Whisper is a general-purpose speech recognition model from OpenAI. The model is able to almost flawlessly transcribe speech across dozens of languages and even handle poor audio quality or excessive background noise. This notebook will run the model with OpenVINO to generate transcription of a video.
This notebook demonstrates how to generate video subtitles using the open-source Whisper model. Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. It is a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification. You can find more information about this model in the research paper, OpenAI blog, model card and GitHub repository.
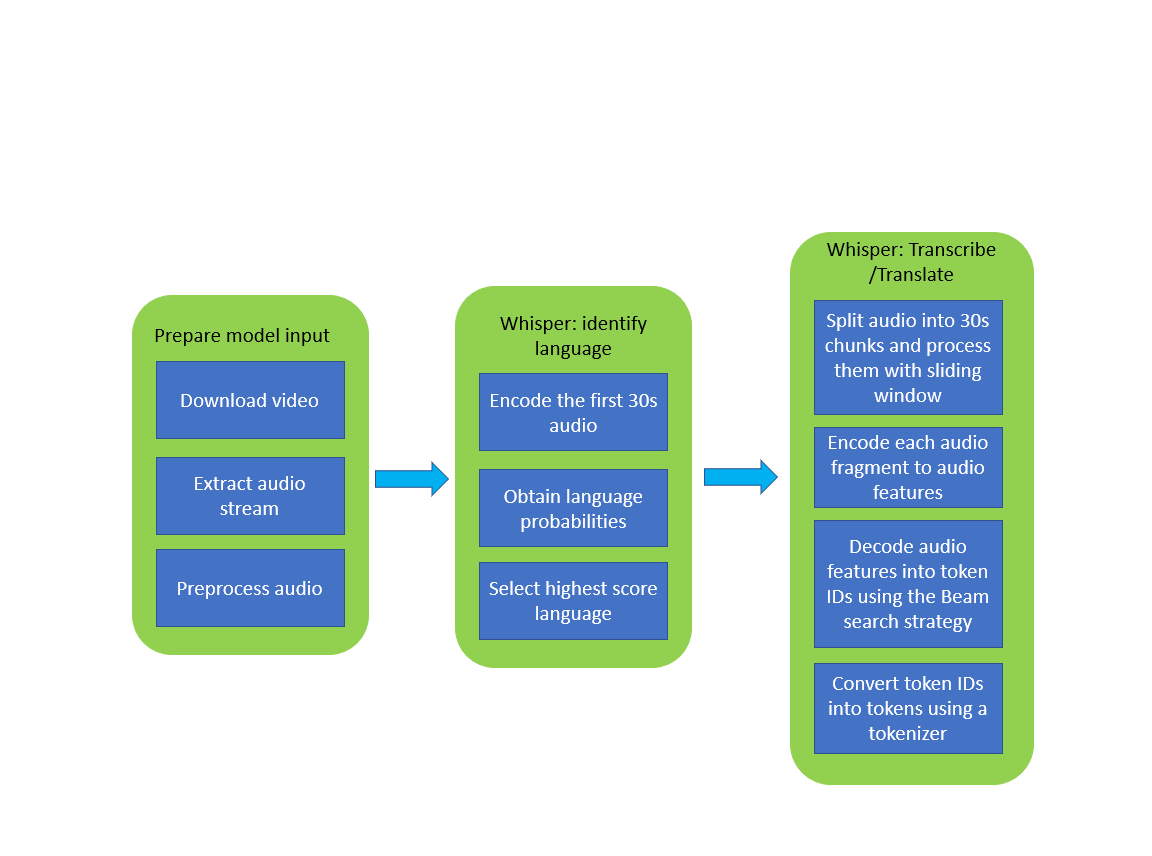
In this notebook, you will use its capabilities for generation of subtitles for a video. Notebook contains the following steps:
- Download the model.
- Instantiate original PyTorch model pipeline.
- Export the ONNX model and convert it to OpenVINO IR, using the Model Optimizer tool.
- Run the Whisper pipeline with OpenVINO.
A simplified demo pipeline is represented in the diagram below:
 The final output of running this notebook is an
The final output of running this notebook is an srt file (popular video captioning format) with subtitles for a sample video downloaded from YouTube.
This file can be integrated with a video player during playback or embedded directly into a video file with ffmpeg or similar tools that support working with subtitles.
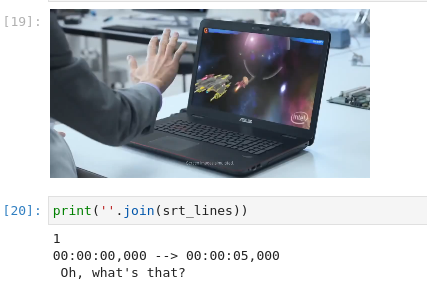
The image below shows an example of the video as input and corresponding transcription as output.
If you have not installed all required dependencies, follow the Installation Guide.