[TOC]
本章主要对数据库进行基本介绍,考虑易用性及普及度,课程主要使用MySQL进行介绍。
数据库是将大量数据保存起来,通过计算机加工而成的可以进行高效访问的数据集合。该数据集合称为数据库(Database,DB)。用来管理数据库的计算机系统称为数据库管理系统(Database Management System,DBMS)。
DBMS 主要通过数据的保存格式(数据库的种类)来进行分类,现阶段主要有以下 5 种类型。
-
层次数据库(Hierarchical Database,HDB)
-
关系数据库(Relational Database,RDB)
这种类型的 DBMS 称为关系数据库管理系统(Relational Database Management System,RDBMS)。比较具有代表性的 RDBMS 有如下 5 种。
- Oracle Database:甲骨文公司的 RDBMS
- SQL Server:微软公司的 RDBMS
- DB2:IBM 公司的 RDBMS
- PostgreSQL:开源的 RDBMS
- MySQL:开源的 RDBMS
-
面向对象数据库(Object Oriented Database,OODB)
-
XML 数据库(XML Database,XMLDB)
-
键值存储系统(Key-Value Store,KVS),举例:MongoDB
本课程将向大家介绍使用 SQL 语言的数据库管理系统,也就是关系数据库管理系统(RDBMS)的操作方法。
使用 RDBMS 时,最常见的系统结构就是客户端 / 服务器类型(C/S 类型)这种结构(如下图)

本次学习大家可以选择使用阿里云数据库服务器或者本地安装数据库进行学习,在下面对应的学习教程中也给告诉了大家如何创建本次学习需要的数据库表和数据,所以大家必须使用一个方式安装数据库,才能完成后面学习。
「Windows10 专业版下安装 Docker.pdf」。 链接:https://www.aliyundrive.com/s/GFqQ8ETaA1E
节约篇幅,具体相关介绍以及给大家写到 pdf 里了,大家点击链接即可进入查看:
优点: 操作使用方便,未来趋势(数据上云),导入、导出数据方便,运行速度快。
缺点: 需要付费购买,不过现在对开发者有优惠活动,基础版本 1 核 1G,存储空间 20G 的,目前优惠价半年只需 9.9 元,一杯奶茶钱不到。 2023 年 01 月 02 日这个优惠已经取消掉了。
节约篇幅,具体相关介绍以及给大家写到 pdf 里了,大家点击链接即可进入查看:
优点: 免费,增强动手能力。
缺点: 安装、配置麻烦,数据导入、导出耗时长。
收集和存储用于分析的数据算一项与人类生活密切相关的活动。几千年前,人类就开始用系统来追踪粮食存储、税收和人口。
现代,商业智能、分析学、数据科学和决策科学在企业中蓬勃发展。
数据分析分析已经开始由市场营销人员、产品经理、业务分析师等各种人员完成。
在企业的经营系统中,数据通常以某种格式被收集且数量也是巨大的;数据分析也正是基于历史数据进行研究的操作。
按照数据生命周期的顺序,我们可以将数据处理划分为以下主要阶段,从数据的产生到最终的应用和管理。数据生命周期中,每个阶段都为下一个阶段的工作奠定基础,确保数据能够有效地支持业务决策。
主要工作内容:
- 数据生成:数据可以来自多种来源,包括传感器、交易系统、社交媒体、API等。
- 数据收集:采集原始数据并存储在临时数据仓库或云端,准备后续处理。
常用工具和方法:
- 工具:requests用于API采集,BeautifulSoup和Scrapy用于网络爬取,pandas用于读取文件数据。
- 方法:数据抓取、日志记录、IoT设备数据采集。
主要工作内容:
- 数据库选择与设计:根据数据量、结构和访问频率,选择合适的数据库系统。
- 数据仓库与数据湖:整合跨系统的数据,创建统一的数据仓库或数据湖。
- 数据备份和恢复:确保数据安全,通过定期备份实现灾难恢复。
常用工具和方法:
- 工具:MySQL、MongoDB、AWS S3、Azure Blob Storage。
