Continuous-Data","page":"Data Visualization","title":"Continuous Data","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"y = cumsum(randn(10^6)) + 100randn(10^6)\n\no = Partition(KHist(10))\n\nfit!(o, y)\n\nplot(o)","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"o = Partition(Series(Mean(), Extrema()))\n\nfit!(o, y)\n\nplot(o)","category":"page"},{"location":"dataviz/#Categorical-Data","page":"Data Visualization","title":"Categorical Data","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"y = rand([\"a\", \"a\", \"b\", \"c\"], 10^6)\n\no = Partition(CountMap(String), 75)\n\nfit!(o, y)\n\nplot(o)","category":"page"},{"location":"dataviz/#Indexed-Partitions","page":"Data Visualization","title":"Indexed Partitions","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"The Partition type can only track the number of observations in the x-axis. If you wish to plot one variable against another, you can use an IndexedPartition.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"x = randn(10^6)\ny = x + randn(10^6)\n\no = fit!(IndexedPartition(Float64, KHist(40), 40), zip(x, y))\n\nplot(o)","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"x = rand(10^6)\ny = rand(1:5, 10^6)\n\no = fit!(IndexedPartition(Float64, CountMap(Int)), zip(x,y))\n\nplot(o, xlab = \"X\", ylab = \"Y\")","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"Due to a limitation with Plots.jl, Date and DateTime will sometimes be converted to their Dates.value when plotted. To get human-readable tick labels, you can use the xformatter keyword argument to plot.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"using Dates\n\nx = rand(Date(2019):Day(1):Date(2020), 10^6)\ny = Dates.value.(x) .+ 30randn(10^6)\n\no = fit!(IndexedPartition(Date, KHist(20)), zip(x,y))\n\nplot(o, xformatter = x -> string(Date(Dates.UTInstant(Day(x)))))","category":"page"},{"location":"dataviz/#K-Indexed-Partitions","page":"Data Visualization","title":"K-Indexed Partitions","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"A KIndexedPartition is simlar to an IndexedPartition, but uses a different method of binning the x variable (centroids vs. intervals), similar to that of KHist.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"For the sake of performance, you must provide a function that creates the OnlineStat you wish to calculate for the y variable.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"x = randn(10^6)\ny = x + randn(10^6)\n\no = fit!(KIndexedPartition(Float64, () -> KHist(20)), zip(x, y))\n\nplot(o)","category":"page"},{"location":"dataviz/#Histograms","page":"Data Visualization","title":"Histograms","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"s = fit!(Series(KHist(25), Hist(-5:.2:5), ExpandingHist(100)), randn(10^6))\nplot(s, link = :x, label = [\"KHist\" \"Hist\" \"ExpandingHist\"])","category":"page"},{"location":"dataviz/#Average-Shifted-Histograms-(ASH)","page":"Data Visualization","title":"Average Shifted Histograms (ASH)","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"ASH is a semi-parametric density estimation method that is similar to Kernel Density Estimation, but uses a fine partition histogram instead of individual observations to perform the smoothing.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"o = fit!(Ash(ExpandingHist(1000), 5), randn(10^6))\nplot(o)","category":"page"},{"location":"dataviz/#Approximate-CDF","page":"Data Visualization","title":"Approximate CDF","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"o = fit!(OrderStats(1000), randn(10^6))\n\nplot(o)","category":"page"},{"location":"dataviz/#Mosaic-Plots","page":"Data Visualization","title":"Mosaic Plots","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"The Mosaic type allows you to plot the relationship between two categorical variables. It is typically more useful than a bar plot, as class probabilities are given by the horizontal widths.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"using RDatasets\nt = dataset(\"ggplot2\", \"diamonds\")\n\no = Mosaic(eltype(t.Cut), eltype(t.Color))\n\nfit!(o, zip(t.Cut, t.Color))\n\nplot(o, legendtitle=\"Color\", xlabel=\"Cut\")","category":"page"},{"location":"dataviz/#HeatMap","page":"Data Visualization","title":"HeatMap","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"o = HeatMap(-5:.1:5, -0:.1:10)\n\nx, y = randn(10^6), 5 .