作者:chuangzhu
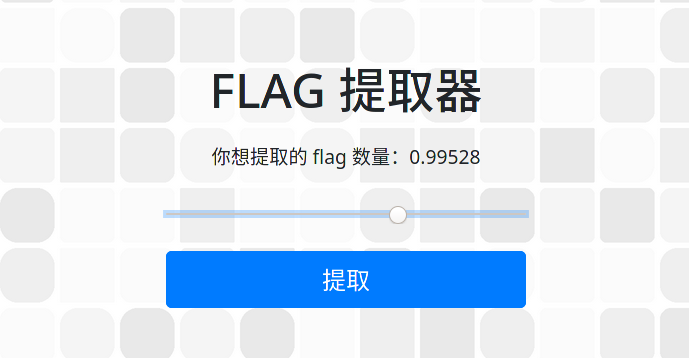
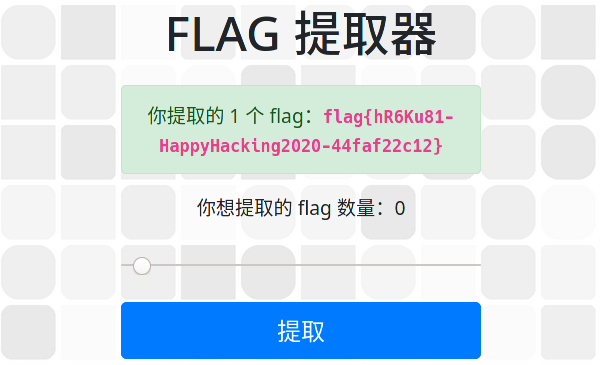
这是一个步长为 0.00001 的 range input,人类难以精确地将数值调成 1。解决方法是超越人类在 developer tools 中找到 <input id="number" class="form-control" type="range" name="number" value="0"... 元素,将 value 改为 1 然后点击提取。
该题主要考查选手对搜索引擎的熟练程度
哺乳动物: https://en.wikipedia.org/wiki/List_of_computing_mascots
- Docker(鲸鱼),Golang(地鼠),Python(蟒蛇),Plan 9(兔子),PHP(大象),GNU(牛),LLVM(龙),Swift(燕子),Perl(蝴蝶),GitHub(章鱼猫),TortoiseSVN(龟龟),FireFox(
苏卡卡狐狸),MySQL(海豚),PostgreSQL(大象),MariaDB(海狮),Linux(企鹅),OpenBSD(河豚),FreeDOS(鱼),Apache Tomcat(猫?老虎?),Squid(鱿鱼),openSUSE(大蜥蜴),Kali(龙),Xfce(老鼠). - 很贴心地提示了龙不是哺乳动物,
所以说章鱼猫究竟是章鱼还是猫呢
信鸽: https://tools.ietf.org/html/rfc1149 比这个标准本身更好玩的是真的有人在现实中实现过
开源游戏: https://lug.ustc.edu.cn/oldwiki/lug/events/sfd
停车位:

第六届 flag 数: https://news.ustclug.org/2019/12/hackergame-2019/
当你在 pull 一个 image 时,Docker 会显示很多哈希码:
➜ sudo docker pull archlinux
Using default tag: latest
latest: Pulling from library/archlinux
4d6a3daaa4e1: Extracting [==> ] 6.128MB/148.2MB
92b65ac2377d: Download complete
5d5a7d9d2712: Download complete
05aae39893a7: Download complete
74d01483340c: Download complete这些哈希码代表的其实就是 Docker 的 layers。你在 Dockerfile 中写的每一个 Docker 命令都会产生一个层,每层都相当于是一个 diff,所有 diff 拼在一起就变成了一个 image。这意味着写 Dockerfile 时应尽量避免一条 shell 命令使用一个 RUN,而是应该使用 &&, ||, ; 将多行 shell 命令连接起来;如果一条命令引入了缓存应该在这条命令同行进行清除,这样才能保证 build 出的 image 不过于臃肿。当然,这也意味这我们的 233 同学不能通过另一条 RUN 藏住自己宝贵的 flag :)
Docker 可以通过 docker inspect 和 docker history 查看一个 image 的层,这个我是知道的。但至于怎么导出某个 layer 的文件,我搜了半天 docker export 都没找到答案。最后还是朋友随手一搜帮我找到的——啊,原来那个命令是 docker save...