- 方法:数据库设计、ETL流程(提取、转换、加载)、数据归档和备份。
主要工作内容:
- 数据整理:对数据进行结构化和分类,确保数据的一致性。
- 数据清洗:处理缺失值、重复值、异常值和数据类型不匹配问题。
- 数据转换:对数据类型进行转换,为后续分析做好准备。
常用工具和方法:
- 工具:pandas、numpy、OpenRefine。
- 方法:缺失值填充、数据标准化、异常值处理。
主要工作内容:
- 数据集成:整合来自不同来源的数据,创建一致的分析数据集。
- 数据转换:对数据进行特征工程,如数据聚合、维度缩放,确保数据符合模型需求。
- 数据结构重组:转化为适合分析的格式,如宽表或多维数组。
常用工具和方法:
- 工具:ETL工具如Apache Nifi、Airflow、pandas、SQL。
- 方法:特征工程、数据透视、数据合并和分组。
主要工作内容:
- 描述性分析:统计数据的特征(如均值、中位数、分布)。
- 探索性数据分析:通过可视化手段,探索数据的模式、相关性和趋势。
- 数据挖掘:使用高级算法发现数据中的深层次关联,如分类、聚类和预测。
常用工具和方法:
- 工具:scikit-learn、matplotlib、seaborn、scipy。
- 方法:描述性统计、假设检验、聚类分析、关联规则挖掘。
主要工作内容:
- 模型选择与训练:选择合适的算法和模型,进行模型训练。
- 模型评估与优化:评估模型性能并进行优化,以提高预测的准确性。
- 预测应用:使用训练好的模型进行预测或模拟未来情景。
常用工具和方法:
- 工具:scikit-learn、TensorFlow、Keras、XGBoost。
- 方法:交叉验证、超参数调优、模型性能评估。
主要工作内容:
- 生成可视化图表:根据分析和挖掘结果,生成适当的图表(如折线图、热力图、柱状图)。
- 报告生成:编写数据报告,解释分析结果和商业意义。
- 仪表盘展示:创建动态仪表盘,为实时监控和决策提供支持。
常用工具和方法:
- 工具:matplotlib、seaborn、Tableau、Power BI、Plotly。
- 方法:数据可视化、图表选型、报告自动生成。
主要工作内容:
- 数据产品开发:将分析结果和模型嵌入业务应用中,为业务流程提供支持。
- 决策支持:为管理层提供基于数据的决策支持工具或系统。
- 自动化决策系统:使用实时数据流和模型,支持业务流程自动化和实时决策。
常用工具和方法:
- 工具:Dash、Streamlit、Power BI、Kafka。
- 方法:实时分析与决策、嵌入式数据应用、智能决策支持。
主要工作内容:
- 数据质量监控:持续监控数据质量,及时检测异常和问题。
- 数据更新与维护:确保数据的时效性和一致性,进行定期更新。
- 数据安全与隐私保护:对敏感数据加密,管理权限,并确保合规性。
常用工具和方法:
- 工具:Apache Kafka、Airflow、Datadog、加密工具。
- 方法:数据加密与解密、权限控制、日志记录和数据审计。
主要工作内容:
- 数据归档:将过时但可能仍有用的数据归档存储,以便后续参考或合规审查。
- 数据删除:根据数据生命周期策略,对过期数据进行清理或永久删除,避免存储浪费和隐私风险。
常用工具和方法:
- 工具:数据库归档工具、分布式存储系统。
- 方法:数据生命周期管理、归档存储、数据清理策略。
这一完整的数据生命周期管理流程可以帮助确保数据从生成到应用都在最佳状态下被处理和利用,为业务的智能化决策提供可靠的数据支撑。
-
数据库是一个以某种有组织的方式存储的数据集合。数据库 (database) 是保存有组织的数据的容器。
-
数据库管理系统 (DBMS) 是一种数据库软件,MySQL 是一种 DBMS,即它是一种数据库软件,作者使用的数据库管理系统是 MySQL,除做特别说明外,作者使用的所有数据库软件都为 MySQL。

-
表(table) 某种特定类型数据的结构化清单,是一种结构化的文件,可用来存储某种特定类型的数据。
-
模式/架构(schema) 关于数据库和表的布局及特性的信息。