+ randn(10^6)\n\nfit!(o, zip(x, y))\n\nplot(o)","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"plot(o, marginals=false, legend=true)","category":"page"},{"location":"dataviz/#Traces","page":"Data Visualization","title":"Traces","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"A Trace will take snapshots of an OnlineStat as it is fitted, allowing you view how the value changed as observations were added. This can be useful for identifying concept drift or finding optimal hyperparameters for stochastic approximation methods like StatLearn.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"y = range(1, 20, length=10^6) .* randn(10^6)\n\no = Trace(Extrema())\n\nfit!(o, y)\n\nplot(o)","category":"page"},{"location":"dataviz/#Naive-Bayes-Classifier","page":"Data Visualization","title":"Naive Bayes Classifier","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"The NBClassifier type stores conditional histograms of the predictor variables, allowing you to plot approximate \"group by\" distributions:","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"# make data\nx = randn(10^6, 5)\ny = x * [1,3,5,7,9] .> 0\n\no = NBClassifier(5, Bool) # 5 predictors with Boolean categories\nfit!(o, zip(eachrow(x), y))\nplot(o)","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"ENV[\"GKSwstype\"] = \"100\"\nENV[\"GKS_ENCODING\"]=\"utf8\"","category":"page"},{"location":"bigdata/#Big-Data","page":"Big Data","title":"Big Data","text":"","category":"section"},{"location":"bigdata/#OnlineStats-CSV","page":"Big Data","title":"OnlineStats + CSV","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"The CSV package offers a very memory-efficient way of iterating through the rows of a (possibly larger-than-memory) CSV file.","category":"page"},{"location":"bigdata/#Example","page":"Big Data","title":"Example","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"Here is a toy example (Iris dataset) of how to iterate through the rows of a CSV file one-by-one and calculate histograms grouped by another variable.","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"using OnlineStats, CSV, Plots\n\nurl = \"https://gist.githubusercontent.com/joshday/df7bdaa1d58b398592e7656395de6335/raw/5a1c83f498f8ca7e25ff2372340e44b3389be9b1/iris.csv\"\n\nrows = CSV.Rows(download(url); reusebuffer = true)\n\nitr = (string(row.variety) => parse(Float64, row.sepal_length) for row in rows)\n\no = GroupBy(String, Hist(4:0.25:8))\n\nfit!(o, itr)\n\nplot(o, layout=(3,1))","category":"page"},{"location":"bigdata/#Threaded-Parallelism","page":"Big Data","title":"Threaded Parallelism","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"The ThreadsX package offers multithreaded implementations of many functions in Base and supports OnlineStats via ThreadsX.reduce(::OnlineStat, data).","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"See \"A quick introduction to data parallelism in Julia\" by ThreadsX author Takafumi Arakaki (@tkf) for more details.","category":"page"},{"location":"bigdata/#Distributed-Parallelism","page":"Big Data","title":"Distributed Parallelism","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"OnlineStats can be merged together to facilitate Embarassingly parallel computations.","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"note: Note\nIn general, fit! is a cheaper operation than merge!.","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"warn: Warn\nNot every OnlineStat can be merged. In these cases, OnlineStats either uses an approximation or provides a warning that no merging occurred.","category":"page"},{"location":"bigdata/#Examples","page":"Big Data","title":"Examples","text":"","category":"section"},{"location":"bigdata/#Simplified-(Not-Actually-in-Parallel)","page":"Big Data","title":"Simplified (Not Actually in Parallel)","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"y1 = randn(10_000)\ny2 = randn(10_000)\ny3 = randn(10_000)\n\na = Series(Mean(), Variance(), KHist(20))\nb = Series(Mean(), Variance(), KHist(20))\nc = Series(Mean(), Variance(), KHist(20))\n\nfit!(a, y1)\nfit!(b, y2)\nfit!(c, y3)\n\nmerge!(a, b) # merge `b` into `a`\nmerge!(a, c) # merge `c` into `a`","category":"page"},{"location":"bigdata/#In-Parallel","page":"Big Data","title":"In Parallel","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"using Distributed\naddprocs(3)\n@everywhere using OnlineStats\n\ns = @distributed merge for i in 1:3\n o = Series(Mean(), Variance(), KHist(20))\n fit!(o, randn(10_000))\nend","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"
