Implementation of the paper "Overcoming Exploration in Reinforcement Learning with Demonstrations" Nair et al. over the HER baselines from OpenAI
Note: This repository is a modification of her baselines from OpenAI
There is a vast body of recent research that improves different aspects of RL, and learning from demonstrations has been catching attention in terms of its usage to improve exploration which helps the agent to quickly move to important parts of the state space which is usually large and continuous in most robotics problems. Hindsight Experience Replay (or HER for short), is a technique used with reinforcement learning algorithms that can help learn from failure, and I highly recommend to read this paper before moving ahead with this blog. Also this blog assumes basic understading in Reinforcement learning (off-policy RL algorithms like DQN and DDPG) and Deep Neural Networks.
OpenAI recently released their Baselines implementation of Hindsight Experience Replay along with a set of request for robotics research. This blog points towards my work in progress for the implementation of the paper "Overcoming Exploration in Reinforcement Learning with Demonstrations" Nair et al. which comes under Combine HER with recent advances in RL
In DDPG we maintain 2 separate networks known as the actor and the critic networks. The critic network is trained to estimate the Q value of a particular action given a state, Q(s,a). And the actor network is trained to output a policy that will give required behavior for the task. These action outputs from the actor are used to generate the environment interactions throughout the training with an added normal noise (10% of max action values) while selecting the actions and selecting a completely random action with a probability of 0.1.
In the case of a sparse reward setting, which is usally easier to use when explaining a complex robotics task, there are not many rollouts with positive rewards. Now even in these failed rollouts where no reward was obtained, the agent can transform them into successful ones by assuming that a state it saw in the rollout was the actual goal. Usually HER is used with any off-policy RL algorithm assuming that for every state we can find a goal corresponding to this state.
Think of trying to shoot a football into a goal, in the unsuccessful tries you hit the ball left to the pole and it does not get inside the goal. But now assume that the goal was originally a little left to where it now is, such that this trial would have been successful in that imaginary case! Now this imaginary case does not help you to learn how to hit the ball exactly in the goal, but you do learn how to hit the ball in a case where the goal was a little to the left, all this was possible because we shifted the goal (to an observed state in the rollout) and gave a reward for it.
HER is a good technique that helps the agent to learn from sparse rewards, but trying to solve robotics tasks with such sparse rewards can be very slow and the agent might not ever reach to some states that are important because of the exploration problem. Think of the case of grasping a block with a robotic arm, the probability of taking the grasp action exactly when the arm position is perfectly above the block in a particular orientation is very low. Thus an improvement to HER would be if we could use expert demonstrations provided to the agent in a way to overcome the exploration problem.
Further in this blog you will read about my implementation of the paper "Overcoming Exploration in Reinforcement Learning with Demonstrations" Nair et al. which introduces ways to use demonstartions along with HER in a sparse reward case to overcome the exploration problems and solve some complex robotics tasks!
The above DDPG+HER algorithm works fine, but is fairly slow and requires a lot of time and interations with the environment. The following sections will discuss techniques to use demonstrations from an expert to speed up training and overcome the problem of exploration. We implement 3 techniques as listed below -
First, we maintain a second replay buffer RD where we store our demonstration data in the same format as R. In each minibatch, we draw an extra ND examples from RD to use as off-policy replay data for the update step. These examples are included in both the actor and critic update.
{% gist bf6f7b5695826fa909aa0bcd85e67e9f %}
Second, we introduce a new loss computed only on the demonstration examples for training the actor-
This loss is a standard loss in imitation learning, but we show that using it as an auxiliary loss for RL improves learning significantly. The gradient applied to the actor parameters is:
(Note that we maximize J and minimize LBC). Where J is the primary loss on the actor parameters given by
Using this total loss directly prevents the learned policy from improving significantly beyond the demonstration policy, as the actor is always tied back to the demonstrations.
Please read the paper to go through the meaning of the symbols used in these equations
We account for the possibility that demonstrations can be suboptimal by applying the behavior cloning loss only to states where the critic Q(s,a) determines that the demonstrator action is better than the actor action. In python this looks like:
{% gist 3cbe9d3eed4695cd8c0e460d58b7a914 %}
Here, we first mask the samples such as to get the cloning loss only on the demonstration samples by using the tf.boolean_mask function. We have 3 types of losses depending on the chosen run-paramters. When using both behavior cloning loss with Q_Filter we create another mask that enables us to apply the behavior cloning loss to only those states where the critic Q(s,a) determines that the demonstrator action is better than the actor action.