-
数据库中存储的表结构类似于 Excel 中的行和列,在数据库中,行称为记录,它相当于一条记录,列称为字段,它代表了表中存储的数据项目。
-
行和列交汇的地方称为单元格,一个单元格中只能输入一条记录。

-
主键 (primary key) 一列(或一组列),其值能够唯一标识表中每一行。表中的任何列都可以作为主键,只要它满足以下条件:
- 任意两行都不具有相同的主键值;
- 每一行都必须具有一个主键值(主键列不允许 NULL 值);
- 主键列中的值不允许修改或更新;
- 主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)

SQL 是结构化查询语言 (Structured Query Language) 的缩写。
SQL 是为操作数据库而开发的语言。
虽然是一种语言,但是 SQL 不像 Python,C 语言这种可以编译运行的语言;SQL 编写完成后可以仅仅保存在文本文件中,而且离开数据库和数据库操作界面, 它什么都做不了。
国际标准化组织(ISO)为 SQL 制定了相应的标准,以此为基准的 SQL 称为标准 SQL(相关信息请参考专栏——标准 SQL 和特定的 SQL)。
历史: 关系型数据库模型在 1960 年由 Edgar Codd 提出。 IBM 公司首个开发了 SQL 数据库系统。 SQL 于 1987 年成为国际标准组织(ISO)的标准。 SQL 于 1986 年成为 ANSI(美国国家标准协会) 的标准
SQL 语句的优点
- SQL 不是某个特定数据库供应商专有的语言。几乎所有重要的 DBMS 都支持 SQL,所以,学习此语言使你几乎能与所有数据库打交道;
- SQL 简单易学。它的语句全都是由描述性很强的英语单词组成,而且这些单词的数目不多;可以参考这个文档
- SQL 尽管看上去很简单,但它实际上是一种强有力的语言,灵活使用其语言元素,可以进行非常复杂和高级的数据库操作。
完全基于标准 SQL 的 RDBMS 很少,通常需要根据不同的 RDBMS 来编写特定的 SQL 语句,原则上,本课程介绍的是标准 SQL 的书写方式。
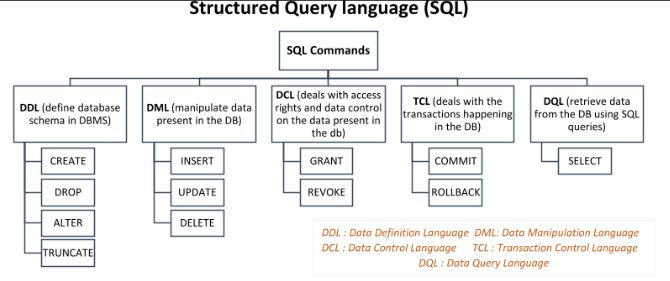
根据对 RDBMS 赋予的指令种类的不同,SQL 语句可以分为以下三类。
-
DDL(Data Definition Language,数据定义语言) 用来创建或者删除存储数据用的数据库以及数据库中的表等对象。
DDL 包含以下几种指令。
- CREATE : 创建数据库和表等对象
- DROP : 删除数据库和表等对象
- ALTER : 修改数据库和表等对象的结构
-
DML(Data Manipulation Language,数据操纵语言) 用来变更表中的记录。
DML 包含以下几种指令。
- INSERT :向表中插入新数据
- UPDATE :更新表中的数据
- DELETE :删除表中的数据
-
DCL(Data Control Language,数据控制语言) 用来确认或者取消对数据库中的数据进行的变更。除此之外,还可以对 RDBMS 的用户是否有权限操作数据库中的对象(数据库表等)进行设定。
DCL 包含以下几种指令。
- COMMIT : 确认对数据库中的数据进行的变更
- ROLLBACK : 取消对数据库中的数据进行的变更
- GRANT : 赋予用户操作权限
- REVOKE : 取消用户的操作权限
-
DQL(Data Query Language)数据库查询语言
DQL 多用于查询数据库,可以理解为使用 SQL 代码的方式向数据库进行提问。 SQL 查询可以短至 1 行,也可以数十行。SQL 查询可以访问单个表或视图,也可以使用联接(JOIN)将来自多个表的数据进行组合。
实际使用的 SQL 语句当中有 90% 属于 DQL,本课程会以 DQL 为中心进行讲解。(某些教材中,也经常将 DQL 归到 DML 中)
SQL 可以用来进行数据分析的主要原因:1. 数据放在数据库中;2. SQL 最终运行在服务器上的数据库中.