","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"using OnlineStats","category":"page"},{"location":"howfitworks/#Details-of-Updating-(fit!)","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"","category":"section"},{"location":"howfitworks/#Core-Principles","page":"Details of Updating (fit!)","title":"Core Principles","text":"","category":"section"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"Stats are subtypes of OnlineStat{T} where T is the type of a single observation.\nE.g. Mean <: OnlineStat{Number}\nfit!(o::OnlineStat{T}, data::T)\nUpdate o with the single observation data.\nfit!(o::OnlineStat{T}, data::S)\nIterate through data and fit! each item.","category":"page"},{"location":"howfitworks/#Why-is-Fitting-Based-on-Iteration?","page":"Details of Updating (fit!)","title":"Why is Fitting Based on Iteration?","text":"","category":"section"},{"location":"howfitworks/#Reason-1:-OnlineStats-doesn't-make-assumptions-on-the-shape-of-your-data","page":"Details of Updating (fit!)","title":"Reason 1: OnlineStats doesn't make assumptions on the shape of your data","text":"","category":"section"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"Consider CovMatrix, for which a single observation is an AbstractVector, Tuple, or NamedTuple. If I try to fit! it with a Matrix, it's ambiguous whether I want rows or columns of the matrix to be treated as individual observations.","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"note: Note\nSee eachrow and eachcol (after typing using LinearAlgebra).","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"x = randn(1000, 2)\n\nfit!(CovMatrix(), eachrow(x))\n\nfit!(CovMatrix(), eachcol(x'))","category":"page"},{"location":"howfitworks/#Reason-2:-OnlineStats-works-out-of-the-box-with-many-data-structures","page":"Details of Updating (fit!)","title":"Reason 2: OnlineStats works out-of-the-box with many data structures","text":"","category":"section"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"Tabular data structures such as those in JuliaDB iterate over named tuples of rows, so things like this just work:","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"using JuliaDB\n\nt = table(randn(100), randn(100))\n\nfit!(2Mean(), t)","category":"page"},{"location":"howfitworks/#A-Common-Error","page":"Details of Updating (fit!)","title":"A Common Error","text":"","category":"section"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"Consider the following example:","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"fit!(Mean(), \"asdf\")","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"This causes an error because:","category":"page"},{"location":"howfitworks/","page":"Details of Updating (fit!)","title":"Details of Updating (fit!)","text":"\"asdf\" is not a Number, so OnlineStats attempts to iterate through it\nIterating through \"asdf\" begins with the character 'a'","category":"page"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"ENV[\"GKSwstype\"] = \"100\"\nENV[\"GKS_ENCODING\"]=\"utf8\"","category":"page"},{"location":"stats_and_models/#Statistics-and-Models","page":"Statistics and Models","title":"Statistics and Models","text":"","category":"section"},{"location":"stats_and_models/#Univariate-Statistics","page":"Statistics and Models","title":"Univariate Statistics","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic OnlineStat\nMean Mean\nVariance Variance\nQuantiles Quantile, OrderStats, and P2Quantile\nMaximum/Minimum Extrema\nSkewness and kurtosis Moments\nSum Sum\nGeometric Mean GeometricMean","category":"page"},{"location":"stats_and_models/#Plotting-(See-[Data-Visualization](@ref))","page":"Statistics and Models","title":"Plotting (See Data Visualization)","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"info: Info\nMany OnlineStats have Plot recipes beyond what is listed here.","category":"page"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Plot OnlineStat\nBig Data Viz Partition, IndexedPartition, KIndexedPartition\nMosaic Plot