In this repository I integrated the barret WAM Gazebo simulation with OpenAI gym with the help of Gym-gazebo, thus the simulation environment in gazebo can now be used as a stanalone gym environment with all the functionalities. The plan is to first learn the initial policy on a simulation and then transfer it to the real robot, exploration in RL can lead to wild actions which are not feasible when working with a physical platform. But currently the whole simulation environment for Barret WAM arm developed at Perception and Manipulation group, IRI is not available in open source, thus I will be reporting the results on Fetch Robotics environments available from OpenAI gym.
I'm solving different tasks in two different environments:
- Fetch robotic environments from OpenAI gym
- Barret WAM simulation in Gazebo integrated with gym.
The learning algorithm is agnostic of the simulation environment used. With the help of Gym-gazebo, the simulation environment in gazebo can be used as a stanalone gym environment with all the gym functionalities.
The type of tasks I am considering for now (in Barret WAM) are -
- Learning Inverse Kinemantics (learning how to reach a particular point inside the workspace)
- Learning to grasp a block and take it to a given goal inside the workspace
- Learning to stack a block on top of another block
- Learning to stack 4 blocks on top of each other
For the Fetch robotic environments -
- Reaching
- Pick and Place
- Push (Difficult to generate demonstrations without VR module)
Note: All of these tasks have a sparse reward structure i.e. 0 if the task is complete else a -1.
Currently I am using simple python scripts to generate demonstrations with the help of Inverse IK and Forward IK functionalities already in place for the robot I am using. Thus not all the generated demonstrations are perfect, which is good as our algorithm uses a Q-filter which accounts for all the bad demonstration data. The video below shows the demonstration generating paradigm for one block stacking case, where one of the blocks is already at its goal position and the task involves stacking the second block on top of this block, the goal positions are shown in red in the rviz window next to gazebo (it is way easier to have markers in rviz than gazebo). When the block reaches its goal position the marker turns green.
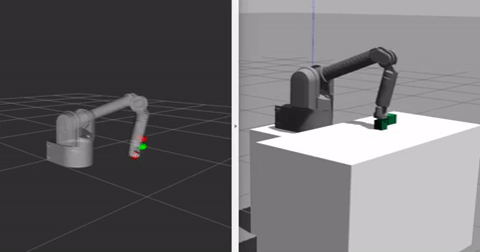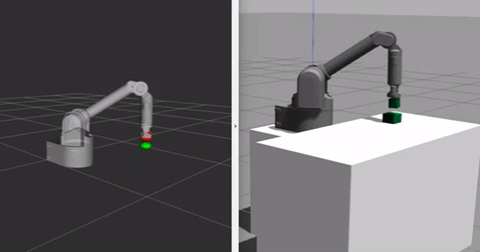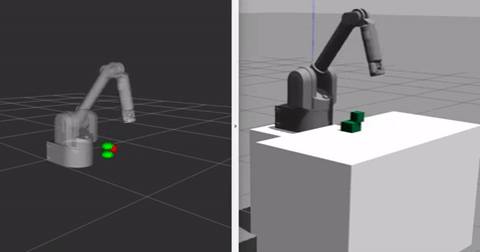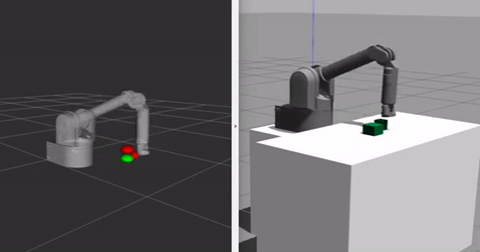

We train the robot with the above shown demonstrations in the buffer. We sample a total of 100 demonstrations/rollouts and in every minibatch sample ND = 128 samples from the demonstrations in a total of N = 1024 samples, the rest of the samples are generated when the arm interacts with the environment. To train the model we use Adam optimizer with learning rate 0.001 for both critic and actor networks. The discount factor is 0.98. To explore during training, we sample random actions uniformly within the action space with a probability of 0.1 at every step, with an additional uniform gaussian noise which is 10% of the maximum value of each action dimension. For details about more hyperparameters, refer to config.py in the source code. Both the environments are trained with the same set of hyperparameters for now in the reported results.
