Okay,now ,before starting todays class,let's revise Supervised and Unsupervised learning!(from day1.md)
Cells within the nervous system, called neurons, communicate with each other in unique ways. The neuron is the basic working unit of the brain, a specialized cell designed to transmit information to other nerve cells, muscle, or gland cells.
The brain is what it is because of the structural and functional properties of interconnected neurons. The mammalian brain contains between 100 million and 100 billion neurons, depending on the species.


Theres a difference between machine learning and deep learning
Machine learning is a lot of complex math and coding that, at the end of day, serves a mechanical function the same way a flashlight, a car, or a television does. When something is capable of “machine learning”, it means it’s performing a function with the data given to it, and gets progressively better at that function. It’s like if you had a flashlight that turned on whenever you said “it’s dark”, so it would recognize different phrases containing the word “dark”.
Deep learning In practical terms, deep learning is just a subset of machine learning. Let’s go back to the flashlight example: it could be programmed to turn on when it recognizes the audible cue of someone saying the word “dark”. Eventually, it could pick up any phrase containing that word. Now if the flashlight had a deep learning model, it could maybe figure out that it should turn on with the cues “I can’t see” or “the light switch won’t work”. A deep learning model is able to learn through its own method of computing – its own “brain”, if you will.
Perceptron is a linear classifier (binary). Also, it is used in supervised learningBut how does it work?
The perceptron works on these simple steps
a. All the inputs x are multiplied with their weights w. Let’s call it k.

b. Add all the multiplied values and call them Weighted Sum.

c. Apply that weighted sum to the correct Activation Function.
For Example : Unit Step Activation Function.


In a neural network architecure, there is an input layer, some hidden layers and an output Layer.
The weighted outputs from input layer is passed to the input of next layer, and so on, and we will get the predicted output in numerical form at the output layer.
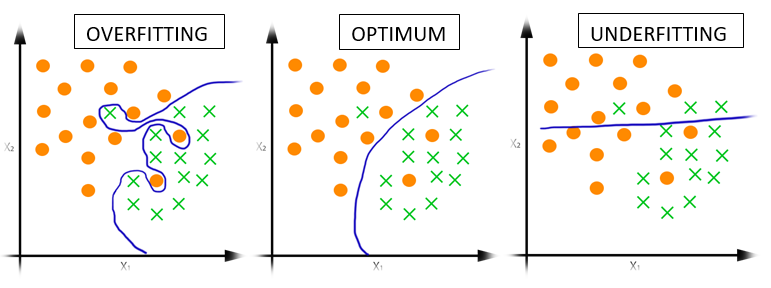
Overfitting is when the trained model memorizes the undesirable patterns or noise from the training data-set. This is due to too much training or learning capacity(too many hidden layers or neurons in each layer). The consequence of overfitting is that, model cannot generalize to samples outside its training set, which overall reduces the performance of the model. To determine whether the model is overfitting, during the training, compare the loss value on the training and testing set. If the loss on the test set is much larger than in the training set, then the model is overfitting, specially if the training loss is low. However, it is also normal that the test loss is slightly larger than training loss.
Click here to read about Feature Engineering
Suppose, we are given a data “flight date time vs status”. Then, given the date-time data, we have to predict the status of the flight.

As the status of the flight depends on the hour of the day, not on the date-time. We will create the new feature “Hour_Of_Day”. Using the “Hour_Of_Day” feature, the machine will learn better as this feature is directly related to the status of the flight.

Read this article about Feature crossing
Read this awesome explanation about One Hot Encoding

This is a form of regression, that constrains/ regularizes or shrinks the coefficient estimates towards zero. In other words, this technique discourages learning a more complex or flexible model, so as to avoid the risk of overfitting.
To model a nonlinear problem, we can directly introduce a nonlinearity. We can pipe each hidden layer node through a nonlinear function.
click to read more about activation functions
- ReLu -Rectified linear units
- Sigmoid or Logistic
- Tanh — Hyperbolic tangent
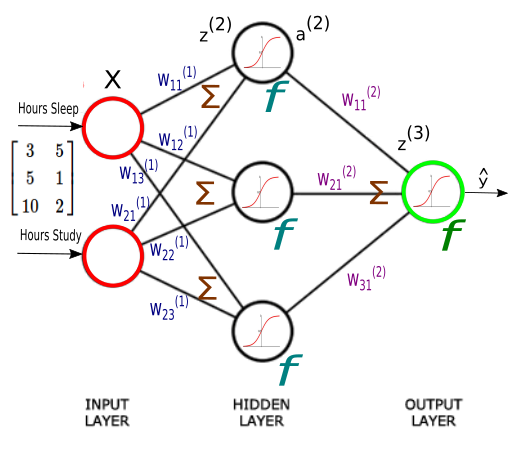
In neural networks, you forward propagate to get the output and compare it with the real value to get the error.
Now, to minimize the error, you propagate backwards by finding the derivative of error with respect to each weight and then subtracting this value from the weight value.
The basic learning that has to be done in neural networks is training neurons when to get activated. Each neuron should activate only for particular type of inputs and not all inputs. Therefore, by propagating forward you see how well your neural network is behaving and find the error. After you find out that your network has error, you back propagate and use a form of gradient descent to update new values of weights. Then, you will again forward propagate to see how well those weights are performing and then will backward propagate to update the weights. This will go on until you reach some minima for error value.
What happens when you try to learn something for an examination? You dont exactly memorise everything as such, right? You create a model inside your head, so that when a question is asked , you can answer accordingly using the model you have inside your head.
The training data must contain the correct answer, which is known as a target or target attribute. The learning algorithm finds patterns in the training data that map the input data attributes to the target (the answer that you want to predict), and it outputs an ML model that captures these patterns.
You can use the ML model to get predictions on new data for which you do not know the target. For example, let's say that you want to train an ML model to predict if an email is spam or not spam. You would provide the network with training data that contains emails for which you know the target (that is, a label that tells whether an email is spam or not spam). The network would train an ML model by using this data, resulting in a model that attempts to predict whether new email will be spam or not spam.