- 可以高效的使用服务器的计算资源,而不必担心本地的环境和计算能力。
- SQL 是于数据库交互和从中检索数据的实际标准。其他的一些语言或者工具,例如,Python、R 或者 BI 工具,都可以通过 SQL 与数据库中的数据进行交互。
- SQL 的纯文本开发方式,可以非常方便的迭代。
- SQL 的语法简单,可以快速学习;而且内置了很多的函数,从转换数据到执行复杂的计算。
决定是使用 SQL 还是 Python 来进行数据分析的时候,可以考虑下面的区别:
- 数据位于何处,在数据库中、在文件中、在网站的日志中、是网站的内容?
- 数据量有多大?
- 数据将会用在哪些地方,报告、可视化、还是统计分析?
- 是否需要使用新数据进行更新或刷新?更新的频率是多少?
- 你的团队正在使用什么?切换成本高吗?遵守现在有标准有多重要?
Python 或者 R 都具有复杂的统计函数功能,这些函数是内置的或者是有一些补充包来完成。尽管 SQL 也有计算平均值和标准差这类功能的函数,但是类似于 P 值 和统计显著性这些需要实验分析的计算不能用 SQL 来独立完成。SQL 也本身无法实现机器学习这样的功能。
数据类型 (datatype) 所容许的数据的类型。每个表列都有相应的数据类型,它限制(或容许) 该列中存储的数据,常见的数据类型有字符串、数值、日期和时间、二进制数据类型。

- 字符串数据类型
| 数据类型 | 说明 |
|---|---|
| CHAR | 1~255 个字符的定长串。它的长度必须在创建时指定,否则 MySQL 假定为 CHAR(1) |
| ENUM | 接受最多 64K 个串组成的一个预定义集合的某个串 |
| LONGTEXT | 与TEXT相同,但最大长度为 4 GB |
| MEDIUMTEXT | 与TEXT相同,但最大长度为 16K |
| SET | 接受最多 64 个串组成的一个预定义集合的零个或多个串 |
| TEXT | 最大长度为 64K 的变长文本 |
| TINYTEXT | 与TEXT相同,但最大长度为 255 字节 |
| VARCHAR | 长度可变,最多不超过 255 字节。如果在创建时指定为VARCHAR(n),则可存储 0 到 n 个字符的变长串(其中n≤255) |
- 数值数据类型
| 数据类型 | 说明 |
|---|---|
| BIT | 位字段,1~64位。(在MySQL5之前,BIT在功能上等价于 TINYINT) |
| BIGINT | 整数值,支持 -9223372036854775808~9223372036854775807(如果是UNSIGNED,为0~18446744073709551615)的数 |
| BOOLEAN(或BOOL) | 布尔标志,或者为0或者为1,主要用于开/关(on/off)标志 |
| DECIMAL(或DEC) | 精度可变的浮点值 |
| DOUBLE | 双精度浮点值 |
| FLOAT | 单精度浮点值 |
| INT(或INTEGER) | 整数值,支持-2147483648~2147483647(如果是UNSIGNED,为0~4294967295)的数 |
| MEDIUMINT | 整数值,支持-8388608~8388607(如果是UNSIGNED,为0~ 16777215)的数 |
| REAL | 4字节的浮点值 |
| SMALLINT | 整数值,支持-32768~32767(如果是UNSIGNED,为0~65535)的数 |
| TINYINT | 整数值,支持-128~127(如果为UNSIGNED,为0~255)的数 |
- 日期和时间数据类型
| 数据类型 | 说 明 |
|---|---|
| DATE | 表示1000-01-01~9999-12-31的日期,格式为 YYYY-MM-DD |
| DATETIME | DATE和TIME的组合 |
| TIMESTAMP | 功能和DATETIME相同(但范围较小) |
| TIME | 格式为HH:MM:SS |
| YEAR | 用2位数字表示,范围是70(1970年)~69(2069年),用4位数字表示,范围是1901年~2155年 |
- 二进制数据类型
| 数据类型 | 说 明 |
|---|---|
| BLOB | Blob最大长度为64KB |
| MEDIUMBLOB | Blob最大长度为16MB |