The following video shows the agent's learned behavior corresponding to the task of stacking one block on top of the other. As you can see it learns to pick up the block, reach to a perfect position to drop the block but still does not learn to take the action that results in dropping the block to the goal. As I said this is a work in progress and I am still working towards improving the performace of the agent in this task. For the other easier tasks of reaching a goal position and picking up the block it shows perfect performance, and I have not reported those results as they are just a subset of the current problem which I am trying to solve.

Training with demonstrations helps overcome the exploration problem and achieves a faster and better convergence. The following graphs contrast the difference between training with and without demonstration data, I report the the mean Q values vs Epoch and the Success Rate vs Epoch:

Clearly, the use of demonstrations enables a faster and better convergence in the Q values as apparent from the graphs. Also the success condition is achieved much faster reaching upto 100% performance just around the 400th epoch whereas in the case without demonstrations even after 1000 iterations the agent hardly reaches 70% success rate. Future work in this direction would include solving much more complex tasks and impriving the algorithm further to enable a better and efficient usage of demonstrations data.
Training with demonstrations helps overcome the exploration problem and achieves a faster and better convergence. The following graphs contrast the difference between training with and without demonstration data, I report the the mean Q values vs Epoch and the Success Rate vs Epoch:

Clearly, the use of demonstrations enables a faster and better convergence in the Q values as apparent from the graphs. Also the success condition is achieved much faster reaching upto 100% performance just around the 400th epoch whereas in the case without demonstrations even after 1000 iterations the agent hardly reaches 70% success rate. Visit my blog to see the videos. The video shows the agent's learned behavior corresponding to the task of stacking one block on top of the other and other tasks as well.
-
Install Python 3.5 or higher
-
Clone the baselines from OpenAI, use the following commit in case of any conflicts - a6b1bc70f156dc45c0da49be8e80941a88021700
-
Clone this package in your working directory with
git clone https://github.com/jangirrishabh/Overcoming-exploration-from-demos.git -
Add this package to your PYTHONPATH or if you are not familiar with that alternatively edit
sys.path.append('/path/to/Overcoming-exploration-from-demos/')in train.py, play.py and config.py
I'm solving different tasks in two different environments:
- Fetch robotic environments from OpenAI gym
- Barret WAM simulation in Gazebo integrated with gym.
The learning algorithm is agnostic of the simulation environment used. With the help of Gym-gazebo, the simulation environment in gazebo can be used as a stanalone gym environment with all the gym functionalities.
The training paradigm to teach a task to an agent through previously recorded demonstrations involves:
Configure the run parameters at the bottom of the file, select the environment you wish to use by changing the environment name, additional parameters since the her baselines are:
- '--bc_loss', type=int, default=0, help='whether or not to use the behavior cloning loss as an auxilliary loss'
- '--q_filter', type=int, default=0, help='whether or not a Q value filter should be used on the Actor outputs'
- '--num_demo', type=int, default = 0, help='number of expert demo episodes'.
Edit demoFileName = 'your/demo/file' to point to the file that contains your recorded demonstrations
To start the training use python experiment/train.py.
The above training paradigm spits out policies as .pkl files after every 5 epochs (can be modified) which we can then replay and evaluate with this file. To play the policy execute python experiments/play.py /path/to/saved/policy.pkl.
All the training hyperparameters can be configured through this file. Feel free to experiment with different combinations and record results.
