![]()
![]()
![]()
![]()
A Gold mine dataset for computer vision is the ImageNet dataset. It consists of about 14 M hand-labelled annotated images which contains over 22,000 day-to-day categories. Every year ImageNet competition is hosted in which the smaller version of this dataset (with 1000 categories) is used with an aim to accurately classify the images. Many winning solutions of the ImageNet Challenge have used state of the art convolutional neural network architectures to beat the best possible accuracy thresholds.
XceptionNet
VGG19
VGG16
ResNet50
inceptionv3
Fruits 360
Flowers Recognition
Libraries: NumPy pandas PIL seaborn keras
VGG16 was publised in 2014 and is one of the simplest (among the other cnn architectures used in Imagenet competition). It's Key Characteristics are:
-
This network contains total 16 layers in which weights and bias parameters are learnt.
-
A total of 13 convolutional layers are stacked one after the other and 3 dense layers for classification.
-
The number of filters in the convolution layers follow an increasing pattern (similar to decoder architecture of autoencoder).
-
The informative features are obtained by max pooling layers applied at different steps in the architecture.
-
The dense layers comprises of 4096, 4096, and 1000 nodes each.
-
The cons of this architecture are that it is slow to train and produces the model with very large size.
The VGG16 architecture is given below:

Keras library also provides the pre-trained model in which one can load the saved model weights, and use them for different purposes : transfer learning, image feature extraction, and object detection. We can load the model architecture given in the library, and then add all the weights to the respective layers.

from keras.applications.vgg16 import VGG16
vgg16_weights = '../input/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels.h5'
vgg16_model = VGG16(weights=vgg16_weights)
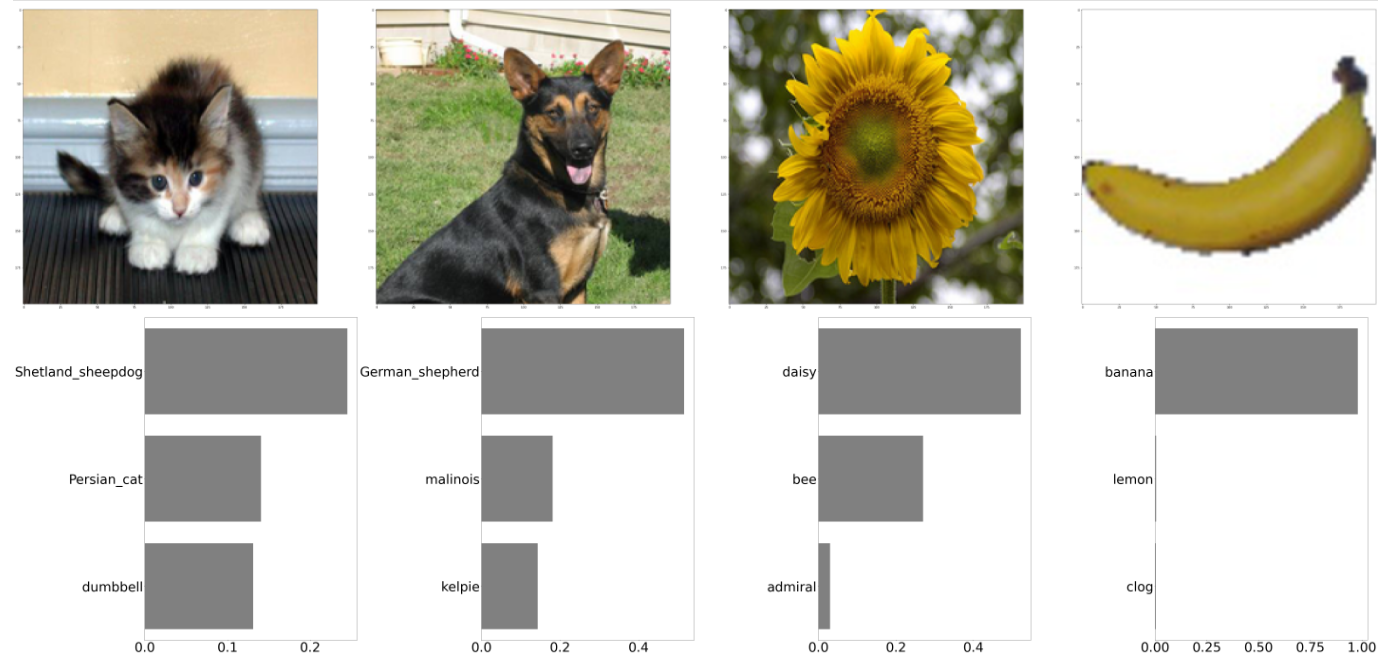
_get_predictions(vgg16_model)
VGG19 is a similar model architecure as VGG16 with three additional convolutional layers, it consists of a total of 16 Convolution layers and 3 dense layers. Following is the architecture of VGG19 model. In VGG networks, the use of 3 x 3 convolutions with stride 1 gives an effective receptive filed equivalent to 7 * 7. This means there are fewer parameters to train.

from keras.applications.vgg19 import VGG19
vgg19_weights = 'vgg19_weights_tf_dim_ordering_tf_kernels.h5'
vgg19_model = VGG19(weights=vgg19_weights)
_get_predictions(vgg19_model,0)

Also known as GoogleNet consists of total 22 layers and was the winning model of 2014 image net challenge.
- Inception modules are the fundamental block of InceptionNets. The key idea of inception module is to design good local network topology (network within a network)
- These modules or blocks acts as the multi-level feature extractor in which convolutions of different sizes are obtained to create a diversified feature map
- The inception modules also consists of 1 x 1 convolution blocks whose role is to perform dimentionaltiy reduction.
- By performing the 1x1 convolution, the inception block preserves the spatial dimentions but reduces the depth. So the overall network's dimentions are not increased exponentially.
- Apart from the regular output layer, this network also consists of two auxillary classification outputs which are used to inject gradients at lower layers.
The inception module is shown in the following figure:

from keras.applications.inception_v3 import InceptionV3
inception_weights = 'inception_v3_weights_tf_dim_ordering_tf_kernels.h5'
inception_model = InceptionV3(weights=inception_weights)
_get_predictions(inception_model,1)

from tensorflow.keras.applications.resnet50 import ResNet50
resnet_weights = 'resnet50_weights_tf_dim_ordering_tf_kernels.h5'
resnet_model = ResNet50(weights='imagenet')
_get_predictions(resnet_model,0)

Checkout complete implementation here
CNN architectures
Using pre-trained models
If you have any feedback, please reach out at [email protected]
I am an AI Enthusiast and Data science & ML practitioner
![]()
![]()
![]()
![]()