You can use this file as a template for your writeup if you want to submit it as a markdown file, but feel free to use some other method and submit a pdf if you prefer.
Behavioral Cloning Project
The goals / steps of this project are the following:
- Use the simulator to collect data of good driving behavior
- Build, a convolution neural network in Keras that predicts steering angles from images
- Train and validate the model with a training and validation set
- Test that the model successfully drives around track one without leaving the road
- Summarize the results with a written report
Here I will consider the rubric points individually and describe how I addressed each point in my implementation.
My project includes the following files:
- model.py containing the script to create and train the model
- drive.py for driving the car in autonomous mode
- model.h5 containing a trained convolution neural network
- writeup_report.md or writeup_report.pdf summarizing the results
Using the Udacity provided simulator and my drive.py file, the car can be driven autonomously around the track by executing
python drive.py model.h5The model.py file contains the code for training and saving the convolution neural network. The file shows the pipeline I used for training and validating the model, and it contains comments to explain how the code works.
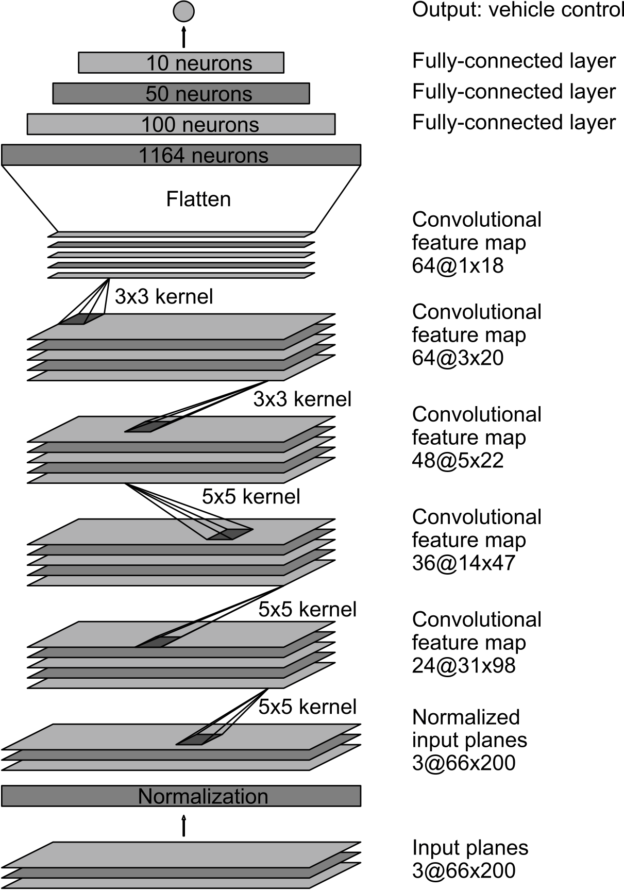
My model consists of a convolution neural network with 3x3 filter sizes and depths between 32 and 64. The model architecture was based on NVIDIA's published paper on end-to-end steering control through deep learning that Udacity provided us with. The model includes ELU layers (activation funcs) to introduce nonlinearity into the convolutional layers, and the data is normalized in the model using a Keras lambda layer.
The model contains dropout layers after each fully connected layer in order to reduce overfitting. The model was trained and validated on different data sets to ensure that the model was not overfitting. The model was tested by running it through the simulator and ensuring that the vehicle could stay on the track.
The model used an adam optimizer, so the learning rate was not tuned manually.
Training data was chosen to keep the vehicle driving on the road. I originally started with the Udacity-provided data, but when I did a "manual exploration" of the data, I found that some of the images had weird (incorrect) angles and probably would throw the model off. So I recorded my own data -- about 3 laps of forward, center-lane driving, around a lap of reverse driving to unbias the network from left steering values, and about 2 laps of recovery driving from the sides. To tune the model, even though this doesn't help the model generalize to other tracks and normal driving, I recorded and added data for certain turns that the model was having trouble with (that right hand turn near the end gave my a lot of trouble). I kept each recording session isolated so that if my keyboard driving produced bad data, I could just re-record that single section or turn. and not have to manually filter through the CSV to remove bad data.
I didn't want to waste any time -- I immediately started with the NVIDIA architecture and got right to it. This model, at first seemed to perform horribly, but then I took a look at the data and saw how heavily biased towards 0 it was; that explained why the model rarely turned. After adding a function to drop out about 90% of the zero steering data, I saw that the NVIDIA model actually performed pretty well. It got through the first turn, but didn't exit properly and drove straight into the lake.
In order to gauge how well the model was working, I split my image and steering angle data into a training and validation set. I found that my first model had a low mean squared error on the training set but a high mean squared error on the validation set, implying an overfitting model. At this point, I aded the dropout layers.
The final step was to run the simulator to see how well the car was driving around track one. There were a few spots where the vehicle fell off the track -- to improve the driving behavior in these cases, I rerecorded these spots and drove aggressively.
The final model architecture was the NVIDIA architecure with added dropout layers.
Here is a visualization of the architecture (note: visualizing the architecture is optional according to the project rubric)
{kind=link}
To capture good driving behavior, I first recorded two laps on track one using center lane driving -- sticking to the middle. I then recorded the vehicle recovering from the left side and right sides of the road back to center so that the vehicle would learn to recover in case it fell off the center. To augment the data sat, I also flipped images and angles with magnitude above 0.33, nearly doubling the dataset.
I randomly shuffled the data set and put 10% of the data into a validation set.
I used this training data for training the model. The validation set helped determine if the model was over or under fitting. I used 1 epoch while testing and when I was satisfied with results, trained the model with 3 epochs; I read on the cheatsheet provided that three to five epochs was more than enough to get good results.
I'd like to revisit this project and try to achieve better performance on the challenge jungle track. It didn't do too well when I tried it and I assume this is primarily because the model is relatively biased towards the track one data after I trained it. I'd need to add data from track 2, especially seeing that it's a multi-lane road with more curves and elevation differences, and a various different scenes/backgrounds.