Contains the main DDPG algorithm with a modified network where the losses are changed based on the whether demonstrations are provided for the task. Basically we maintain a separate demoBuffer and sample from this as well. Following parameters are to be configured here:
- self.demo_batch_size: Number of demos out of total buffer size (128/1024 default)
- self.lambda1, self.lambda2: Correspond to the weights given for Q loss and Behavior cloning loss respectively
Major contributions of the paper include the following aspects which I have tried to implement over the HER baselines:
First, we maintain a second replay buffer RD where we store our demonstration data in the same format as R. In each minibatch, we draw an extra ND examples from RD to use as off-policy replay data for the update step. These examples are included in both the actor and critic update.
self.demo_batch_size = 128 #Number of demo samples
def initDemoBuffer(self, demoDataFile, update_stats=True):
#To initiaze the demobuffer with the recorded demonstration data. We also normalize the demo data.
def sample_batch(self):
if self.bc_loss:
transitions = self.buffer.sample(self.batch_size - self.demo_batch_size)
global demoBuffer
transitionsDemo = demoBuffer.sample(self.demo_batch_size)
for k, values in transitionsDemo.items():
rolloutV = transitions[k].tolist()
for v in values:
rolloutV.append(v.tolist())
transitions[k] = np.array(rolloutV)
else:
transitions = self.buffer.sample(self.batch_size)Second, we introduce a new loss computed only on the demonstration examples for training the actor. This loss is a standard loss in imitation learning, but we show that using it as an auxiliary loss for RL improves learning significantly. The loss implementation can be seen in the following code. Refer to the blog for more information on equations.
We account for the possibility that demonstrations can be suboptimal by applying the behavior cloning loss only to states where the critic Q(s,a) determines that the demonstrator action is better than the actor action. In python this looks like:
self.lambda1 = 0.001
self.lambda2 = 0.0078
def _create_network(self, reuse=False):
mask = np.concatenate((np.zeros(self.batch_size - self.demo_batch_size), np.ones(self.demo_batch_size)), axis = 0)
target_Q_pi_tf = self.target.Q_pi_tf
clip_range = (-self.clip_return, 0. if self.clip_pos_returns else np.inf)
target_tf = tf.clip_by_value(batch_tf['r'] + self.gamma * target_Q_pi_tf, *clip_range) # y = r + gamma*Q(pi)
self.Q_loss_tf = tf.reduce_mean(tf.square(tf.stop_gradient(target_tf) - self.main.Q_tf)) #(y-Q(critic))^2
if self.bc_loss ==1 and self.q_filter == 1 :
maskMain = tf.reshape(tf.boolean_mask(self.main.Q_tf > self.main.Q_pi_tf, mask), [-1]) #where is the demonstrator action better than actor action according to the critic?
self.cloning_loss_tf = tf.reduce_sum(tf.square(tf.boolean_mask(tf.boolean_mask((self.main.pi_tf), mask), maskMain, axis=0) - tf.boolean_mask(tf.boolean_mask((batch_tf['u']), mask), maskMain, axis=0)))
self.pi_loss_tf = -self.lambda1 * tf.reduce_mean(self.main.Q_pi_tf)
self.pi_loss_tf += self.lambda1 * self.action_l2 * tf.reduce_mean(tf.square(self.main.pi_tf / self.max_u))
self.pi_loss_tf += self.lambda2 * self.cloning_loss_tf
elif self.bc_loss == 1 and self.q_filter == 0:
self.cloning_loss_tf = tf.reduce_sum(tf.square(tf.boolean_mask((self.main.pi_tf), mask) - tf.boolean_mask((batch_tf['u']), mask)))
self.pi_loss_tf = -self.lambda1 * tf.reduce_mean(self.main.Q_pi_tf)
self.pi_loss_tf += self.lambda1 * self.action_l2 * tf.reduce_mean(tf.square(self.main.pi_tf / self.max_u))
self.pi_loss_tf += self.lambda2 * self.cloning_loss_tf
else:
self.pi_loss_tf = -tf.reduce_mean(self.main.Q_pi_tf)
self.pi_loss_tf += self.action_l2 * tf.reduce_mean(tf.square(self.main.pi_tf / self.max_u))
self.cloning_loss_tf = tf.reduce_sum(tf.square(self.main.pi_tf - batch_tf['u'])) #random valuesHere, we first mask the samples such as to get the cloning loss only on the demonstration samples by using the tf.boolean_mask function. We have 3 types of losses depending on the chosen run-paramters. When using both behavior cloning loss with Q_Filter we create another mask that enables us to apply the behavior cloning loss to only those states where the critic Q(s,a) determines that the demonstrator action is better than the actor action.