我记得 MS Excel 是有人民币大小写转换的功能的......不过我已经很久没用过 MS Excel 了......Libre Office 也应该是有的不过懒得研究了。保存为 csv 然后用 Python 处理下“元”、“角”、“分”、“整”这些字符,用 cn2an 库转化一下并求和。代码放 Gist 了。
Python 输出程序自身的题目有一个很经典的解法:
a='a=%r;print(a%%a)';print(a%a)但是这题要求反向输出:
a='a=%r;print("".join(reversed(a%%a)))';print("".join(reversed(a%a)))然后进入控制台粘贴代码,发现它会把输出中的 \n 也包含进去:
Your code is:
'a=\'a=%r;print("".join(reversed(a%%a)))\';print("".join(reversed(a%a)))'
Output of your code is:
')))a%a(desrever(nioj.""(tnirp;\')))a%%a(desrever(nioj.""(tnirp;r%=a\'=a\n'
Checking reversed(code) == output
Failed!那么我们通过 print 的 end 参数让输出不换行就好了:
a='a=%r;print("".join(reversed(a%%a)),end="")';print("".join(reversed(a%a)),end="")这是 Python hashlib 的用法:
import hashlib
h = hashlib.sha256(b'foo bar baz')
h.hexdigest()那么就和上面一样:
a='a=%r;import hashlib;print(hashlib.sha256((a%%a).encode()).hexdigest(),end="")';import hashlib;print(hashlib.sha256((a%a).encode()).hexdigest(),end="")能解出这题完全归功于我之前在前端群里看到的另外一题:
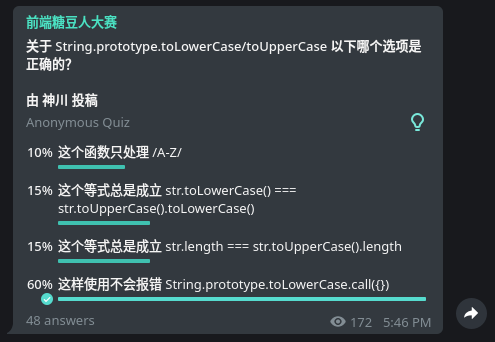
这题让我知道了有大写的绝不只是 /a-z/ 而已,很多 Unicode 字符也有大小写变换的。甚至一些 Unicode 字符的大写是 ASCII 字符。比如著名的德文字符 ß:
>>> 'ß'.upper()
'SS'这就是解题的关键了。但至于怎么找出这个对应于 'FLAG' 的字符,我并没有立即想到什么办法。直到次日吃早餐时,才突然有了头绪:
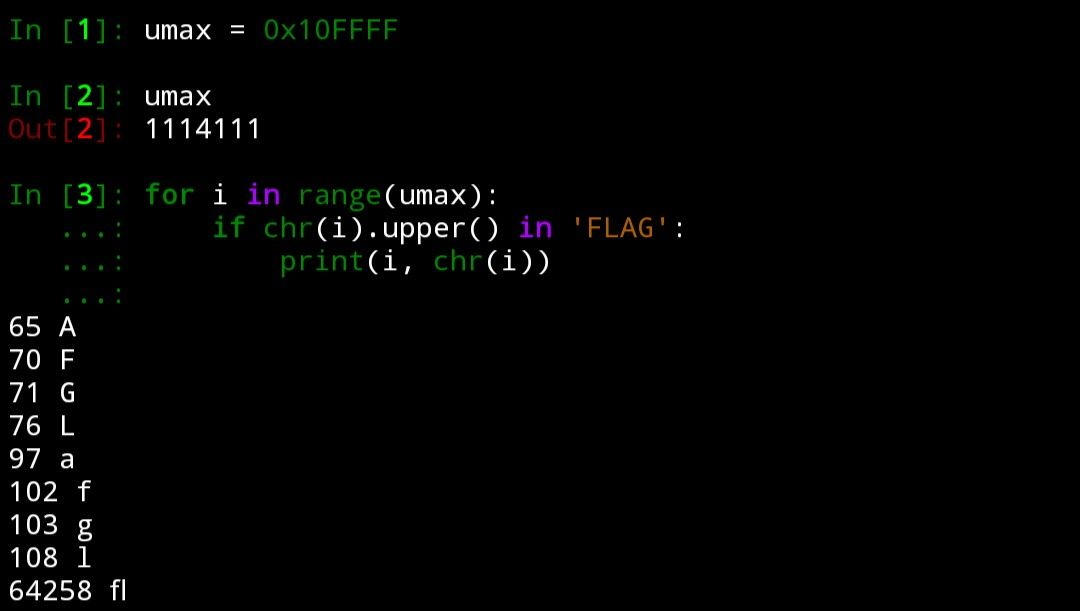
就是这个字符 fl,它的 Unicode 码点是 64258,对应的大写是两个拉丁字母 FL。令我比较意外的是居然真的有这么一个字符~~,话说它被发明出来就是专门用来迫害程序员的吗~~。
第一次知道还有 UTF-7 这种东西。UTF-8 靠最高位来判断一个字节是一个 ASCII 字符还是是一个 Unicode 字符的一部分。而 UTF-7 只有 7 位,它是怎么编码 ASCII 以外的字符的呢?Wikipedia 上有很直观的解释:https://en.wikipedia.org/wiki/UTF-7