| LONGBLOB | Blob最大长度为4 GB |
| TINYBLOB | Blob最大长度为255字节 |
-
SQL 语句要以分号 ; 结尾
-
SQL 不区分关键字的大小写,但是插入到表中的数据是区分大小写的
-
Windows 系统默认不区分表名及字段名的大小写
-
Linux / Mac 默认严格区分表名及字段名的大小写(其实有的时候也不区分,但是最好是按照一定的规则来书写)
-
本教程已统一调整表名及字段名的为小写,以方便初学者学习使用。
-
常数的书写方式是固定的
'abc', 1234, '26 Jan 2010', '10/01/26', '2010-01-26'…
-
单词需要用半角空格或者换行来分隔
SQL 语句的单词之间需使用半角空格或换行符来进行分隔,且不能使用全角空格作为单词的分隔符,否则会发生错误,出现无法预期的结果。
请大家认真查阅《附录 1 - SQL 语法规范》,养成规范的书写习惯。
语法:
CREATE DATABASE < 数据库名称 > ;创建本课程使用的数据库
CREATE DATABASE shop;选择使用新创建的数据库
use shop;一种更为专业和工程的做法:
设置数据库编码
CREATE DATABASE dbname DEFAULT CHARSET utf8 COLLATE utf8_general_ci;设置数据表编码
CREATE TABLE 'author' (
'authorid' char(20) NOT NULL,
'name' char(20) NOT NULL,
'age' char(20) NOT NULL,
'country' char(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;请仔细对比上面的语句和下面的语句的区别!!!
CREATE TABLE `author` (
`authorid` char(20) NOT NULL,
`name` char(20) NOT NULL,
`age` char(20) NOT NULL,
`country` char(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;MySQL 中两种数据库引擎
- ENGINE = MyISAM
- ENGINE = InnoDB
虽然 MySQL 里的存储引擎不只是 MyISAM 与 InnoDB 这两个,但常用的就是它俩了。
下面我们分别来看两种存储引擎的区别。
- 一、InnoDB 支持事务,MyISAM 不支持,这一点是非常之重要。事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而 MyISAM 就不可以了。
- 二、MyISAM 适合查询以及插入为主的应用,InnoDB 适合频繁修改以及涉及到安全性较高的应用
- 三、InnoDB 支持外键,MyISAM 不支持
- 四、MySQL 在 5.1 之前版本默认存储引擎是 MyISAM,5.1 之后版本默认存储引擎是 InnoDB
- 五、InnoDB 不支持 FULLTEXT 类型的索引
- 六、InnoDB 中不保存表的行数,如
select count(*) from table时,InnoDB 需要扫描一遍整个表来计算有多少行,但是 MyISAM 只要简单的读出保存好的行数即可。注意的是,当 count(*)语句包含 where 条件时 MyISAM 也需要扫描整个表 - 七、对于自增长的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM 表中可以和其他字段一起建立联合索引
- 八、清空整个表时,InnoDB 是一行一行的删除,效率非常慢。MyISAM 则会重建表
- 九、InnoDB 支持行锁(某些情况下还是锁整表,如
update table set a=1 where user like '%lee%')
语法:
CREATE TABLE < 表名 >(
< 列名 1> < 数据类型 > < 该列所需约束 > ,
< 列名 2> < 数据类型 > < 该列所需约束 > ,
< 列名 3> < 数据类型 > < 该列所需约束 > ,
< 列名 4> < 数据类型 > < 该列所需约束 > ,
.
.
.