Mosaic\nHeatMap HeatMap","category":"page"},{"location":"stats_and_models/#Time-Series","page":"Statistics and Models","title":"Time Series","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic OnlineStat\nDifference Diff\nLag Lag\nAutocorrelation/autocovariance AutoCov\nTracked history Trace, StatLag","category":"page"},{"location":"stats_and_models/#Multivariate-Analysis","page":"Statistics and Models","title":"Multivariate Analysis","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic/Model OnlineStat\nCovariance/correlation matrix CovMatrix\nPrincipal components analysis CovMatrix, CCIPCA\nK-means clustering KMeans\nMultiple univariate statistics Group","category":"page"},{"location":"stats_and_models/#Nonparametric-Density-Estimation","page":"Statistics and Models","title":"Nonparametric Density Estimation","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic/Model OnlineStat\nHistograms/continuous density Hist, KHist, and ExpandingHist\nASH density (semiparametric, similar to KDE) Ash\nApproximate order statistics OrderStats\nCount for each unique value CountMap\nApproximate CDF OrderStats","category":"page"},{"location":"stats_and_models/#Parametric-Density-Estimation","page":"Statistics and Models","title":"Parametric Density Estimation","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Distribution OnlineStat\nBeta FitBeta\nCauchy FitCauchy\nGamma FitGamma\nLogNormal FitLogNormal\nNormal FitNormal\nMultinomial FitMultinomial\nMvNormal FitMvNormal","category":"page"},{"location":"stats_and_models/#Machine/Statistical-Learning","page":"Statistics and Models","title":"Machine/Statistical Learning","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Model OnlineStat\nLinear (also ridge) regression LinReg, LinRegBuilder\nDecision Trees FastTree\nRandom Forest FastForest\nNaive Bayes Classifier NBClassifier\nML via Stochastic Approximation StatLearn","category":"page"},{"location":"stats_and_models/#Other","page":"Statistics and Models","title":"Other","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic/Model OnlineStat\nHandling Missing Data FilterTransform, CountMissing, SkipMissing\nStatistical Bootstrap Bootstrap\nApprox. count of distinct elements HyperLogLog\nApprox. count of occurrences CountMinSketch\nRandom sample ReservoirSample\nMoving Window MovingWindow, MovingTimeWindow","category":"page"},{"location":"stats_and_models/#Collection-of-Stats","page":"Statistics and Models","title":"Collection of Stats","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Statistic/Model OnlineStat\nUnivariate data stream Series\nMultivariate data streams Group\nGroup by categorical variable GroupBy","category":"page"},{"location":"stats_and_models/#Stochastic-Approximation-with-[StatLearn](@ref)","page":"Statistics and Models","title":"Stochastic Approximation with StatLearn","text":"","category":"section"},{"location":"stats_and_models/#Regression-and-Classification-Losses","page":"Statistics and Models","title":"Regression and Classification Losses","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Loss Function\nL_2 Loss (squared error) OnlineStats.l2regloss\nL_1 Loss (absolute error) OnlineStats.l1regloss\nLogistic Loss OnlineStats.logisticloss\nL_1 Hinge Loss OnlineStats.l1hingeloss\nGeneralized distance weighted discrimination OnlineStats.DWDLoss","category":"page"},{"location":"stats_and_models/#Penalty/regularization-functions","page":"Statistics and Models","title":"Penalty/regularization functions","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Penalty Function\nNone zero\nLASSO (L_1 penalty) abs\nRidge (L_2 penalty) abs2\nElastic Net OnlineStats.ElasticNet","category":"page"},{"location":"stats_and_models/#Optimization-Algorithms","page":"Statistics and Models","title":"Optimization Algorithms","text":"","category":"section"},{"location":"stats_and_models/","page":"Statistics and Models","title":"Statistics and Models","text":"Algorithm Constructor\nStochastic Gradient Descent SGD\nRMSProp RMSPROP\nAdaGrad ADAGRAD\nAdaDelta ADADELTA\nADAM ADAM\nADAMax ADAMAX\nMSPI (Majorized Stochastic Proximal Iteration) MSPI\nOnline Majorization-Minimization (MM) - averaged surrogate OMAS\nOnline MM - Averaged Parameter OMAP","category":"page"},{"location":"demos/#Demos","page":"Demos","title":"Demos","text":"","category":"section"},{"location":"demos/","page":"Demos","title":"Demos","text":"A collection of jupyter notebooks are hosted at https://github.com/joshday/OnlineStatsDemos. ","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"import Random\nusing Dates\nusing OnlineStats\nusing Plots\ngr(size=(816,400), margin=6Plots.mm)\nRandom.seed!