一个非 ASCII 的字符使用多个 base64 的 6 位的字符表示,使用 +- 包裹,不足 6 位的尾巴用 0 补上。此外 ASCII 字符其实可以用这套方法,这样就可以躲开正则的匹配了:
+------+---------------------------------------------------------------+
| char | 'f' |
+------+---------------+---------------+---------------+---------------+
| hex | 0 | 0 | 6 | 6 |
+------+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+-- +
| bin | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
+------+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| b64 | A | G | Y |
+------+-----------------------+-----------------------+-----------------------+
构造字符串 +AGY-lag。
In [63]: re.match('[Ff][Ll][Aa][Gg]', '+AGY-lag')
In [64]: '+AGY-lag'.encode().decode('utf-7')
Out[64]: 'flag'这题我有点碰运气的成分,所幸题目并不复杂。题目说是 GBK,那先试试储存为 GBK 然后以 UTF-8 打开:
In [323]: s = '''脦脪鹿楼脝脝脕脣 拢脠拢谩拢茫拢毛拢氓拢貌拢莽拢谩拢铆拢氓 碌脛路镁脦帽脝梅拢卢脥碌碌陆脕脣脣眉脙脟碌脛 拢忙拢矛拢谩拢莽拢卢脧脰脭脷脦脪掳脩 拢忙拢
...: 矛拢谩拢莽 路垄赂酶脛茫拢潞
...: 拢忙拢矛拢谩拢莽拢没拢脠拢麓拢枚拢鲁拢脽拢脝拢玫拢脦拢脽拢梅拢卤拢脭拢猫拢脽拢鲁拢卯拢茫拢掳拢盲拢卤拢卯拢莽拢脽拢麓拢脦拢盲拢脽拢盲拢鲁拢茫拢掳拢脛拢卤
...: 拢卯拢脟拢脽拢鹿拢帽拢脛拢虏拢脪拢赂拢猫拢贸拢媒
...: 驴矛脠楼卤脠脠眉脝陆脤篓脤谩陆禄掳脡拢隆
...: 虏禄脪陋脭脵掳脩脮芒路脻脨脜脧垄脳陋路垄赂酶脝盲脣没脠脣脕脣拢卢脪陋脢脟卤禄路垄脧脰戮脥脭茫赂芒脕脣拢隆'''
In [334]: s.encode('gbk').decode()
Out[334]: 'ÎÒ¹¥ÆÆÁË £È£á£ã£ë£å£ò£ç£á£í£å µÄ·þÎñÆ÷£¬Íµµ½ÁËËüÃÇµÄ £æ£ì£á£ç£¬ÏÖÔÚÎÒ°Ñ £æ£ì£á£ç ·¢¸øÄ㣺\n£æ£ì£á£ç£û£È£´£ö£³£ß£Æ£õ£Î£ß£÷£±£Ô£è£ß£³£î£ã£°£ä£±£î£ç£ß£´£Î£ä£ß£ä£³£ã£°£Ä£±£î£Ç£ß£¹£ñ£Ä£²£Ò£¸£è£ó£ý\n¿ìÈ¥±ÈÈüƽ̨Ìá½»°É£¡\n²»ÒªÔÙ°ÑÕâ·ÝÐÅϢת·¢¸øÆäËûÈËÁË£¬ÒªÊDZ»·¢ÏÖ¾ÍÔã¸âÁË£¡'哦,有点眼熟了。搬出之前群友发过的那张图:
In [340]: s.encode('gbk').decode().encode('iso8859-1').decode('gbk')