< 该表的约束 1> , < 该表的约束 2> ,……);创建本课程用到的商品表
CREATE TABLE product(
product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER,
purchase_price INTEGER,
regist_date DATE,
PRIMARY KEY(product_id)
);- 只能使用半角英文字母、数字、下划线(_)作为数据库、表和列的名称
- 名称必须以半角英文字母开头
商品表和 product 表列名的对应关系
| 商品表中的列名 | Product表定义的列名 |
|---|---|
| 商品编号 | product_id |
| 商品名称 | product_name |
| 商品种类 | product_type |
| 销售单价 | sale_price |
| 进货单价 | purchase_price |
| 登记日期 | regist_date |
数据库创建的表,所有的列都必须指定数据类型,每一列都不能存储与该列数据类型不符的数据。
五种最基本的数据类型
-
INTEGER 型
用来指定存储整数的列的数据类型(数字型),不能存储小数。
-
CHAR 型
用来存储定长字符串,当列中存储的字符串长度达不到最大长度的时候,使用半角空格进行补足,由于会浪费存储空间,所以一般不使用。
-
VARCHAR 型
用来存储可变长度字符串,定长字符串在字符数未达到最大长度时会用半角空格补足,但可变长字符串不同,即使字符数未达到最大长度,也不会用半角空格补足。
-
DATE 型
用来指定存储日期(年月日)的列的数据类型(日期型)。
-
FLOAT
浮点小数。
约束是除了数据类型之外,对列中存储的数据进行限制或者追加条件的功能。
NOT NULL 是非空约束,即该列必须输入数据。
PRIMARY KEY 是主键约束,代表该列是唯一值,可以通过该列取出特定的行的数据。

DROP TABLE < 表名 > ;删除 product 表
DROP TABLE product;- 添加列的 ALTER TABLE 语句
ALTER TABLE < 表名 > ADD COLUMN < 列的定义 >;添加一列可以存储 100 位的可变长字符串的 product_name_pinyin 列
ALTER TABLE product ADD COLUMN product_name_pinyin VARCHAR(100);- 删除列的 ALTER TABLE 语句
ALTER TABLE < 表名 > DROP COLUMN < 列名 >;删除 product_name_pinyin 列
ALTER TABLE product DROP COLUMN product_name_pinyin;ALTER TABLE 语句和 DROP TABLE 语句一样,执行之后无法恢复。误添的列可以通过 ALTER TABLE 语句删除,或者将表全部删除之后重新再创建。
TRUNCATE TABLE TABLE_NAME;优点:相比 drop/delete,truncate 用来清除数据时,速度最快。
基本语法:
UPDATE < 表名 >
SET < 列名 > = < 表达式 > [, < 列名 2>=< 表达式 2>...]
WHERE < 条件 > -- 可选,非常重要。
ORDER BY 子句 -- 可选
LIMIT 子句 -- 可选使用 UPDATE 时要注意添加 WHERE 条件,否则将会将所有的行按照语句修改
-- 修改所有的注册时间
UPDATE product
SET regist_date = '2009-10-10';
-- 仅修改部分商品的单价
UPDATE product
SET sale_price = sale_price * 10
WHERE product_type = '厨房用具';使用 UPDATE 也可以将列更新为 NULL(该更新俗称为 NULL 清空)。此时只需要将赋值表达式右边的值直接写为 NULL 即可。
-- 将商品编号为 0008 的数据(圆珠笔)的登记日期更新为 NULL
UPDATE product
SET regist_date = NULL
WHERE product_id = '0008'; 和 INSERT 语句一样,UPDATE 语句也可以将 NULL 作为一个值来使用。但是,只有未设置 NOT NULL 约束和主键约束的列才可以清空为 NULL。 如果将设置了上述约束的列更新为 NULL,就会出错,这点与 INSERT 语句相同。
- 多列更新
UPDATE 语句的 SET 子句支持同时将多个列作为更新对象。
-- 基础写法,一条 UPDATE 语句只更新一列
UPDATE product
SET sale_price = sale_price * 10
WHERE product_type = '厨房用具';
UPDATE product
SET purchase_price = purchase_price / 2
WHERE product_type = '厨房用具';该写法可以得到正确结果,但是代码较为繁琐。可以采用合并的方法来简化代码。
-- 合并后的写法
UPDATE product
SET sale_price = sale_price * 10,
purchase_price = purchase_price / 2
WHERE product_type = '厨房用具'; 需要明确的是,SET 子句中的列不仅可以是两列,还可以是三列或者更多。
为了学习 INSERT 语句用法,我们首先创建一个名为 productins 的表,建表语句如下:
CREATE TABLE productins(
product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER DEFAULT 0,
