Intel Optane 900P performance
I wanted to see what kind of performance I could achieve with Tupl on the new Optane 900P SSD. Just like the earlier tests, this one inserted random keys into a new Tupl database, as quickly as possible, with no transactions.
- Key: 8 bytes
- Value: 0 bytes
- RAM: 16GB
- Storage: Intel Optane SSD 900P 480GB
- CPU: Ryzen 7 1700
- Kernel: 4.10.0-38
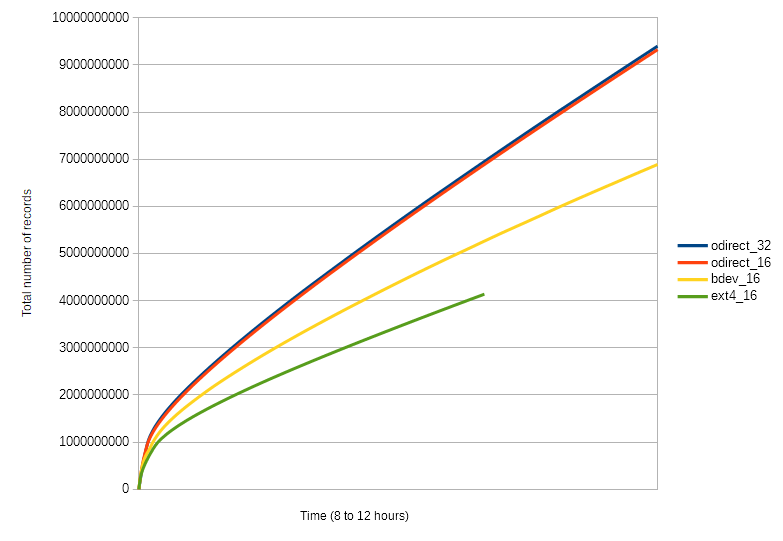
The graph shows four test runs:
- odirect_32: Block device opened with O_DIRECT, 32 threads (12 hours)
- odirect_16: Block device opened with O_DIRECT, 16 threads (12 hours)
- bdev_16: Block device opened normally, 16 threads (12 hours)
- ext4_16: EXT4 file system, 16 threads (8 hours)
As can be seen, the best performance is achieved when the database is written to a raw block device, using direct I/O. When using the file system or block device with the regular open option, the primary bottleneck is the kernel. In particular, a lot of CPU time is spent in the kworker and kswapd processes. It should be noted that no actual page swapping occurred, so I don't know what kswapd is doing. When using a NAND-flash SSD, the overhead of these kernel processes doesn't affect the test results, although a real application would benefit from lower CPU load.
The maximum raw performance (not using Tupl) I was able to get with the Optane SSD was 550K read/write operations per second, where each was 4KiB in size. When RAM is exhausted, each insert into a Tupl database requires at least one read and one write operation. So the best sustained throughput well into the test should be about 275K inserts per second. The actual observed rate at around 6 hours was about 180K inserts per second. Some of this overhead is due to contention introduced by Tupl, perhaps when accessing the free list. Contention could be reduced by striping the free list, or by accessing it in batches. A higher thread count of 32 only improves throughput slightly, which further suggests that contention is the issue. An application which is inserting larger records might experience less contention, and so the throughout would be higher.
The primary reason why performance is lower than expected is actually due to rebalancing. Before a b-tree node splits due to an insert, an attempt is made to shift some elements to a neighboring node. This reduces the number of splits, and in turn reduces the overall storage overhead. The rebalancing activity reads and writes more nodes from the storage device than would otherwise be expected. A workload which is mostly doing updates should see higher performance. Here's a relatively boring chart which demonstrates this:

The database was pre-filled with 5.4 billion entries, and then the test updated each of them again as quickly as possible. This took about 5.8 hours to complete, at rate of 258k updates per second. This is much closer to the theoretical maximum rate of 275k. The test continued to run, inserting new entries, which can be seen where the slope of the line changes. The insert rate for the remaining 4.2 hours is about 174k inserts per second. This confirms that inserts are slower than updates.
When running a profiler during the updates, free list management did show up as a hot spot. In particular, appending to the free list to delete pages. Allocation of new pages didn't show up, possibly because the threads first stalled on the deletion and then they were able to acquire the next lock without any contention. Striping the free list should improve performance (multiple PageManagers), but not by much. The bottleneck overall is still the storage device, but a RAM drive would benefit more with this optimization.
When I first ran the tests, I observed strange performance dips. At times, the insert rate would plummet all the way down to zero. I ran a simple test which confirmed that this was due to thermal throttling. The Optane SSD has a large heatsink, and it also requires good airflow. After I cranked up the fan and directed more airflow over the SSD, the throttling problem disappeared.
Earlier tests with the Samsung 960 Pro SSD didn't really show any benefit when using a raw block device instead of a file system. This is because the bottleneck is still the SSD, and any operating system overhead isn't much of an issue. Because the Optane SSD is so fast, the bottleneck shifts away from the hardware, and eliminating overhead is essential for achieving the highest performance. Future Optane drives are expected to have performance closer to DRAM speeds, and so bypassing the operating system will become essential.