Out[340]: '我攻破了 Hackergame 的服务器,偷到了它们的 flag,现在我把 flag 发给你:\nflag{H4v3_FuN_w1Th_3nc0d1ng_4Nd_d3c0D1nG_9qD2R8hs}\n快去比赛平台提交吧!\n不要再把这份信息转发给其他人了,要是被发现就糟糕了!'
sympy 有个实验性的功能叫 parse_latex:
In [1]: from sympy.parsing.latex import parse_latex
In [2]: parse_latex('\int_2^3 \ln(x^2)')
Out[2]: Integral(log(x**2, E), (x, 2, 3))页面中的 LaTeX 可以通过 r'<p>$(.+)</p>' 匹配。页面中的 LaTeX 中有 \left \right \, 这些仅用于指定格式的命令,parse_latex 无法识别,将他们替换为 ''。登录的话用 requests 创建一个 Session() get 登录地址就可了。
我是用随机解的,先实现一个康威生命游戏,然后随机生成左上 15*15 的矩阵。两百轮后检查两个方块的状态,被破坏则打印出矩阵。代码放 Gist 了。
ldd 本身只是个 shell 脚本,它是利用 ld-linux.so 的一个特性来检查动态链接库的,当 LD_TRACE_LOADED_OBJECTS 环境变量设为 1 时,ld-linux.so 就会输出动态链接的库。
比较旧的 ldd 会直接执行程序,如果程序使用的动态链接库加载器不响应 LD_TRACE_LOADED_OBJECTS 这个环境变量(如 ld-uClibc.so)则可以执行任意代码。但是这个后来改了,现在的 ldd 会调用 /bin/ld-linux.so 来检查动态链接库。要让现在的 ldd 执行任意代码,需要利用 CVE-2019-1010023,这是 POC:
https://sourceware.org/bugzilla/show_bug.cgi?id=22851
但是这个 POC 应该同时需要 libevil.so 和 main 两个文件才可以达成,试过强行同时上传两个文件没有效果,放弃。
题目提示是用很旧的框架升级上来的,打开网页发现认证用的 JWT。而旧版本的一些 JWT 库可能会有这两个 exploit:
https://auth0.com/blog/critical-vulnerabilities-in-json-web-token-libraries/
一个是在 JWT 的头中指定 none 算法,这样签名部分就可以为空,实测该题不能利用。另一个是一些 JWT 库会根据 JWT 头来选择验证时使用的算法。如果将头中的非对称的 RS256 算法换为对称的 HS256 算法,它会把 RSA 的公钥当作 HMAC 的密钥来验证签名。然而我找了半天都没找到公钥,遂放弃。
这题我做得真是障碍重重。首先尝试我系统上现有的工具,基本上都提示 URL/端口有误。然后尝试编译一些远古的工具,成功运行后还是连不上。Stack Overflow 看了一圈发现好像是现在 Linux 内核不允许。再后面我甚至拿了一个 ESP8266 单片机来写 socket 请求,但还是请求超时。看来是我的网络 route 了 0 端口的请求。
那是最后是怎么解决的呢?连上我的 Debian 10 服务器,wget http://202.38.93.111:0/ -O - 就能连上了。啊这......