(1234)","category":"page"},{"location":"dataviz/#Data-Visualization","page":"Data Visualization","title":"Data Visualization","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"note: Note\nEach of the following examples plots one million data points, but can scale to infinitely many observations, since only a summary (OnlineStat) of the data is plotted.","category":"page"},{"location":"dataviz/#Partitions","page":"Data Visualization","title":"Partitions","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"The Partition type summarizes sections of a data stream using any OnlineStat, and is therefore extremely useful in visualizing huge datasets, as summaries are plotted rather than every single observation.","category":"page"},{"location":"dataviz/#Continuous-Data","page":"Data Visualization","title":"Continuous Data","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"y = cumsum(randn(10^6)) + 100randn(10^6)\n\no = Partition(KHist(10))\n\nfit!(o, y)\n\nplot(o)","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"o = Partition(Series(Mean(), Extrema()))\n\nfit!(o, y)\n\nplot(o)","category":"page"},{"location":"dataviz/#Categorical-Data","page":"Data Visualization","title":"Categorical Data","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"y = rand([\"a\", \"a\", \"b\", \"c\"], 10^6)\n\no = Partition(CountMap(String), 75)\n\nfit!(o, y)\n\nplot(o)","category":"page"},{"location":"dataviz/#Indexed-Partitions","page":"Data Visualization","title":"Indexed Partitions","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"The Partition type can only track the number of observations in the x-axis. If you wish to plot one variable against another, you can use an IndexedPartition.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"x = randn(10^6)\ny = x + randn(10^6)\n\no = fit!(IndexedPartition(Float64, KHist(40), 40), zip(x, y))\n\nplot(o)","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"x = rand(10^6)\ny = rand(1:5, 10^6)\n\no = fit!(IndexedPartition(Float64, CountMap(Int)), zip(x,y))\n\nplot(o, xlab = \"X\", ylab = \"Y\")","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"Due to a limitation with Plots.jl, Date and DateTime will sometimes be converted to their Dates.value when plotted. To get human-readable tick labels, you can use the xformatter keyword argument to plot.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"using Dates\n\nx = rand(Date(2019):Day(1):Date(2020), 10^6)\ny = Dates.value.(x) .+ 30randn(10^6)\n\no = fit!(IndexedPartition(Date, KHist(20)), zip(x,y))\n\nplot(o, xformatter = x -> string(Date(Dates.UTInstant(Day(x)))))","category":"page"},{"location":"dataviz/#K-Indexed-Partitions","page":"Data Visualization","title":"K-Indexed Partitions","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"A KIndexedPartition is simlar to an IndexedPartition, but uses a different method of binning the x variable (centroids vs. intervals), similar to that of KHist.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"For the sake of performance, you must provide a function that creates the OnlineStat you wish to calculate for the y variable.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"x = randn(10^6)\ny = x + randn(10^6)\n\no = fit!(KIndexedPartition(Float64, () -> KHist(20)), zip(x, y))\n\nplot(o)","category":"page"},{"location":"dataviz/#Histograms","page":"Data Visualization","title":"Histograms","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"s = fit!(Series(KHist(25), Hist(-5:.2:5), ExpandingHist(100)), randn(10^6))\nplot(s, link = :x, label = [\"KHist\" \"Hist\" \"ExpandingHist\"])","category":"page"},{"location":"dataviz/#Average-Shifted-Histograms-(ASH)","page":"Data Visualization","title":"Average Shifted Histograms (ASH)","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"ASH is a semi-parametric density estimation method that is similar to Kernel Density Estimation, but uses a fine partition histogram instead of individual observations to perform the smoothing.