purchase_price INTEGER ,
regist_date DATE ,
PRIMARY KEY (product_id)
); 基本语法:
INSERT INTO < 表名 > (列 1, 列 2, 列 3, ……)
VALUES (值 1, 值 2, 值 3, ……); 对表进行全列 INSERT 时,可以省略表名后的列清单。 这时 VALUES 子句的值会默认按照从左到右的顺序赋给每一列。
-- 包含列清单
INSERT INTO productins (
product_id,
product_name,
product_type,
sale_price,
purchase_price,
regist_date)
VALUES (
'0005',
'高压锅',
'厨房用具',
6800,
5000,
'2009-01-15'
);
-- 省略列清单
INSERT INTO productins
VALUES (
'0005',
'高压锅',
'厨房用具',
6800,
5000,
'2009-01-15'
); 原则上,执行一次 INSERT 语句会插入一行数据。插入多行时,通常需要循环执行相应次数的 INSERT 语句。其实很多 RDBMS 都支持一次插入多行数据
-- 通常的 INSERT
INSERT INTO productins
VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO productins
VALUES ('0003', '运动 T 恤', '衣服', 4000, 2800, NULL);
INSERT INTO productins
VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
-- 多行 INSERT ( DB2、SQL、SQL Server、 PostgreSQL 和 MySQL 多行插入)
INSERT INTO productins
VALUES
('0002', '打孔器', '办公用品', 500, 320, '2009-09-11'),
('0003', '运动 T 恤', '衣服', 4000, 2800, NULL),
('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
-- Oracle 中的多行 INSERT
INSERT ALL INTO productins
VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11')
INTO productins
VALUES ('0003', '运动 T 恤', '衣服', 4000, 2800, NULL)
INTO productins
VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
SELECT * FROM DUAL;
-- DUAL 是 Oracle 特有(安装时的必选项)的一种临时表 A。
-- 因此“SELECT * FROM DUAL” 部分也只是临时性的,并没有实际意义。 INSERT 语句中想给某一列赋予 NULL 值时,可以直接在 VALUES 子句的值清单中写入 NULL。想要插入 NULL 的列一定不能设置 NOT NULL 约束。
INSERT INTO productins (
product_id,
product_name,
product_type,
sale_price,
purchase_price,
regist_date)
VALUES (
'0006',
'叉子',
'厨房用具',
500,
NULL,
'2009-09-20'
); 还可以向表中插入默认值(初始值)。
可以通过在创建表的 CREATE TABLE 语句中设置 DEFAULT 约束来设定默认值。
CREATE TABLE productins(
product_id CHAR(4) NOT NULL,
(略)
sale_price INTEGER
(略) DEFAULT 0, -- 销售单价的默认值设定为 0;
PRIMARY KEY (product_id)
); 可以使用 INSERT … SELECT 语句从其他表复制数据。
-- 将商品表中的数据复制到商品复制表中
INSERT INTO productcopy (
product_id,
product_name,
product_type,
sale_price,
purchase_price,
regist_date
)
SELECT
product_id,
product_name,
product_type,
sale_price,
purchase_price,
regist_date
FROM Product; 本课程用表插入数据 sql 如下:
- DML :插入数据
START TRANSACTION;
INSERT INTO product VALUES('0001', 'T 恤衫', '衣服', 1000, 500, '2009-09-20');
INSERT INTO product VALUES('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO product VALUES('0003', '运动 T 恤', '衣服', 4000, 2800, NULL);
INSERT INTO product VALUES('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
INSERT INTO product VALUES('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
INSERT INTO product VALUES('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');