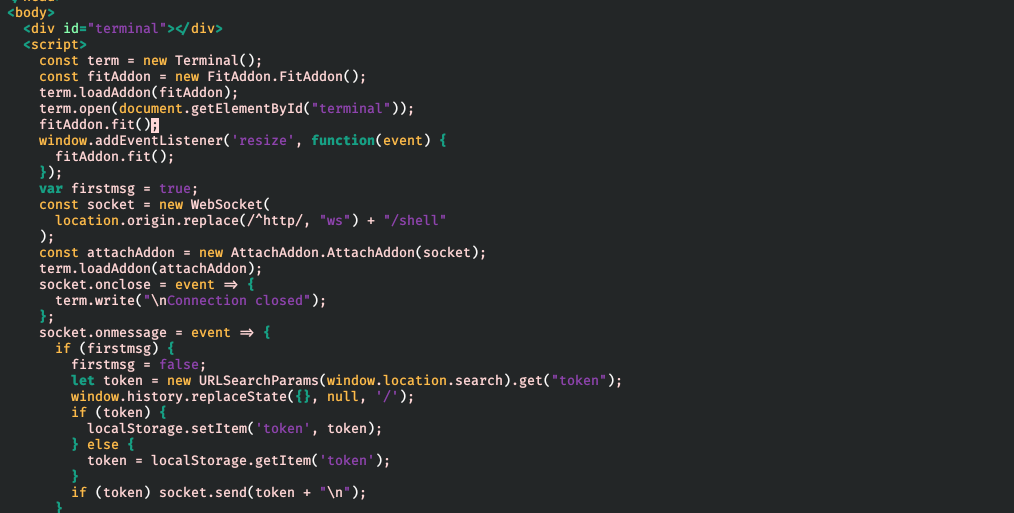
然后发现 wget 下载下来的东西是一个 HTML 文件,和很多其他题一样这个 HTML 是个终端模拟器,用命令行连的话应该用 nc 这种工具。然而 nc 是不允许访问 0 端口的。但从页面上可看出浏览器上访问时会连接 ws://202.38.93.111:0/shell,使用 websocat 这种工具连上输入自己的比赛 token 即可获得 flag。
~$ websocat ws://202.38.93.111:0/shell
Please input your token:
<TOKEN>
<TOKEN>
flag{TCP_P0RT_0_1s_re5erved_BUT_w0rks_1e3bd5c71e}这么恶臭的题有什么解的必要吗
这题和大家一般情况下玩的数字论证梗还是有一定区别的。使用搜索引擎搜索,你会发现这种代码遍地都是,但是它们基本上只有加减乘除,并且常常会允许 114514 重复出现。然而这题 1, 1, 4, 5, 1, 4 只能出现一次,但是加入了位运算。这题在传统数字论证的基础上加入了位运算,使得论证更具有普适性,揭示了万物恶臭的本质。
我采用了一种很蠢的暴力列举法,列举出出现在 1, 1, 4, 5, 1, 4 之间或者前后可能出现的一些符号,遍历他们的所有组合情况,然后拼在一起 eval。如果词典中没有,就把值和式子加入词典。
inner_op = ['', '+', '-', '*', '//', '%', '^', '&', '|',
'*-', '//-', '%-', '+~', '-~', '+~-', '*~', '%~',
'^-', '&-', '|-', '//~', '^~', '&~', '|~',
'+(', '-(', '*(', '%(', '^(', '&(', '|(', ')',
')+(', ')-(', ')*(', ')//(', ')%(', ')^(', ')&(', ')|(']
leading_op = ['', '-', '~', '-(', '~(', '(']
trailing_op = ['', ')']
values = {}
for i in leading_op:
for j in inner_op:
for k in inner_op:
for l in inner_op:
for m in inner_op:
for n in inner_op:
for o in trailing_op:
eq = ''.join([i, '1', j, '1', k, '4', l, '5', m, '1', n, '4', o])
try:
va = eval(eq)
if (0 < va < 114514) and (va not in values):
values[va] = eq
print(len(values), eq, end='\r')
except:
pass大约半个小时可跑完,获得键值对数:2070。~~这对于平日里的一些数字论证已经足够用了,~~然而题目一共有 32 道,要确保有足够的几率解出这题,按 10% 算,每道题就必须确保有 93% 的概率能答出,那么我们需要的键值对数就是 106,500 对,还远远不够。
这时候就需要拿出 -~ 和 ~- 运算符了。JavaScript 魔法师们对这个符号应该很熟悉,前者按位取反然后取反加一,相当于加一;后者取反加一然后取反,相当于减一。更棒的是这个符号还可以一直叠加,只要整个式子不超过题目限制的 256 字节即可。
import re
import copy
altv = copy.copy(values)
def get_more():
for numdt in range(255):
for eq in values.values():
equations = []
splitted = re.split('(\d+)', eq)
for non in range(1, len(splitted), 2):
temp = splitted.copy()
temp[non] = '~-'*numdt + temp[non]
equations.append(''.join(temp))
