SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
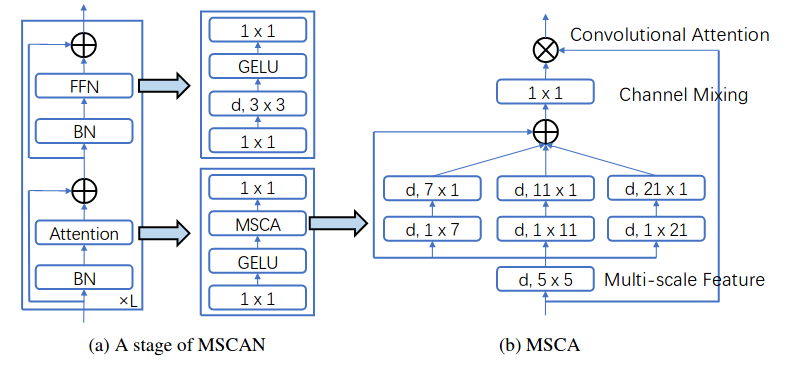
We present SegNeXt, a simple convolutional network architecture for semantic segmentation. Recent transformer-based models have dominated the field of semantic segmentation due to the efficiency of self-attention in encoding spatial information. In this paper, we show that convolutional attention is a more efficient and effective way to encode contextual information than the self-attention mechanism in transformers. By re-examining the characteristics owned by successful segmentation models, we discover several key components leading to the performance improvement of segmentation models. This motivates us to design a novel convolutional attention network that uses cheap convolutional operations. Without bells and whistles, our SegNeXt significantly improves the performance of previous state-of-the-art methods on popular benchmarks, including ADE20K, Cityscapes, COCO-Stuff, Pascal VOC, Pascal Context, and iSAID. Notably, SegNeXt outperforms EfficientNet-L2 w/ NAS-FPN and achieves 90.6% mIoU on the Pascal VOC 2012 test leaderboard using only 1/10 parameters of it. On average, SegNeXt achieves about 2.0% mIoU improvements compared to the state-of-the-art methods on the ADE20K datasets with the same or fewer computations. Code is available at this https URL (Jittor) and this https URL (Pytorch).
@article{guo2022segnext,
title={SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation},
author={Guo, Meng-Hao and Lu, Cheng-Ze and Hou, Qibin and Liu, Zhengning and Cheng, Ming-Ming and Hu, Shi-Min},
journal={arXiv preprint arXiv:2209.08575},
year={2022}
}| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| SegNeXt | MSCAN-T | 512x512 | 160000 | 17.88 | 52.38 | 41.50 | 42.59 | config | model | log |
| SegNeXt | MSCAN-S | 512x512 | 160000 | 21.47 | 42.27 | 44.16 | 45.81 | config | model | log |
| SegNeXt | MSCAN-B | 512x512 | 160000 | 31.03 | 35.15 | 48.03 | 49.68 | config | model | log |
| SegNeXt | MSCAN-L | 512x512 | 160000 | 43.32 | 22.91 | 50.99 | 52.10 | config | model | log |
Note:
-
When we integrated SegNeXt into MMSegmentation, we modified some layers' names to make them more precise and concise without changing the model architecture. Therefore, the keys of pre-trained weights are different from the original weights, but don't worry about these changes. we have converted them and uploaded the checkpoints, you might find URL of pre-trained checkpoints in config files and can use them directly for training.
-
The total batch size is 16. We trained for SegNeXt with a single GPU as the performance degrades significantly when using
SyncBN(mainly inOverlapPatchEmbedmodules ofMSCAN) of PyTorch 1.9. -
There will be subtle differences when model testing as Non-negative Matrix Factorization (NMF) in
LightHamHeadwill be initialized randomly. To control this randomness, please set the random seed when model testing. You can modify./tools/test.pylike:
def main():
from mmseg.apis import set_random_seed
random_seed = xxx # set random seed recorded in training log
set_random_seed(random_seed, deterministic=False)
...- This model performance is sensitive to the seed values used, please refer to the log file for the specific settings of the seed. If you choose a different seed, the results might differ from the table results. Take SegNeXt Large for example, its results range from 49.60 to 51.0.