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"o = fit!(Ash(ExpandingHist(1000), 5), randn(10^6))\nplot(o)","category":"page"},{"location":"dataviz/#Approximate-CDF","page":"Data Visualization","title":"Approximate CDF","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"o = fit!(OrderStats(1000), randn(10^6))\n\nplot(o)","category":"page"},{"location":"dataviz/#Mosaic-Plots","page":"Data Visualization","title":"Mosaic Plots","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"The Mosaic type allows you to plot the relationship between two categorical variables. It is typically more useful than a bar plot, as class probabilities are given by the horizontal widths.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"using RDatasets\nt = dataset(\"ggplot2\", \"diamonds\")\n\no = Mosaic(eltype(t.Cut), eltype(t.Color))\n\nfit!(o, zip(t.Cut, t.Color))\n\nplot(o, legendtitle=\"Color\", xlabel=\"Cut\")","category":"page"},{"location":"dataviz/#HeatMap","page":"Data Visualization","title":"HeatMap","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"o = HeatMap(-5:.1:5, -0:.1:10)\n\nx, y = randn(10^6), 5 .+ randn(10^6)\n\nfit!(o, zip(x, y))\n\nplot(o)","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"plot(o, marginals=false, legend=true)","category":"page"},{"location":"dataviz/#Traces","page":"Data Visualization","title":"Traces","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"A Trace will take snapshots of an OnlineStat as it is fitted, allowing you view how the value changed as observations were added. This can be useful for identifying concept drift or finding optimal hyperparameters for stochastic approximation methods like StatLearn.","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"y = range(1, 20, length=10^6) .* randn(10^6)\n\no = Trace(Extrema())\n\nfit!(o, y)\n\nplot(o)","category":"page"},{"location":"dataviz/#Naive-Bayes-Classifier","page":"Data Visualization","title":"Naive Bayes Classifier","text":"","category":"section"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"The NBClassifier type stores conditional histograms of the predictor variables, allowing you to plot approximate \"group by\" distributions:","category":"page"},{"location":"dataviz/","page":"Data Visualization","title":"Data Visualization","text":"# make data\nx = randn(10^6, 5)\ny = x * [1,3,5,7,9] .> 0\n\no = NBClassifier(5, Bool) # 5 predictors with Boolean categories\nfit!(o, zip(eachrow(x), y))\nplot(o)","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"ENV[\"GKSwstype\"] = \"100\"\nENV[\"GKS_ENCODING\"]=\"utf8\"","category":"page"},{"location":"bigdata/#Big-Data","page":"Big Data","title":"Big Data","text":"","category":"section"},{"location":"bigdata/#OnlineStats-CSV","page":"Big Data","title":"OnlineStats + CSV","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"The CSV package offers a very memory-efficient way of iterating through the rows of a (possibly larger-than-memory) CSV file.","category":"page"},{"location":"bigdata/#Example","page":"Big Data","title":"Example","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"Here is a toy example (Iris dataset) of how to iterate through the rows of a CSV file one-by-one and calculate histograms grouped by another variable.","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"using OnlineStats, CSV, Plots\n\nurl = \"https://gist.githubusercontent.com/joshday/df7bdaa1d58b398592e7656395de6335/raw/5a1c83f498f8ca7e25ff2372340e44b3389be9b1/iris.csv\"\n\nrows = CSV.Rows(download(url); reusebuffer = true)\n\nitr = (string(row.variety) => parse(Float64, row.sepal_length) for row in rows)\n\no = GroupBy(String, Hist(4:0.25:8))\n\nfit!