INSERT INTO product VALUES('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');
INSERT INTO product VALUES('0008', '圆珠笔', '办公用品', 100, NULL, '2009-11-11');
COMMIT;

CREATE TABLE ai_test(
ai_id int not null AUTO_INCREMENT,
ai_unique varchar(20) not null,
PRIMARY KEY(ai_id),
CONSTRAINT ai_unique_ui UNIQUE (ai_unique)
)
INSERT INTO ai_test VALUES (0,'124');
INSERT INTO ai_test VALUES (0,'125');
INSERT INTO ai_test VALUES (0,'126');
INSERT INTO ai_test VALUES (0,'127');
INSERT INTO ai_test VALUES (0,'124');
INSERT INTO ai_test VALUES (0,'124');
INSERT INTO ai_test VALUES (0,'124');
INSERT INTO ai_test VALUES (0,'124');
INSERT INTO ai_test VALUES (0,'128');
CREATE TABLE students_new(
student_id int not null AUTO_INCREMENT,
student_name varchar(20) not null,
student_age int not null,
student_weight float not null DEFAULT 99.9,
PRIMARY KEY(student_id)
);INSERT INTO students_new(student_name,student_age) VALUES('王菲',19);
INSERT INTO students_new(student_id,student_name,student_age,student_weight) VALUES(5,'张玉婷',22,109.99);
INSERT INTO students_new(student_name,student_age) VALUES('丛老师',26);
INSERT INTO students_new VALUES(0,'杨小辉',3,42);

在整型类型中,有 signed 和 unsigned 属性,其表示的是整型的取值范围,默认为 signed
- signed: 带符号,数值可以是正负和零
- unsigned:不带符号,数值是大于等于 0
编写一条 CREATE TABLE 语句,用来创建一个包含表 1-A 中所列各项的表 Addressbook (地址簿),并为 regist_no (注册编号)列设置主键约束
表 1-A 表 Addressbook (地址簿)中的列
| 列的含义 | 列的名称 | 数据类型 | 约束 |
|---|---|---|---|
| 注册编号 | regist_no | 整数型 | 不能为NULL、主键 |
| 姓名 | name | 可变长字符串类型(长度为128) | 不能为NULL |
| 住址 | address | 可变长字符串类型(长度为256) | 不能为NULL |
| 电话号码 | tel_no | 定长字符串类型(长度为10) | |
| 邮箱地址 | mail_address | 定长字符串类型(长度为20) |
CREATE TABLE Addressbook(
regist_no INTEGER NOT NULL,
name VARCHAR(128) NOT NULL,
address VARCHAR(256) NOT NULL,
tel_no CHAR(10) ,
mail_address CHAR(20) ,
PRIMARY KEY (regist_no)
);假设在创建练习 1.1 中的 Addressbook 表时忘记添加如下一列 postal_code (邮政编码)了,请把此列添加到 Addressbook 表中。
列名 : postal_code
数据类型 :定长字符串类型(长度为 8)
约束 :不能为 NULL
-- [MySQL]
ALTER TABLE Addressbook ADD COLUMN postal_code CHAR(8) NOT NULL ;
-- [Oracle]
ALTER TABLE Addressbook ADD (postal_code CHAR(8)) NOT NULL;
-- [SQL Server]
ALTER TABLE Addressbook ADD postal_code CHAR(8) NOT NULL;
/*
[DB2] 无法添加。
在 DB2 中,如果要为添加的列设定 NOT NULL 约束,
需要像下面这样指定默认值,或者删除 NOT NULL 约束,
否则就无法添加新列。
*/
-- [DB2 修正版]
ALTER TABLE Addressbook ADD COLUMN postal_code CHAR(8) NOT NULL DEFAULT '0000-000';编写 SQL 语句来删除 Addressbook 表。
DROP TALBE Addressbook;编写 SQL 语句来恢复删除掉的 Addressbook 表。
删除后的表无法使用命令进行恢复(其实对 DBA 来说是可以的,这个超纲了),请使用习题 3.1 答案中的 CREATE TABLE 语句再次创建所需的表。