for eq in equations:
if len(eq) > 256:
continue
try:
va = eval(eq)
if (0 < va < 114514) and (va not in altv):
altv[va] = eq
print(len(altv), eq, end='\r')
except:
pass
get_more()
values = altv经过这番操作键值对数成功增殖到了 74698,离目标已经很近了。最后再对现有的每条式子整个进行加一减一操作,填补一下剩下的空隙。
altv = copy.copy(values)
def get_even_more():
for numdt in range(255):
for eq in values.values():
eq1 = '-~'*numdt + '(' + eq + ')'
eq2 = '~-'*numdt + '(' + eq + ')'
for eq in [eq1, eq2]:
if len(eq) > 256:
continue
try:
va = eval(eq)
if (0 < va < 114514) and (va not in altv):
altv[va] = eq
print(len(altv), eq, end='\r')
except:
pass
get_even_more()
values = altv最后得到了 114181 个键值对。完整代码见 Gist。不需要
这是一个 HTTP/2 的页面,HTTP/2 有一种叫做 server push 的东西,服务端可以在客户端没有请求时发送数据。目的是提前加载客户端接下来可能需要请求的内容,减小卡顿。Server push 目前在浏览器 devtools 中仍然是不可见的,你需要一个支持 HTTP/2 的抓包工具,比如 mitmproxy。打开 mitmproxy 的 mitmweb,因为题目提示了这题的证书无效,所以还要加个 --ssl-insecure 参数:
mitmweb --listen-port 4710 --ssl-insecure点击 mitmproxy > Install Certificate...,安装证书,配置浏览器的代理为 mitmproxy 监听的地址。重新打开这题,就可以在 mitmweb 中看到这个神奇的请求:
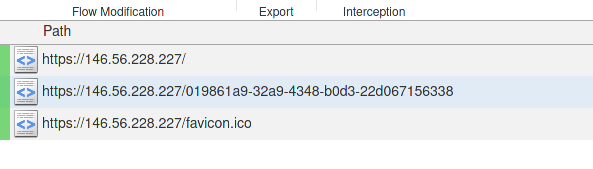
点开这个请求即可在 response 中看到第一个 flag。
北极,3020 年。很容易让人联想到 GitHub 在北极建的号称可以保存代码 1000 年的项目,GitHub Archive Program。解开压缩包是几百张二维码图片,使用 qtqr 打开其中一张,发现以下内容:
META 000644 000765 000024 00000012100 13745216231 011453 0 ustar 00tao staff 000000 000000 {
"id": 214089388,
"node_id": "MDEwOlJlcG9zaXRvcnkyMTQwODkzODg=",
"name": "nonexist",
"full_name": "openlug/nonexist",
"private": false,
"owner": {
"login": "openlug",
"id": 55339572,
"node_id": "MDQ6VXNlcjU1MzM5NTcy",
"avatar_url": "https://avatars0.githubusercontent.com/u/55339572?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/openlug",
"html_url": "https://github.com/openlug",
"followers_url": "https://api.github.com/users/openlug/followers",
"following_url": "https://api.github.com/users/openlug/following{/other_user}",