(o, itr)\n\nplot(o, layout=(3,1))","category":"page"},{"location":"bigdata/#Threaded-Parallelism","page":"Big Data","title":"Threaded Parallelism","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"The ThreadsX package offers multithreaded implementations of many functions in Base and supports OnlineStats via ThreadsX.reduce(::OnlineStat, data).","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"See \"A quick introduction to data parallelism in Julia\" by ThreadsX author Takafumi Arakaki (@tkf) for more details.","category":"page"},{"location":"bigdata/#Distributed-Parallelism","page":"Big Data","title":"Distributed Parallelism","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"OnlineStats can be merged together to facilitate Embarassingly parallel computations.","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"note: Note\nIn general, fit! is a cheaper operation than merge!.","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"warn: Warn\nNot every OnlineStat can be merged. In these cases, OnlineStats either uses an approximation or provides a warning that no merging occurred.","category":"page"},{"location":"bigdata/#Examples","page":"Big Data","title":"Examples","text":"","category":"section"},{"location":"bigdata/#Simplified-(Not-Actually-in-Parallel)","page":"Big Data","title":"Simplified (Not Actually in Parallel)","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"y1 = randn(10_000)\ny2 = randn(10_000)\ny3 = randn(10_000)\n\na = Series(Mean(), Variance(), KHist(20))\nb = Series(Mean(), Variance(), KHist(20))\nc = Series(Mean(), Variance(), KHist(20))\n\nfit!(a, y1)\nfit!(b, y2)\nfit!(c, y3)\n\nmerge!(a, b) # merge `b` into `a`\nmerge!(a, c) # merge `c` into `a`","category":"page"},{"location":"bigdata/#In-Parallel","page":"Big Data","title":"In Parallel","text":"","category":"section"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":"using Distributed\naddprocs(3)\n@everywhere using OnlineStats\n\ns = @distributed merge for i in 1:3\n o = Series(Mean(), Variance(), KHist(20))\n fit!(o, randn(10_000))\nend","category":"page"},{"location":"bigdata/","page":"Big Data","title":"Big Data","text":" ","category":"page"},{"location":"collections/#Collections-of-Stats","page":"Collections of Stats","title":"Collections of Stats","text":"","category":"section"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"There are a few special OnlineStats that group together other OnlineStats: Series and Group.","category":"page"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"
","category":"page"},{"location":"collections/#Collections-of-Stats","page":"Collections of Stats","title":"Collections of Stats","text":"","category":"section"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"There are a few special OnlineStats that group together other OnlineStats: Series and Group.","category":"page"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":" ","category":"page"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"using OnlineStats","category":"page"},{"location":"collections/#Series","page":"Collections of Stats","title":"Series","text":"","category":"section"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"A Series tracks stats that should be applied to the same data stream.","category":"page"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"y = rand(1000)\n\ns = Series(Mean(), Variance())\n\nfit!(s, y)","category":"page"},{"location":"collections/#Group","page":"Collections of Stats","title":"Group","text":"","category":"section"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"A Group tracks stats that should be applied to different data streams.","category":"page"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"g = Group(Mean(), CountMap(Bool))\n\nitr = zip(randn(100), rand(Bool, 100))\n\nfit!(g, itr)","category":"page"},{"location":"","page":"Welcome!","title":"Welcome!","text":"
","category":"page"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"using OnlineStats","category":"page"},{"location":"collections/#Series","page":"Collections of Stats","title":"Series","text":"","category":"section"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"A Series tracks stats that should be applied to the same data stream.","category":"page"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"y = rand(1000)\n\ns = Series(Mean(), Variance())\n\nfit!(s, y)","category":"page"},{"location":"collections/#Group","page":"Collections of Stats","title":"Group","text":"","category":"section"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"A Group tracks stats that should be applied to different data streams.","category":"page"},{"location":"collections/","page":"Collections of Stats","title":"Collections of Stats","text":"g = Group(Mean(), CountMap(Bool))\n\nitr = zip(randn(100), rand(Bool, 100))\n\nfit!(g, itr)","category":"page"},{"location":"","page":"Welcome!","title":"Welcome!","text":"