"gists_url": "https://api.github.com/users/openlug/gists{/gist_id}",
"starred_url": "https://api.github.com/users/openlug/starred{/owner}{/repo}",(由于 GitHub 网页无法正常渲染 \x00 字符,上方所有 \x00 已替换为空格)
看起来像是 GitHub API 的调用结果,至于开头的 META\x00\x00\x00\x00... 猜测是 tar 的文件格式。进一步的探索发现按字母表顺序,前一张二维码的内容可以与后一张拼接,遂确定了这些二维码是分块的 tar 文件。
一个比较有趣的发现是我一直信赖的 OpenCV 竟然无法识别这些大型二维码,所能做的只是标出二维码的框而已。为此我需要找一个更好用的二维码识别库,比如我找到了 zbar。需要注意的是 zbar 会自作聪明地将识别结果解码为 str。如果把这些字符串直接写入文件的话文件后面的一部分都无法读取。需要重新以 ISO8859-1 编码为 bytes,然后再以二进制模式写入。
import zbar
from PIL import Image
import os
import glob
def decode(filename):
scanner = zbar.ImageScanner()
scanner.parse_config('enable')
pil = Image.open(filename).convert('L')
width, height = pil.size
raw = pil.tobytes()
image = zbar.Image(width, height, 'Y800', raw)
result = scanner.scan(image)
if not result:
return None
return symbol[0].data
qrfiles = glob.glob('./frames/frame-*.png')
qrfiles.sort()
qrdata = [decode(fn) for fn in qrfiles]
qrencoded = [q.encode('ISO8859-1') for q in qrdata]
with open('frames.tar', 'wb') as f:
f.write(b''.join(qrencoded))tar xf frames.tar,获得 COMMITS、flag、META、repo.tar.xz 文件。解压 repo.tar.xz 即可获得 flag。还有一个 file_1MB,可能是彩蛋?
1000 元存一个账户里,一天下来利息就是 1000 * 0.3% = 3 元。然而如果将 1000 元分为 5 张,那么每张的利息为 200 * 0.3% = 0.6 ~= 1 元,狗狗银行的取整算法使得我们可以通过这种方式增加利息。最小的可获得 1 元利息的金额为 167 元,此时利息增加至 0.6%。
这题我一开始想复杂了,我不知道这里的信用卡也是可以向银行卡转账的,并且不限额度。一开始我还以外信用卡只能用来吃饭 _(:з」∠)_,所以我不管怎么改银行卡总利息都小于信用卡利息加饭钱。
以 x 有 167 元存款的借记卡卡数,为 y 为每日净利润,则有:
$$
y = \begin{cases}
x - 20, x < \frac{2000}{167}\
x - 167\times 0.005 x - 10, x \ge \frac{2000}{167}\
\end{cases}
$$
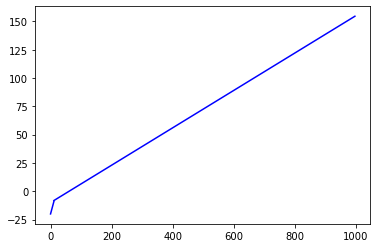
......可见卡越多日净利润越多,干脆申请 998 张借记卡,一张信用卡。每张借记卡从信用卡套现 167 元,这样每日都可净赚 164.505 元。用来还信用卡,还完后就开始赚钱了。后面我发现一直欠着账也行,系统算的是净资产,净资产大于 2000 时狗狗银行就会吐出 flag:
flag{W0W.So.R1ch.Much.Smart.52f2d579}
完整代码见 Gist,其实没多少逻辑方面的代码。